10 KiB
| title | updated | created | latitude | longitude | altitude |
|---|---|---|---|---|---|
| WK1 Big Data and Machine Learning Fundamentals | 2021-09-11 16:36:12Z | 2021-09-07 18:38:10Z | 52.09370000 | 6.72510000 | 0.0000 |
07/09/2021 20:38
Migrating workloads to the cloud
as an example an Apache Hadoop, Spark platform and MySQL database
An migration needs to ad value

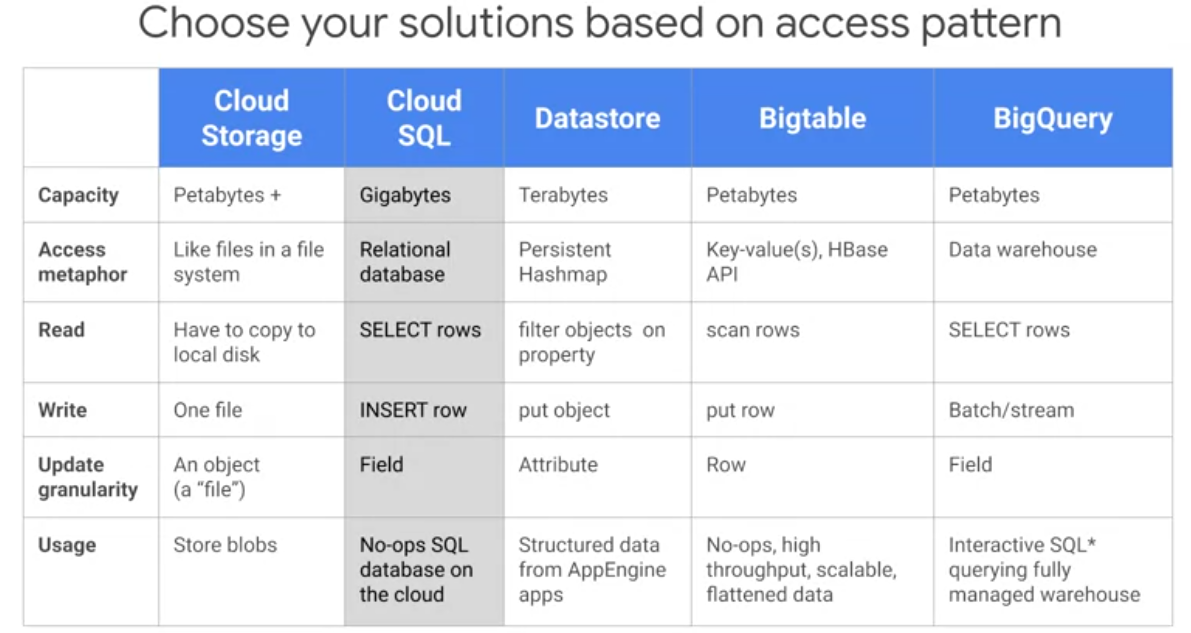
Reference of choosing the right storage access platform
Dataproc is a fully managed and highly scalable service for running Apache Spark, Apache Flink, Presto, and 30+ open source tools and frameworks.
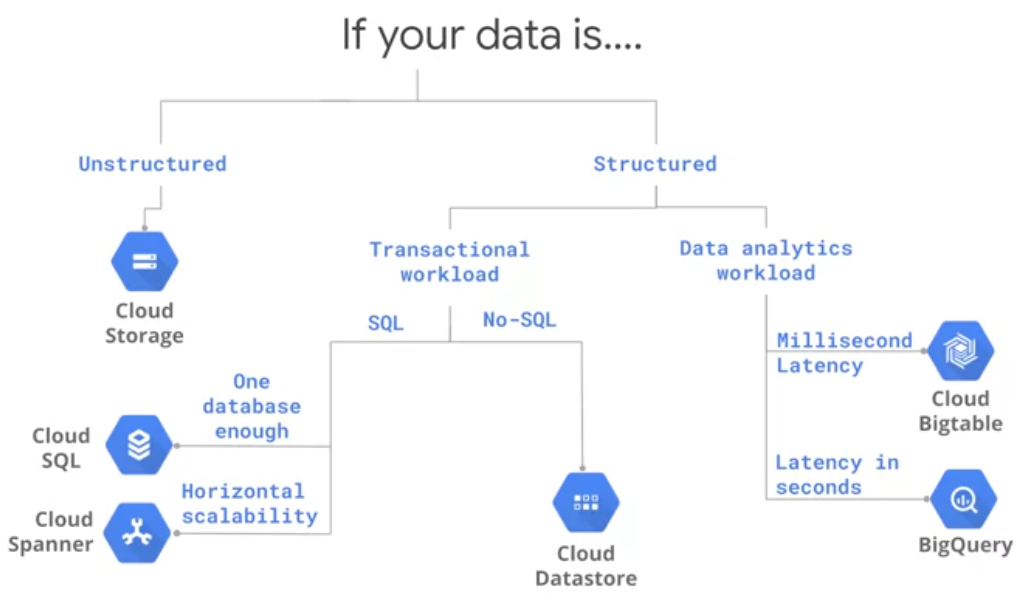
- Cloud Storage as a global file system Data is unstructured.
- Cloud SQL as an RDBMS Data is structured and transactions.
Cloud SQL generally plateaus out at a few gigabytes One database
Fully managed relational database service for MySQL, PostgreSQL, and SQL Server. Advantages:
- Familiar
- Flexible pricing
- Managed backups
- Connect from anywhere
- Automatic replication
- Fast connection from GCE (Google Compute Engine) & GAE (Google App Engine)
- Google security
- Cloud Datastore as a transactional No-SQL object-oriented database. Key-Value pair.
- Cloud BigTable for high-throughput No-SQL append-only data. No transactions. A typical use case for Bigtable is sensor data for connected devices eg.
- Cloud BigQuery as a SQL data warehouse to power all your analytics needs
- Cloud Spanner transactional database that is horizontally scalable so that you can deal with data larger than a few gigabytes, or if you need multiple databases across different continents.
Selection of storage in a visual way
Challenge: Utilizing and tuning on-premise clusters
One of the most common challenges from managing on premise Hadoop clusters is making sure they're efficiently utilized and tooled properly for all the workloads that their users throw at them The problem here lies in the static nature of the on premise cluster capacity
GCP think of clusters as flexible resources Turn down clusters automaticly with scheduled deletion:
- idle time (minimum 10 minutes)
- timstamp (eq maximum x days)
- duration (granularity 1 second)
- shutdown when a job is finished
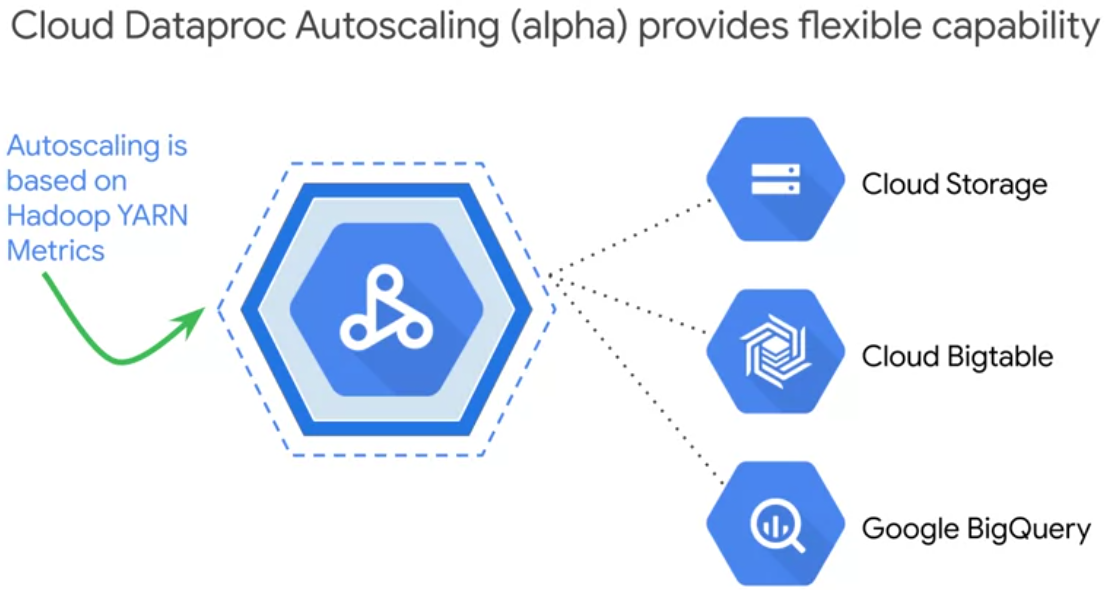 And you can use auto scaling as long as when you shut down the clusters node, it doesn't remove any data. So, you cannot store the data on the cluster, but that's why we store our data on Cloud Storage, or BigTable, or BigQuery, we store our data off cluster. So, autoscaling works as long as you don't store your data in HDFS
And you can use auto scaling as long as when you shut down the clusters node, it doesn't remove any data. So, you cannot store the data on the cluster, but that's why we store our data on Cloud Storage, or BigTable, or BigQuery, we store our data off cluster. So, autoscaling works as long as you don't store your data in HDFS
 In addition to auto scaling, another advantage of running Hadoop clusters and GCP is that you can incorporate preemptible virtual machines into your cluster architecture.Preemptible VMs are highly affordable, shortlived compute instances that are suitable for batch jobs and fault tolerant workloads.
In addition to auto scaling, another advantage of running Hadoop clusters and GCP is that you can incorporate preemptible virtual machines into your cluster architecture.Preemptible VMs are highly affordable, shortlived compute instances that are suitable for batch jobs and fault tolerant workloads.
Why fault tolerant?
Because preemptible machines, they offer the same machine types and options as regular compute instances, but they last only after 24 hours and they can be taken away whenever somebody else comes along and offers a new compute needs for them. So, if your applications are fault tolerant and Hadoop applications are, then preemptable instances can reduce your compute engine costs significantly. Preemptible VMs are up to 80% cheaper than regular instances. The pricing is fixed, you get an 80% discount. But just like autoscaling, preemptible VMs work when your workload can function without the data being stored on the cluster!!!!
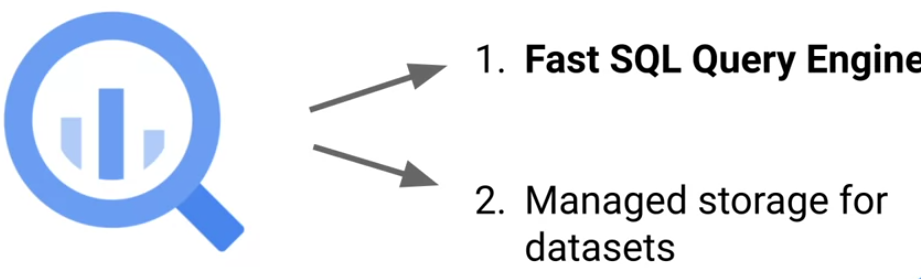
Big Query
- BigQuery is actually two services in one, a fast SQL Query Engine and fully managed data storage for loading and storing your datasets
The storage service and the query service work
together to internally organize the data to make your queries run
efficiently on terabytes and petabytes.

The storage service automatically manages the data that you ingest into the platform. Data is contained within a project in what are called datasets, which would have zero to many tables or views. The tables are stored as highly compressed columns.Each column of that table highly compressed in Google's internal Colossus file system, which provides durability and global availability. All the data stored here is only accessible to you and your project team as governed by your access policy. The storage service can do both bulk data ingestion and streaming data ingestion via the API. For streaming the max row size for a streaming insert is one megabyte and the maximum throughput is 100,000 records per second per project.
BigQuery manages the storage and the metadata for your dataset, automatically replicated, backed up and set up to auto scale for your query needs The query service runs interactive or batch queries that are submitted through the console, the BigQuery web UI, the BQ command-line tool, or via the REST API. There are BigQuery connectors to other services such as Cloud Dataproc and Cloud Dataflow, which simplify creating those complex workflows between BigQuery and other GCP data processing services. The query service can also run query jobs and data contained in other locations You can run queries on tables that are a CSV file, for example, that are hosted somewhere else in Cloud storage. Native BigQuery storage is the fastest.
- Serverless service meaning that's fully managed. So don't have to worry about how BigQuery stores data on disk or how it autoscales machines for large queries.
- BigQuery is designed to be an easy-to-use data warehouse.
- BigQuery's default pricing model is pay as you go. Pay for the number of bytes of data that your query processes and any other permanent data that's stored inside of BigQuery. Automatic caching of query results: don't end up paying for the same query returning the same data twice.
- Data in BigQuery is encrypted at rest by default.
- Controlling access to your data can be as granular as specific columns, say any column tag with PII (Personally Identifiable Information) or specific rows
- BigQuery works in tandem with Cloud IAM to set these roles and permissions at a project level, and then inherited down to the BigQuery level.
- BigQuery as both a data warehouse and an Advanced Query Engine is foundational for your AI and ML workloads.It's common for data analysts, engineers, and data scientists to use BigQuery to store, transform, and then feed those large datasets directly into your ML models.
- Write ML models directly in BigQuery using SQL.
 It stores all the incoming data from the left and allows you to do your analysis and your model-building.
It stores all the incoming data from the left and allows you to do your analysis and your model-building.

Cloud Dataprep
After your transformation recipe is complete, when you run a Cloud Dataprep job, it farms out the work to Cloud Dataflow which handles the actual processing of your data pipeline at scale. The main advantage to Cloud Dataprep is for teams want to use a UI for data exploration, and want to spend minimal time coding to build their pipelines. Lastly, with Dataprep you can schedule your pipeline to run at regular preset intervals. But, if you prefer to do all of your SQL and exploration work inside of BigQuery, you can also now use SQL to setup scheduled queries by using the @run_time parameter, or the query scheduler and the BigQuery UI.
Data security
So your insights are only shared with those people who should actually
have access to see your data. As you see here in this table, BigQuery inherits data security roles that you and your teams set up in Cloud IAM.
 Keep in mind that default access datasets can be overridden on a per dataset basis. Beyond Cloud IAM, you can also set up very granular controls over your columns and rows of data in BigQuery using the new data catalog service
and some of the advanced features in BigQuery, such as authorized views.
Keep in mind that default access datasets can be overridden on a per dataset basis. Beyond Cloud IAM, you can also set up very granular controls over your columns and rows of data in BigQuery using the new data catalog service
and some of the advanced features in BigQuery, such as authorized views.
- Dataset users should have the minimum permission needed for their role.
- use separate projects or datasets for different environments (Dev, QA, PRD)
- Audit roles periodically Data Access Policy for your organization, and it should specify how and when and why data should be shared, and with whom.
ML using SQL with BigQuery
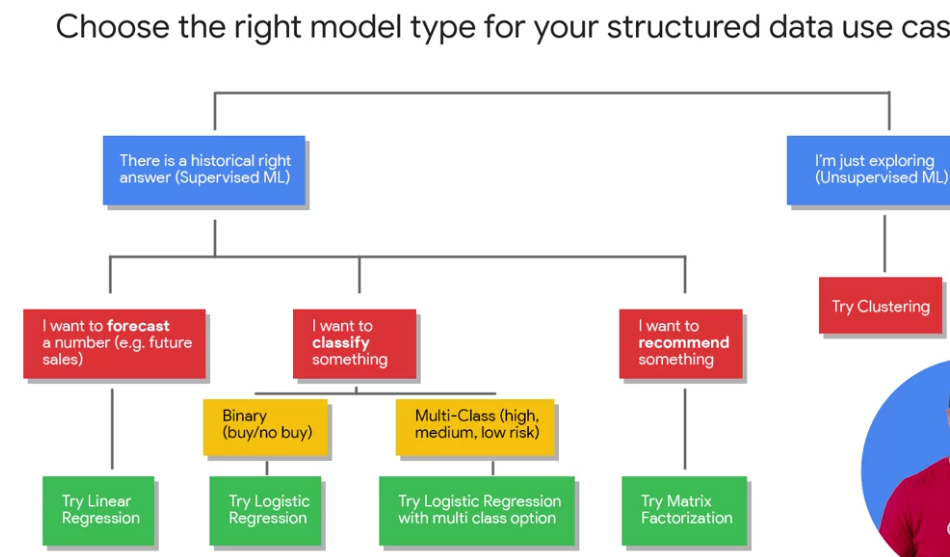 Look at the type of label or special column of data that you're predicting.
Generally, if it's a numeric datatype ==> forecasting
String value ==> classification
This row is either in this class or this other class, two classes or more ==> multi-class classification
Look at the type of label or special column of data that you're predicting.
Generally, if it's a numeric datatype ==> forecasting
String value ==> classification
This row is either in this class or this other class, two classes or more ==> multi-class classification
ML benchmark is the performance threshold that you're willing to accept from your model before you even allow it to be near your production data. It's critical that you set your benchmark before you train your model. So you can really be truly objective in your decision making to use the model or not.

The End -to_end BQML Process

- Create model

Inspect the model Weights

Evaluate the model

Make batch predictions with ML.PREDICT

BQML Cheatsheet

