2.0 KiB
2.0 KiB
| title | updated | created |
|---|---|---|
| Flink | 2022-05-24 19:01:38Z | 2022-05-24 18:44:47Z |
Stateful Computations over Data Streams
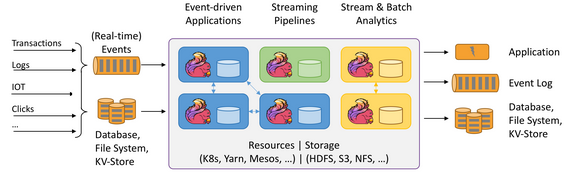
Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams. Flink has been designed to run in all common cluster environments, perform computations at in-memory speed and at any scale.
Streaming use cases
- Event-driven Applications
- Stream & Batch Analytics
- Data Pipelines & ETL
Guaranteed correctness
- Exactly-once state consistency
- Event-time processing
- Sophisticated late data handling
Layered APIs
- SQL on Stream & Batch Data
- DataStream API & DataSet API
- ProcessFunction (Time & State)
Excellent Performance
- Low latency
- High throughput
- In-Memory computing
Scales to any use case
- Scale-out architecture
- Support for very large state
- Incremental check-pointing
Data can be processed as unbounded or bounded streams.
- Unbounded streams have a start but no defined end. They do not terminate and provide data as it is generated. Unbounded streams must be continuously processed, i.e., events must be promptly handled after they have been ingested. It is not possible to wait for all input data to arrive because the input is unbounded and will not be complete at any point in time. Processing unbounded data often requires that events are ingested in a specific order, such as the order in which events occurred, to be able to reason about result completeness.
- Bounded streams have a defined start and end. Bounded streams can be processed by ingesting all data before performing any computations. Ordered ingestion is not required to process bounded streams because a bounded data set can always be sorted. Processing of bounded streams is also known as batch processing.