4.3 KiB
Telegram bidezko galdera-erantzun sistema
- Sarrera
- Erlazionatutako lanak
- Sistema
- Telegram zerbitzura txertapena
- Datuak
- Emaitzak
- Analisia
- Ondorioak
- Erreferentziak
Sarrera
Hemengo hau, Sare Errekurrenteetan oinarritutako sistema bat, filmetako azpitituluetaz baliatuz, Telegramen elkarriketak izateko ahalbidetzea helburu duen lan bat da.
Erlazionatutako lanak
Lan hau seq2seq sare neuronalen arkitektura motan oinarrituta dago.
Eredu mota hau Google-n hasi zen erabiltzen lehen aldiz 2014-an (Sutskever et al.).
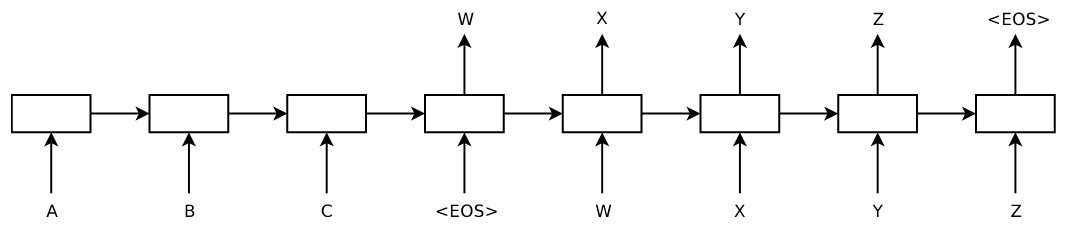

Kodetzaile bat dago hasieran, eta bukaeran dekodetzaile bat.
Eskoletako materialetatik hartutako irudi hauetan ikusten den bezala, sarrera kodeazaileari ematen zaio eta hitz bakoitza aurrekoarekin lotuta kodetzen joaten da, ondoren, emaitza dekodetzaileari eskaintzeko bestelako hitz batzuk lortuz.
Sistema
Sistema honek aipatutako seq2seq eredua erabiltzen du, baina, dekodetzailearen helburua, kasu honetan, erantzun bat itzultzea da.
Horretarako, GRU sare neuronal errekurrente eredua erabili da kodetzaile eta dekodetzaile bat egiteko. Gainera, atentzio sistema bat erabili da.
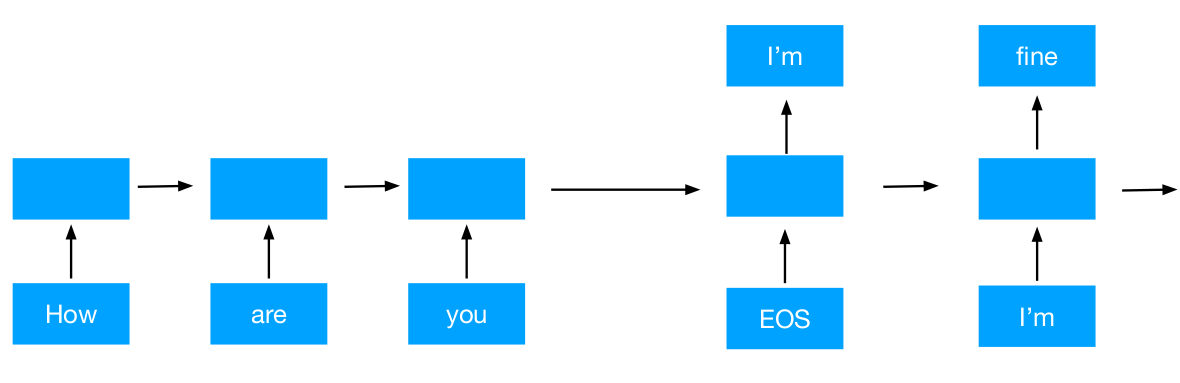
Sistema hau Jon Anderrek eskainitako eta spro/practical-pytorch biltegian oinarritutako kodean dago oinarrituta. Aipatutako, ezaugarri guztiak dagoeneko oinarrizko sistema honek bazituen. Ordea, beste zenbat aldaketa egin dizkiot emaitzak hobetzeko.
Hobekuntzak
Erantzun motzen aurkako neurriak
Sistema honek ematen zituen emaitzak oso laburrak ziren, beti Bai/Ez erantzuten baitzuen, seguruenik elkerrizketetan gehien azaltzen diren hitzak direlako.
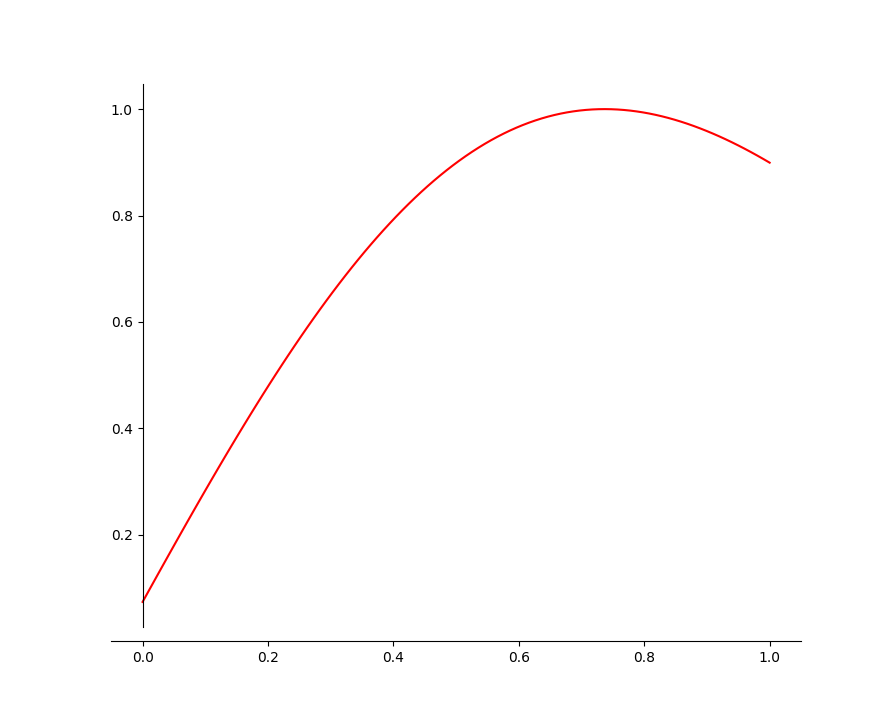
Ondorioz, Brevity Penalization (BP) balio baten bidez baldintzatu dut galera funtzioa. Ordea, BP huts bat erabilita, eredua beti emaitza luzeenak saiatzen da ematen, eta horrek oso emaitza txarrak sortzea eragiten du.
Horregatik, BP balioa Rayleigh distribuzioko kurba batean aplikatzen da, erantzun errealaren luzera izan ordez helburu, horren balio antzeko gertu bat izango da.
Tokenizatzailea
Oinarrizko ereduan tokenizatzailea, ingelesezkoa zen, ordea, euskarazko azpitituluak nahi genituen erabili entrenamendurako, ondorioz, SpaCy-k eskainitako euskarazko tokenizatzaile oso sinple bat erabili da.
Telegram zerbitzura txertapena
Ez dut arazorik izan. https://github.com/python-telegram-bot/python-telegram-bot API-aren inplementazioa erabili dut.
Datuak
Entrenamendurako erabilitako datuak OpenSubtitles datubaseko euskarazko azpitituluak erabili dira. Baina azpititulu hauek zarataz daude beteta. Ondorioz, lehenik, garbiketa bat egin da.
Hasiera bateko garbiketa
Hasieran, helburu bakarra elkarrizketetan jartzen diren hasierako "-" karaktereak ezabatzea zen, ondorioz agindu oso sinple bat erabiltzea pentsatu nuen:
sed -E 's|^- ?||' < eu.txt | paste - -Baina gero konturatu nintzen, azpitituluetan zegoen zarata askoz ere larriagoa zela eta Shell gidoia handitzen joan nintzen orain erabiltzen dudana arte.
Garbiketa
Ondorengoa da egindako garbiketa:
- Lerroen hasierako "-" karaktereak ezabatu.
- " karaktereaz hasten diren lerroak batu esaldi berberekoak direlako adierazten delako.
- Batu komaz bukatzen diren lerroak, esaldi berberekoak direlako.
Adibideak
"Gaur pergaminoa aurkitu dut Karswellek emandako egitarauaren barruan".
"Sinbolo errunikoak zeuzkan marraztuta".-Zu ez zaude ezkonduta?
-Ez.
-Ama!
-Izozkia gustatzen zaizu?
-Bai, asko.
-Zatoz.Egon pixka batean, mamarroa oraintxe dator eta, bere aiztoa eta guzti,
zu txiki-txiki egiteko.Emaitzak
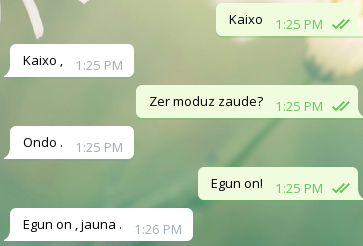
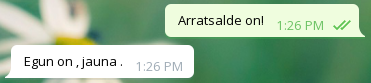
Onak

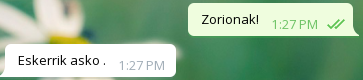
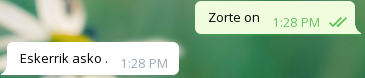
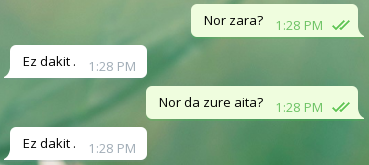
Txarrak
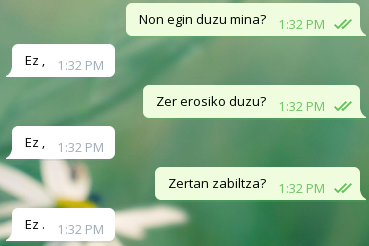
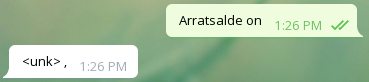
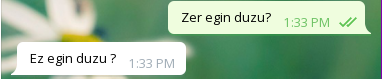
Analisia
Orokorrean, agurrei ondo erantzuten die, baina bestelako galderei Bai edo Ez erantzuten du ia beti, eta beste zenbaitetan ez daki zer erantzun.
Ondorioak
Transformer bat erabili badirudiela emaitz ahobeagoak ematen dituela.
Kontuan dago hartu beharra, azpitituluen datubasearen kalitatea sekulako botila-lepoa eragiten duela.
Erreferentziak
- Sutskever, Ilya; Vinyals, Oriol; Le, Quoc Viet (2014). "Sequence to sequence learning with neural networks"