8.8 KiB
| title | updated | created | latitude | longitude | altitude |
|---|---|---|---|---|---|
| 2 Intro GC | 2021-09-06 19:07:42Z | 2021-09-06 07:30:13Z | 52.09370000 | 6.72510000 | 0.0000 |
06/09/2021 11:49
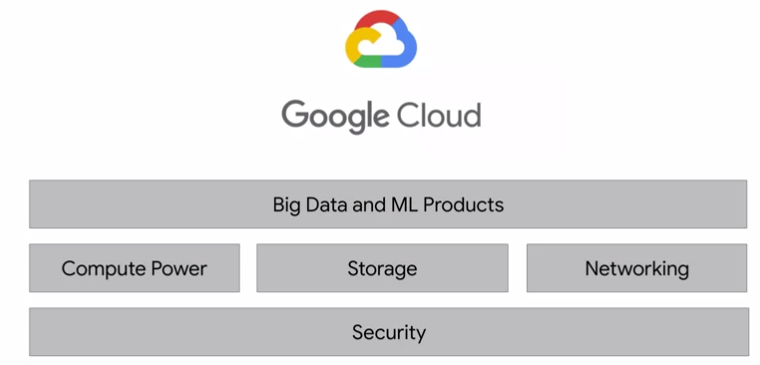
Google Cloud Platform (GCP) Infrastructure
 [https://cloud.google.com/video-intelligence]
[https://cloud.google.com/video-intelligence]
 No will not save us. Increase of computer power has decreased dramaticly, because of fundamental fysic limitations.
One solution is to limit the power consumption of a chip, and you can do that by building Application-Specific Chips or ASICs
No will not save us. Increase of computer power has decreased dramaticly, because of fundamental fysic limitations.
One solution is to limit the power consumption of a chip, and you can do that by building Application-Specific Chips or ASICs
 The Tensor Processing Unit or TPU is an ASIC specifically optimized for ML. It has more memory and a faster processor for ML workloads than traditional CPUs or GPUs.
ML model training and future engineering is one of the most time-consuming parts of any machine learning project
The Tensor Processing Unit or TPU is an ASIC specifically optimized for ML. It has more memory and a faster processor for ML workloads than traditional CPUs or GPUs.
ML model training and future engineering is one of the most time-consuming parts of any machine learning project
Elastic Storage with Google Cloud Storage
Storage and Ciomputer Power (VM) are sepearated and independent from each other. This makes cloud computing different from desktop computing.
Create Cloud Storage:
- through UI (browser)
- CLI: gsutil mb -p [PROJECT NAME] -c [STORAGE CLASS] -l [BUCKET LOCATION] gs://[BUCKET NAME]/
mb : make bucket
 All classes have multi-region, dual-region, and region location options. They differ based on the access speed and the cost.
For data analysis workloads, it's common to use a standard storage bucket within a region for staging your data. Why do I say within a region? That's because you need the data to be available to your data processing computing resources, and these will often be within a single region. Co-locating your resources this way maximizes the performance for data-intensive computations and could reduce network charges.
l : EUROPE-WEST4
Bucket names have to be globally unique, so you can use that project ID as a unique name for your bucket.
All classes have multi-region, dual-region, and region location options. They differ based on the access speed and the cost.
For data analysis workloads, it's common to use a standard storage bucket within a region for staging your data. Why do I say within a region? That's because you need the data to be available to your data processing computing resources, and these will often be within a single region. Co-locating your resources this way maximizes the performance for data-intensive computations and could reduce network charges.
l : EUROPE-WEST4
Bucket names have to be globally unique, so you can use that project ID as a unique name for your bucket.
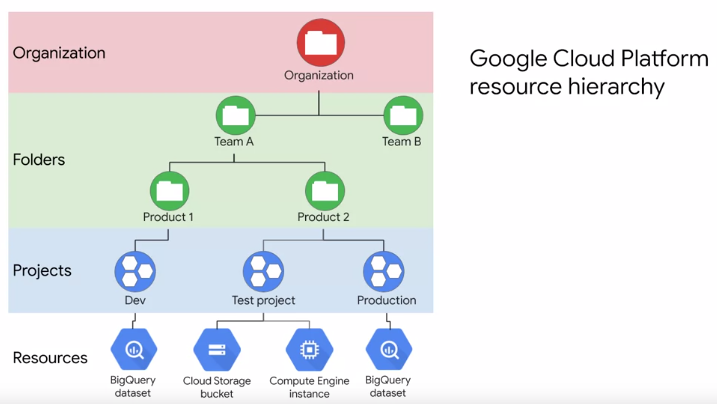
But what's a project and organisation?
A project is a base-level organizing entity for creating and using resources and services for managing billing, APIs, and permissions. Zones and regions physically organize the GCP resources you use, whereas projects logically organize them. Projects can be created, managed, deleted, even recovered from accidental deletions.
Folders are another logical grouping you can have for collections of projects. Having an organization is required to use folders. What's an organization? The organization is a root node of the entire GCP hierarchy. While it's not required, an organization is quite useful because it allows you to set policies that apply throughout your enterprise to all the projects and all the folders that are created in your enterprise. Cloud Identity and Access Management, also called IM or IAM, lets you fine-tune access control to all the GCP resources you use.
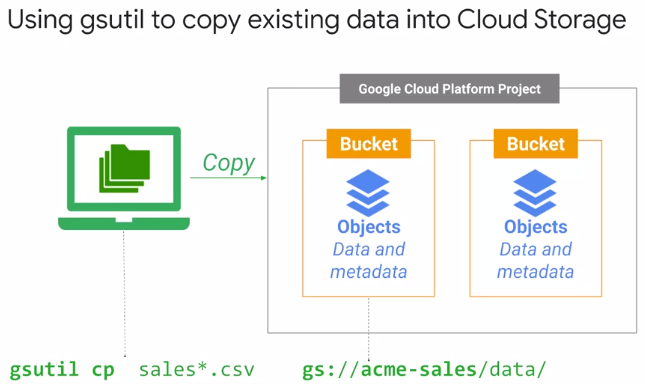
Moving data around use gsutil. Locally and in the cloud
Networking
Google's data centers around the world are interconnected by this private full duplex Google Jupiter network. The petabit bisectional bandwidth and separation of compute and storage. No need to do everything on a single machine or even a single cluster of machines with their own dedicated storage => fast-enough network. Locality within the cluster is not important. This is where Edge points of presence: Google's Network, interconnects with the public Internet at more than 90 internet exchanges and more than 100 points of presence worldwide. Google's Edge caching network places content close to end-users to minimize latency.
Security: On-premise vs Cloud-native

Communications over the internet to our public cloud services are encrypted in transit
- In-transit encryption
- Multiple layers of security
- Backed by Google security eq protect agains DoS-attacks
Stored data is automatically encrypted at rest and distributed for availability and reliability. eg BigQuery:
- BigQuery table data encrypted with keys (and keys are also encrypted) and provides own defined encryption keys.
- Monitor and flag queries for anomalous behavior
- limit data access with autorized views
Big data and ML products

GFS Google File System to handle sharding and storing petabytes of data at scale. MapReduce: manage large-scale data processing across large clusters of commodity servers. Automatically parallelized and executed on a large cluster of these commodity machines. Disadvantage: developers have to write code to manage all of the infrastructure of commodity servers. (Apache Hadoop: now used in many industries for a huge variety of tasks that all share the common theme of volume, velocity and variety of structured, and unstructured data) Bigtable: solved problem of recording and retrieving millions of streaming user actions with high throughput (inspiration for Hbase or MongoDB) Dremel took a new approach to big data processing where Dremel breaks data into small chunks called shards, and compresses them into a columnar format across distributed storage. It then uses a query optimizer to farm out tasks between the many shards of data and the Google data centers full of commodity hardware to process a query in parallel and deliver the results. The big leap forward here was that the service, automanagers data imbalances, and communications between workers, and auto-scales to meet different query demands, and as you will soon see, Dremel became the query engine behind BigQuery. Colossus: next-generation distributed data store. Spanner as a planet scale relational database. Flume and Millwheel for data pipelines. Pub/Sub for messaging. TensorFlow for machine learning. TPU (Hardware).
Google Cloud Public Datasets
Facilitate access to high-demand public datasets, hosted in n BigQuery and Google Cloud Storage. Datasets
Choosing the right approach
Computer Engine is one instance is Infrastructure as an Service (IAAS) Maximum flexibility managed by user.
Google Kubernetes Engine (GKE) is a cluster of engines running containers Containarization is packing code, highly portable and uses resources efficiently. GKE is an orchestrator
App Engine: Platform a an Service (PAAS) Use for long living applications and can autoscale.
Cloud Functions: Serverless environment (*FAAS) Executes code in response to events.

What you can do with Google Cloud
Google Customers solutions For Products and Solutions, filter on big data analytics and also on machine learning. Select a customer use case that interests you, then answer these three questions.
- what were the barriers or challenges the customer faced? The challenges are important, you want to understand what they were.
- how were these challenges solved with a cloud solution? What products did they use?
- what was the business impact?
Example Architucture
Key roles in a data-driven organization
Data engineers to build the pipelines and get you clean data. Decision makers, to decide how deep you want to invest in a data-driven opportunity while weighing the benefits for the organization. Analysts, to explore the data for insights and potential relationships that could be useful as features in a machine learning model. Statisticians, to help make your data-inspired decisions become true data-driven decisions, with their added rigor. Applied machine learning engineers, who have real-world experience building production machine learning models from the latest and best information and research by the researchers. Data scientists, who have the mastery over analysis, statistics, and machine learning. Analytics managers to lead the team. Social scientists and ethicists to ensure that the quantitative impact is there for your project and, it's the right thing to do. A single person might have a combination of these roles, but this depends on the size of your organization.