7.6 KiB
| title | updated | created | latitude | longitude | altitude |
|---|---|---|---|---|---|
| WK2 Data Lakes | 2021-09-19 15:15:03Z | 2021-09-19 10:18:20Z | 52.09370000 | 6.72510000 | 0.0000 |
Introduction to Data Lakes

Data sources: originating system or systems that are the source of all of your data Data sinks: build those reliable ways of retrieving and storing that data
The first line of defense in an enterprise data environment is your data lake variety of formats, volume, and velocity
Data pipelines: doing the transformations and processing
Orchestration layer: coordinate efforts between many of the different components at a regular or an event driven cadence. (Apache airflow)
It's so important to first understand what you want to do first, and then finding which of the solutions best meets your needs.
Data Storage and ETL options on GCP
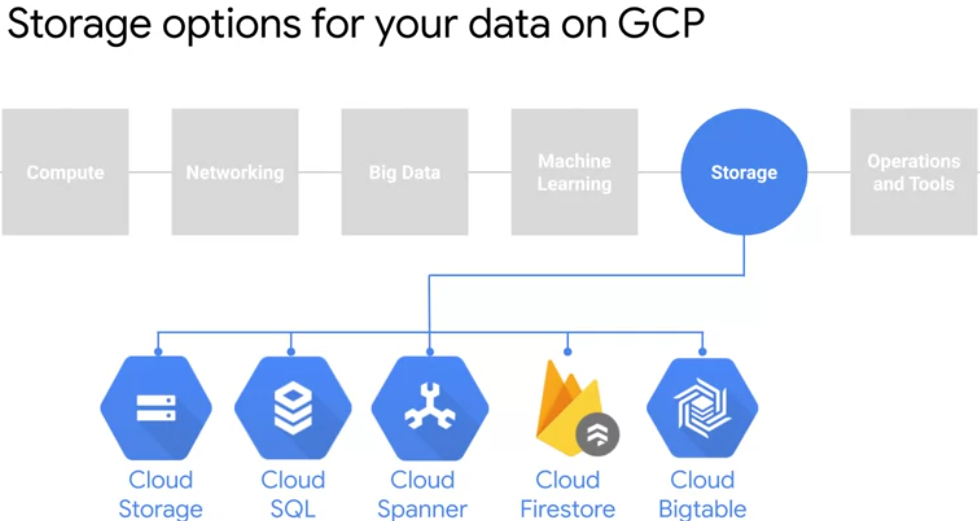
- Cloud SQL and Cloud Spanner for relational data
- Cloud Firestore and Cloud Bigtable for nosql data.
The path the data takes depends on:
- where is the data comming from
- Volume
- Where it has to go
- How much processing is needed to arrive in the sink
The method that you use to load the data into the cloud depends on how much transformation is needed from that raw data Cases:
- readily ingested (EL => Extract and Load eq avro format) Think also about federated search
- ELT => Extract Load Transform. Data is not in the right form to load into the sink. Volume is not big. eq use SQL to do the transformation: select from source and insert into the destination.
- ETL => Extract Transform Load. Transformation is essential or reduces the volume significant before importing into the cloud.
Building a Data Lake using Cloud Storage
Google Cloud Storage:
- strong persistant
- share globally
- encrypted
- controlled and private if needed
- moderate latency and high troughput
- relative inexpensive
- Object store: binary objects regartless of what the data is containt in the objects
- in some extent it has system compatibilities (copy out/in of objects as it where files) Cloud storage uses the bucket name and the object name to simulate a file system
Use cases:
- archive data
- save state of application when shutdown instance
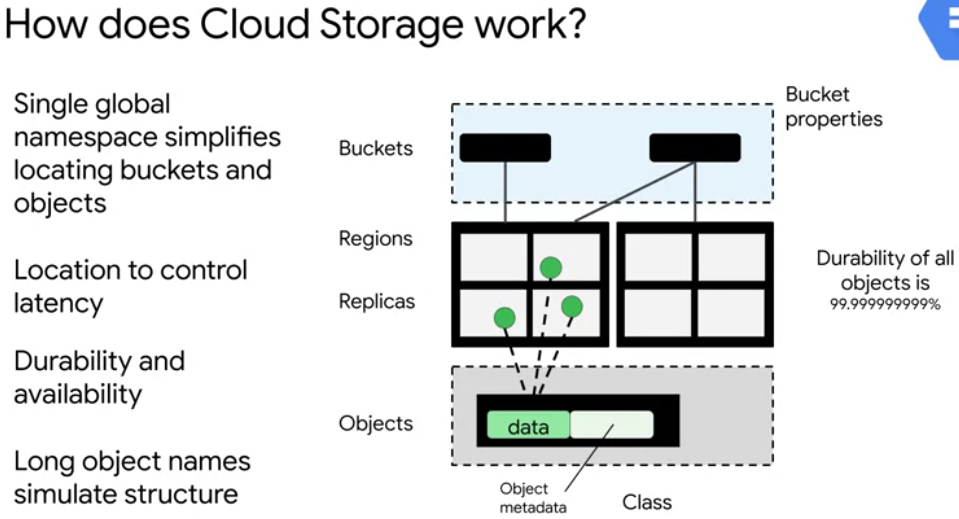 The two main entities in cloud storage are buckets and
objects
The two main entities in cloud storage are buckets and
objects
- buckets are containers which hold objects
- identified in a single globally unique name space (no one else can use that name. till deletion and name is released)
- associated with a particular region or multiple regions
- For a single region bucket the objects are replicated across zones within that one region (low-latency)
- multiple requesters could be retrieving the objects at the same time from different replicas (high throughput)
- objects exist inside of those buckets and not apart from them.
- When an object is stored, cloud storage replicates that object, it'll then monitor the replicas and if one of them is lost or corrupted it'll replace it automatically with a fresh copy. (high durability)
- stored with metadata. Used for access control, compression, encryption and lifecycle management of those objects and buckets.
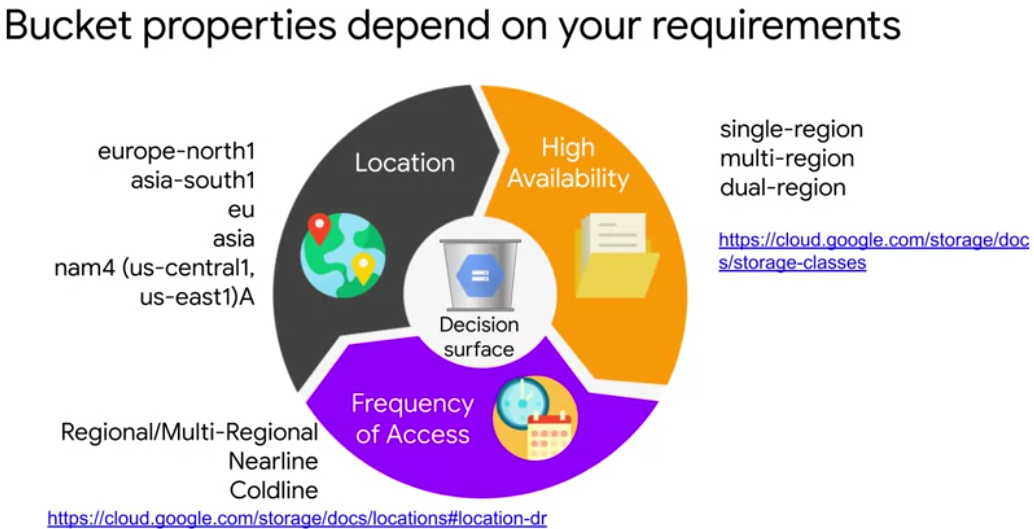
- the location of that bucket, location is set when a bucket is created and it can never be changed.
- have the location to be a dual region bucket? Select one region and the data will be replicated to multiple zones within this region
- need to determine how often to access or change your data. Storage classes: archival storage, backups or disaster recovery
Cloud storage uses the bucket name and the object name to simulate a file system
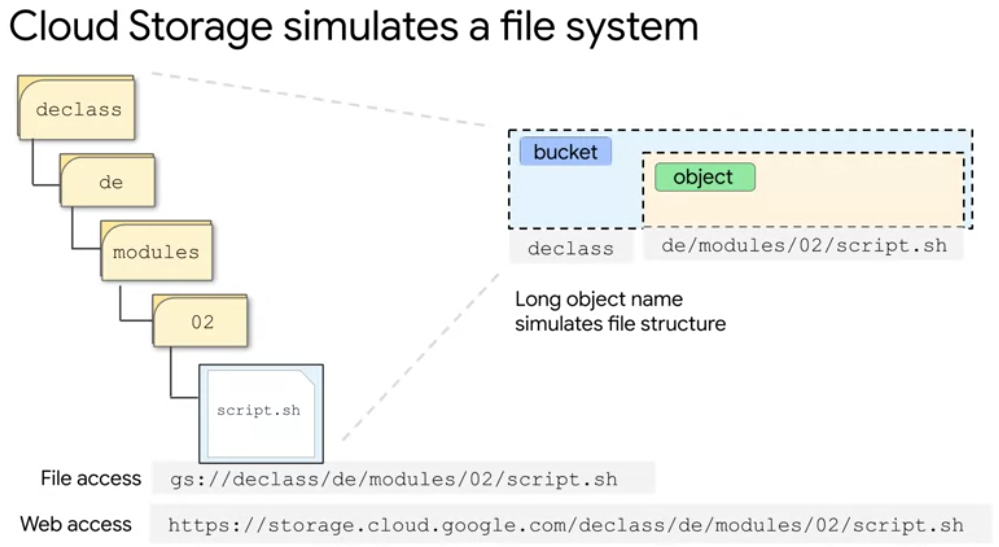 In example:
bucket name is declass
object name is de/modules/O2/script.sh
the forward slashes are just characters in the name
In example:
bucket name is declass
object name is de/modules/O2/script.sh
the forward slashes are just characters in the name
A best practice is to avoid the use of sensitive information as part of bucket names, because bucket names are in a global namespace.

Securing Cloud Storage
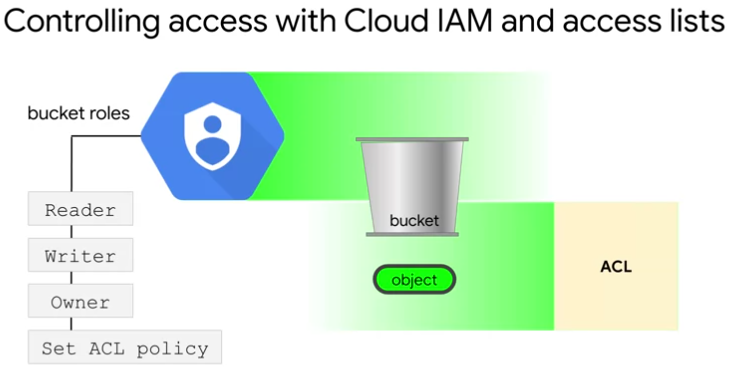
- IAM is set at the bucket level.
- provides project roles and bucket roles:
- bucket reader
- bucket writer
- bucket owner.
In the ability to create and delete buckets and to set IAM policy, is a project level role. The ability to create or change access control lists is an IAM bucket role. Custom roles are also available.
- Access control lists (ACL)
- applied at the bucket level or to individual objects. So it provides more fine-grained access control. Access lists are currently enabled by default
All data in Google Cloud is encrypted at rest and in transit and there is no way to turn off the encryption.

Which data encryption option you use generally depend on your business, legal and regulatory requirements.
Two levels of encryption: data is encrypted using a data encryption key, and then the data encryption key itself is then encrypted using a key encryption key or a KEK. These KEKs are automatically rotated on a schedule that use the current KEK stored in Cloud KMS, or the Key management Service
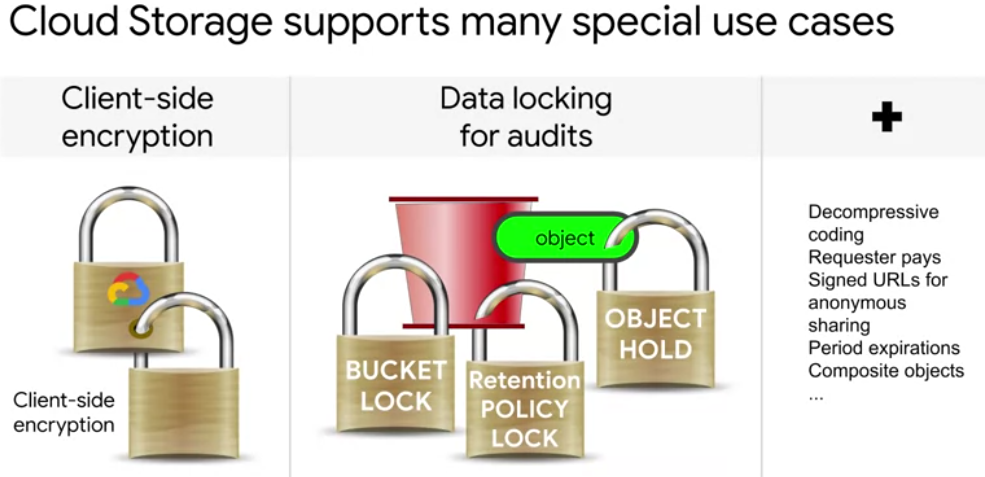 The fourth encryption option is client-side encryption. Client-side encryption simply means that you've encrypted the data before it's uploaded and then you have to decrypt the data yourself before it's used. Google Cloud storage still performs GMEK, CMEK, or CSEK encryption on the object.
The fourth encryption option is client-side encryption. Client-side encryption simply means that you've encrypted the data before it's uploaded and then you have to decrypt the data yourself before it's used. Google Cloud storage still performs GMEK, CMEK, or CSEK encryption on the object.
Data locking is different from encryption. Where encryption prevents somebody from understanding the data, locking prevents them from modifying the data.
Storing All Sorts of Data Types
Cloud Storage not for transactional data or for Analytics unstructured data.
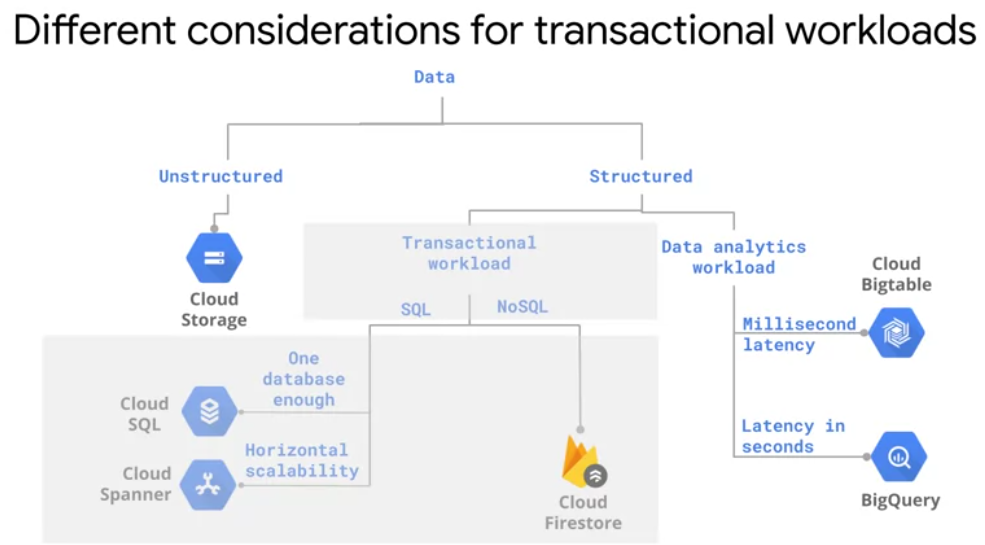
 Online Transaction Processing or OLTP
Online Analytical Processing or OLAP
Online Transaction Processing or OLTP
Online Analytical Processing or OLAP

Storing Relational Data in the Cloud
Cloud SQL:
- managed service for third-party RDBMSs (MySQL, SQL server, PostgresSQL)
- cost effective
- default choice for those OLTP
- fully managed
Cloud Spanner:
- globally distributed database. Updates from applications running in different geographic regions.
- database is too big to fit in a single Cloud SQL instance
Cloud Bigtable
- really high throughput inserts, like more than a million rows per second or all sure low latency on the order of milliseconds, consider
Difference between fully managed and serverless:
By fully managed, we mean that the service runs on a hardware that you can control.Dataproc is fully mananged
A serverless product that's just like an API that you're calling. BigQuery and Cloud Storage is serverless
